 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Benchmark of Histopathology Foundation Models for Kidney Histopathology
Mar 16, 2026Histopathology foundation models (HFMs), pretrained on large-scale cancer datasets, have advanced computational pathology. However, their applicability to non-cancerous chronic kidney disease remains underexplored, despite coexistence of renal pathology with malignancies such as renal cell and urothelial carcinoma. We systematically evaluate 11 publicly available HFMs across 11 kidney-specific downstream tasks spanning multiple stains (PAS, H&E, PASM, and IHC), spatial scales (tile and slide-level), task types (classification, regression, and copy detection), and clinical objectives, including detection, diagnosis, and prognosis. Tile-level performance is assessed using repeated stratified group cross-validation, while slide-level tasks are evaluated using repeated nested stratified cross-validation. Statistical significance is examined using Friedman test followed by pairwise Wilcoxon signed-rank testing with Holm-Bonferroni correction and compact letter display visualization. To promote reproducibility, we release an open-source Python package, kidney-hfm-eval, available at https://pypi.org/project/kidney-hfm-eval/ , that reproduces the evaluation pipelines. Results show moderate to strong performance on tasks driven by coarse meso-scale renal morphology, including diagnostic classification and detection of prominent structural alterations. In contrast, performance consistently declines for tasks requiring fine-grained microstructural discrimination, complex biological phenotypes, or slide-level prognostic inference, largely independent of stain type. Overall, current HFMs appear to encode predominantly static meso-scale representations and may have limited capacity to capture subtle renal pathology or prognosis-related signals. Our results highlight the need for kidney-specific, multi-stain, and multimodal foundation models to support clinically reliable decision-making in nephrology.
Advancing Content Moderation: Evaluating Large Language Models for Detecting Sensitive Content Across Text, Images, and Videos
Nov 26, 2024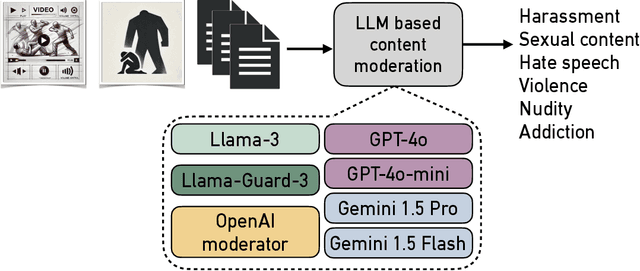
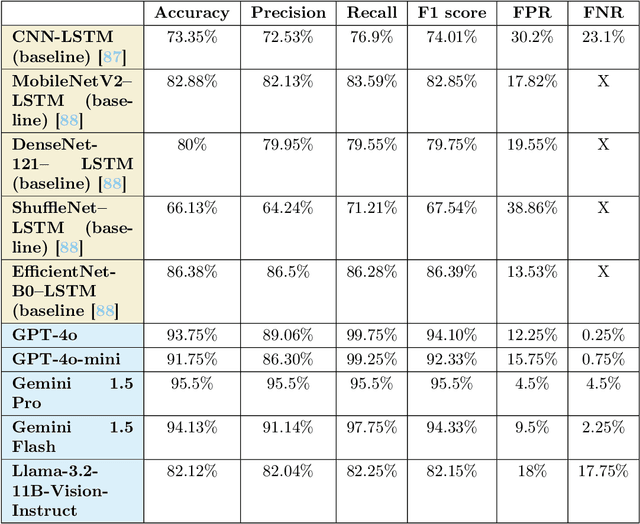
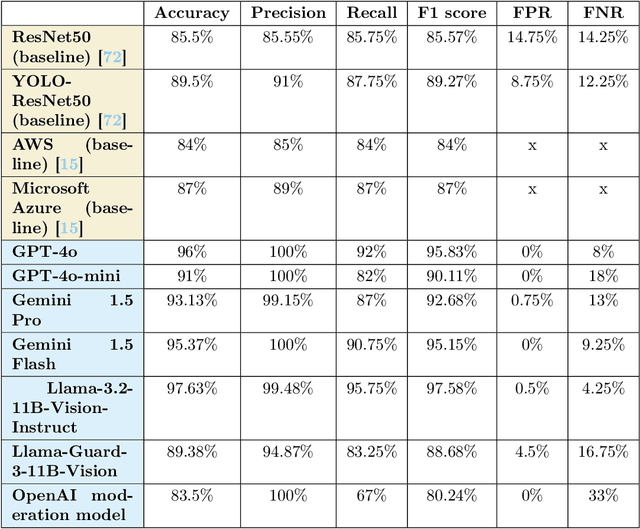
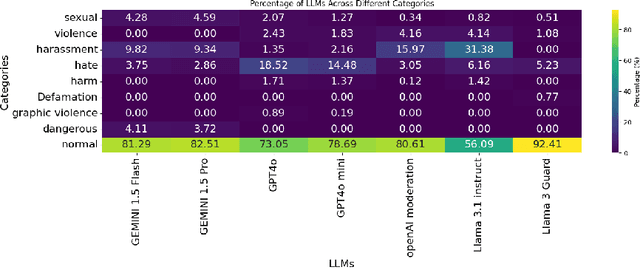
The widespread dissemination of hate speech, harassment, harmful and sexual content, and violence across websites and media platforms presents substantial challenges and provokes widespread concern among different sectors of society. Governments, educators, and parents are often at odds with media platforms about how to regulate, control, and limit the spread of such content. Technologies for detecting and censoring the media contents are a key solution to addressing these challenges. Techniques from natural language processing and computer vision have been used widely to automatically identify and filter out sensitive content such as offensive languages, violence, nudity, and addiction in both text, images, and videos, enabling platforms to enforce content policies at scale. However, existing methods still have limitations in achieving high detection accuracy with fewer false positives and false negatives. Therefore, more sophisticated algorithms for understanding the context of both text and image may open rooms for improvement in content censorship to build a more efficient censorship system. In this paper, we evaluate existing LLM-based content moderation solutions such as OpenAI moderation model and Llama-Guard3 and study their capabilities to detect sensitive contents. Additionally, we explore recent LLMs such as GPT, Gemini, and Llama in identifying inappropriate contents across media outlets. Various textual and visual datasets like X tweets, Amazon reviews, news articles, human photos, cartoons, sketches, and violence videos have been utilized for evaluation and comparison. The results demonstrate that LLMs outperform traditional techniques by achieving higher accuracy and lower false positive and false negative rates. This highlights the potential to integrate LLMs into websites, social media platforms, and video-sharing services for regulatory and content moderation purposes.
Exploring Vision Language Models for Facial Attribute Recognition: Emotion, Race, Gender, and Age
Oct 31, 2024



Technologies for recognizing facial attributes like race, gender, age, and emotion have several applications, such as surveillance, advertising content, sentiment analysis, and the study of demographic trends and social behaviors. Analyzing demographic characteristics based on images and analyzing facial expressions have several challenges due to the complexity of humans' facial attributes. Traditional approaches have employed CNNs and various other deep learning techniques, trained on extensive collections of labeled images. While these methods demonstrated effective performance, there remains potential for further enhancements. In this paper, we propose to utilize vision language