 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Potential of Generative AI for the World Wide Web
Oct 26, 2023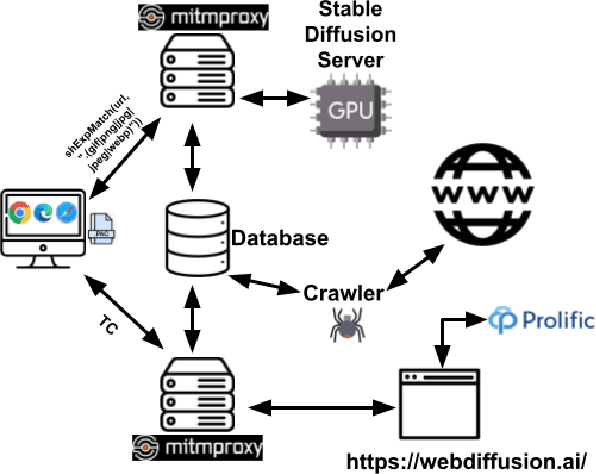



Generative Artificial Intelligence (AI) is a cutting-edge technology capable of producing text, images, and various media content leveraging generative models and user prompts. Between 2022 and 2023, generative AI surged in popularity with a plethora of applications spanning from AI-powered movies to chatbots. In this paper, we delve into the potential of generative AI within the realm of the World Wide Web, specifically focusing on image generation. Web developers already harness generative AI to help crafting text and images, while Web browsers might use it in the future to locally generate images for tasks like repairing broken webpages, conserving bandwidth, and enhancing privacy. To explore this research area, we have developed WebDiffusion, a tool that allows to simulate a Web powered by stable diffusion, a popular text-to-image model, from both a client and server perspective. WebDiffusion further supports crowdsourcing of user opinions, which we use to evaluate the quality and accuracy of 409 AI-generated images sourced from 60 webpages. Our findings suggest that generative AI is already capable of producing pertinent and high-quality Web images, even without requiring Web designers to manually input prompts, just by leveraging contextual information available within the webpages. However, we acknowledge that direct in-browser image generation remains a challenge, as only highly powerful GPUs, such as the A40 and A100, can (partially) compete with classic image downloads. Nevertheless, this approach could be valuable for a subset of the images, for example when fixing broken webpages or handling highly private content.
Decoupling Learning Rates Using Empirical Bayes Priors
Feb 04, 2020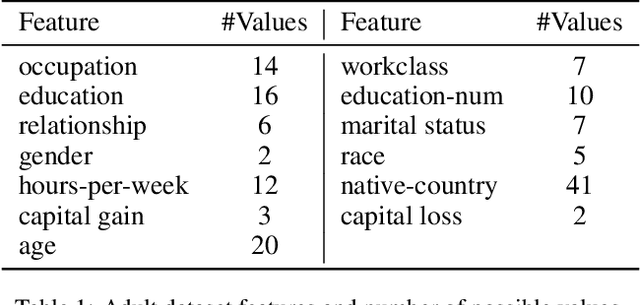
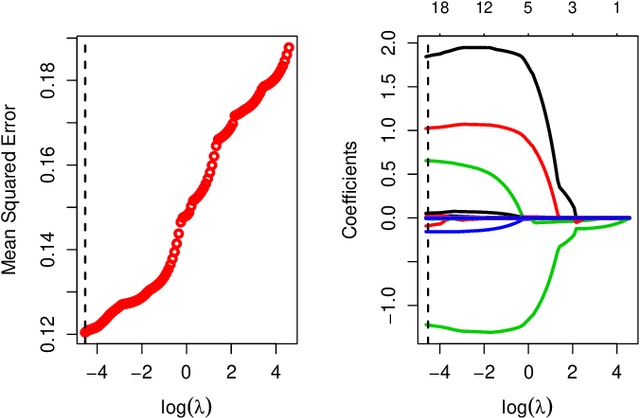
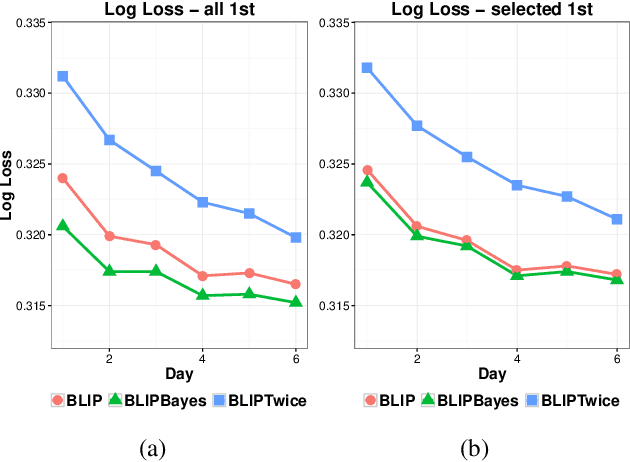
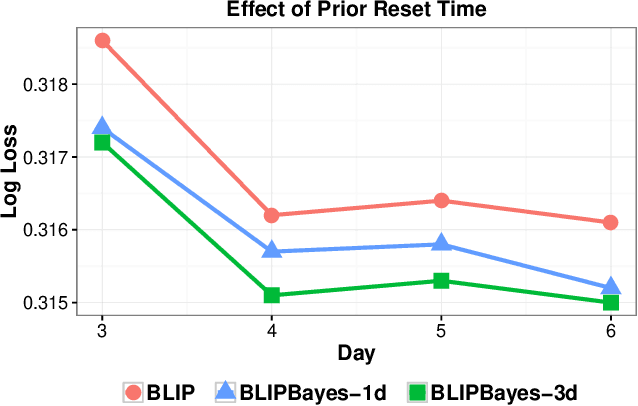
In this work, we propose an Empirical Bayes approach to decouple the learning rates of first order and second order features (or any other feature grouping) in a Generalized Linear Model. Such needs arise in small-batch or low-traffic use-cases. As the first order features are likely to have a more pronounced effect on the outcome, focusing on learning first order weights first is likely to improve performance and convergence time. Our Empirical Bayes method clamps features in each group together and uses the observed data for the deployed model to empirically compute a hierarchical prior in hindsight. We apply our method to a standard classification setting, as well as a contextual bandit setting in an Amazon production system. Both during simulations and live experiments, our method shows marked improvements, especially in cases of small traffic. Our findings are promising, as optimizing over sparse data is often a challenge. Furthermore, our approach can be applied to any problem instance modeled as a Bayesian framework.