 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Vehicle Plate Recognition: Multitasking Visual Language Models with VehiclePaliGemma
Dec 14, 2024



License plate recognition (LPR) involves automated systems that utilize cameras and computer vision to read vehicle license plates. Such plates collected through LPR can then be compared against databases to identify stolen vehicles, uninsured drivers, crime suspects, and more. The LPR system plays a significant role in saving time for institutions such as the police force. In the past, LPR relied heavily on Optical Character Recognition (OCR), which has been widely explored to recognize characters in images. Usually, collected plate images suffer from various limitations, including noise, blurring, weather conditions, and close characters, making the recognition complex. Existing LPR methods still require significant improvement, especially for distorted images. To fill this gap, we propose utilizing visual language models (VLMs) such as OpenAI GPT4o, Google Gemini 1.5, Google PaliGemma (Pathways Language and Image model + Gemma model), Meta Llama 3.2, Anthropic Claude 3.5 Sonnet, LLaVA, NVIDIA VILA, and moondream2 to recognize such unclear plates with close characters. This paper evaluates the VLM's capability to address the aforementioned problems. Additionally, we introduce ``VehiclePaliGemma'', a fine-tuned Open-sourced PaliGemma VLM designed to recognize plates under challenging conditions. We compared our proposed VehiclePaliGemma with state-of-the-art methods and other VLMs using a dataset of Malaysian license plates collected under complex conditions. The results indicate that VehiclePaliGemma achieved superior performance with an accuracy of 87.6\%. Moreover, it is able to predict the car's plate at a speed of 7 frames per second using A100-80GB GPU. Finally, we explored the multitasking capability of VehiclePaliGemma model to accurately identify plates containing multiple cars of various models and colors, with plates positioned and oriented in different directions.
Advancing Content Moderation: Evaluating Large Language Models for Detecting Sensitive Content Across Text, Images, and Videos
Nov 26, 2024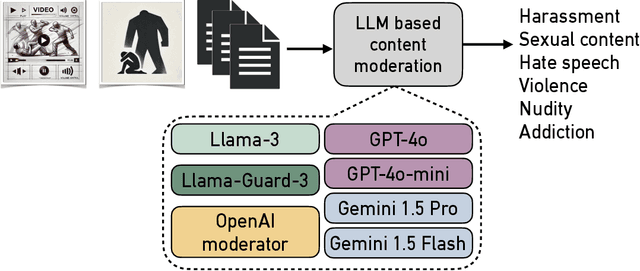
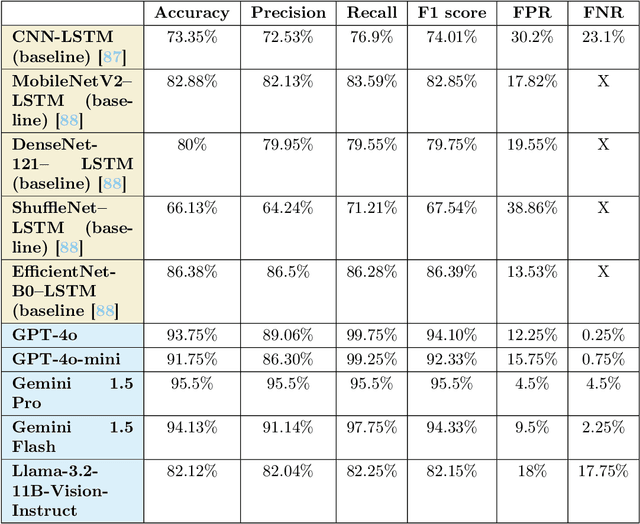
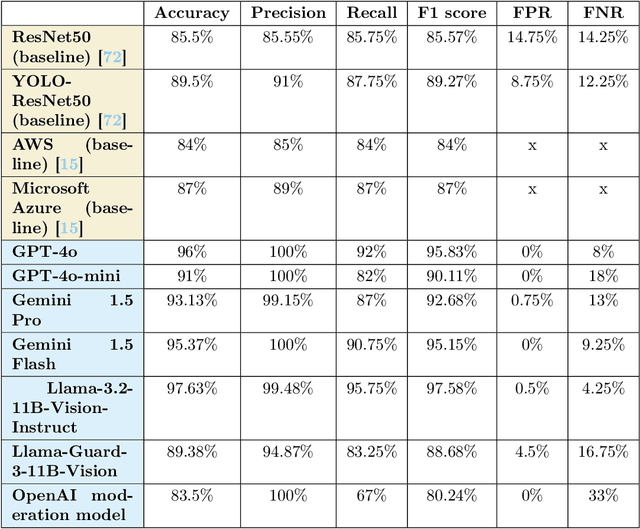
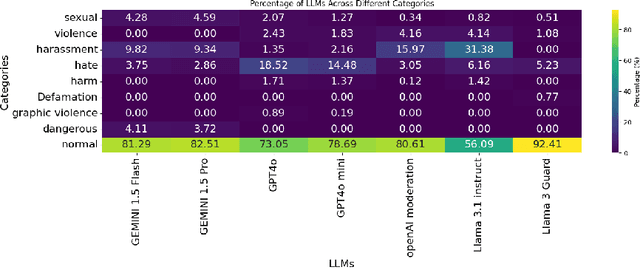
The widespread dissemination of hate speech, harassment, harmful and sexual content, and violence across websites and media platforms presents substantial challenges and provokes widespread concern among different sectors of society. Governments, educators, and parents are often at odds with media platforms about how to regulate, control, and limit the spread of such content. Technologies for detecting and censoring the media contents are a key solution to addressing these challenges. Techniques from natural language processing and computer vision have been used widely to automatically identify and filter out sensitive content such as offensive languages, violence, nudity, and addiction in both text, images, and videos, enabling platforms to enforce content policies at scale. However, existing methods still have limitations in achieving high detection accuracy with fewer false positives and false negatives. Therefore, more sophisticated algorithms for understanding the context of both text and image may open rooms for improvement in content censorship to build a more efficient censorship system. In this paper, we evaluate existing LLM-based content moderation solutions such as OpenAI moderation model and Llama-Guard3 and study their capabilities to detect sensitive contents. Additionally, we explore recent LLMs such as GPT, Gemini, and Llama in identifying inappropriate contents across media outlets. Various textual and visual datasets like X tweets, Amazon reviews, news articles, human photos, cartoons, sketches, and violence videos have been utilized for evaluation and comparison. The results demonstrate that LLMs outperform traditional techniques by achieving higher accuracy and lower false positive and false negative rates. This highlights the potential to integrate LLMs into websites, social media platforms, and video-sharing services for regulatory and content moderation purposes.
Exploring Vision Language Models for Facial Attribute Recognition: Emotion, Race, Gender, and Age
Oct 31, 2024



Technologies for recognizing facial attributes like race, gender, age, and emotion have several applications, such as surveillance, advertising content, sentiment analysis, and the study of demographic trends and social behaviors. Analyzing demographic characteristics based on images and analyzing facial expressions have several challenges due to the complexity of humans' facial attributes. Traditional approaches have employed CNNs and various other deep learning techniques, trained on extensive collections of labeled images. While these methods demonstrated effective performance, there remains potential for further enhancements. In this paper, we propose to utilize vision language models (VLMs) such as generative pre-trained transformer (GPT), GEMINI, large language and vision assistant (LLAVA), PaliGemma, and Microsoft Florence2 to recognize facial attributes such as race, gender, age, and emotion from images with human faces. Various datasets like FairFace, AffectNet, and UTKFace have been utilized to evaluate the solutions. The results show that VLMs are competitive if not superior to traditional techniques. Additionally, we propose "FaceScanPaliGemma"--a fine-tuned PaliGemma model--for race, gender, age, and emotion recognition. The results show an accuracy of 81.1%, 95.8%, 80%, and 59.4% for race, gender, age group, and emotion classification, respectively, outperforming pre-trained version of PaliGemma, other VLMs, and SotA methods. Finally, we propose "FaceScanGPT", which is a GPT-4o model to recognize the above attributes when several individuals are present in the image using a prompt engineered for a person with specific facial and/or physical attributes. The results underscore the superior multitasking capability of FaceScanGPT to detect the individual's attributes like hair cut, clothing color, postures, etc., using only a prompt to drive the detection and recognition tasks.
Localization and Classification of Parasitic Eggs in Microscopic Images Using an EfficientDet Detector
Aug 03, 2022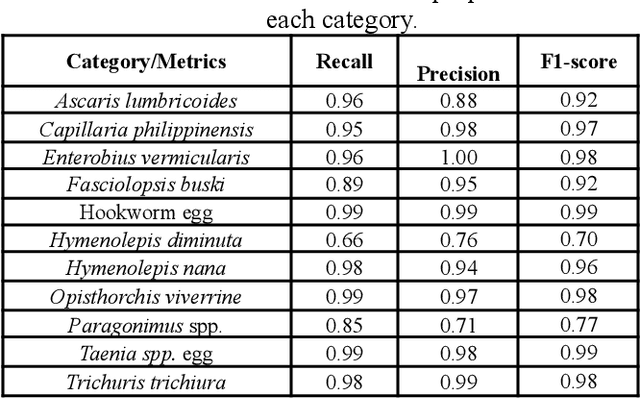
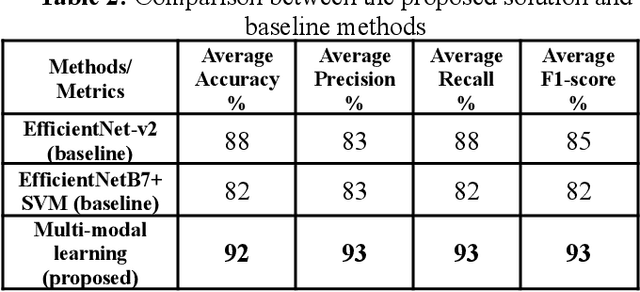
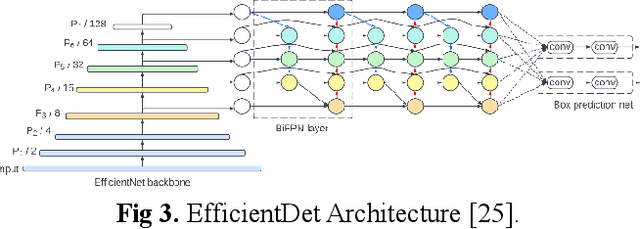
IPIs caused by protozoan and helminth parasites are among the most common infections in humans in LMICs. They are regarded as a severe public health concern, as they cause a wide array of potentially detrimental health conditions. Researchers have been developing pattern recognition techniques for the automatic identification of parasite eggs in microscopic images. Existing solutions still need improvements to reduce diagnostic errors and generate fast, efficient, and accurate results. Our paper addresses this and proposes a multi-modal learning detector to localize parasitic eggs and categorize them into 11 categories. The experiments were conducted on the novel Chula-ParasiteEgg-11 dataset that was used to train both EfficientDet model with EfficientNet-v2 backbone and EfficientNet-B7+SVM. The dataset has 11,000 microscopic training images from 11 categories. Our results show robust performance with an accuracy of 92%, and an F1 score of 93%. Additionally, the IOU distribution illustrates the high localization capability of the detector.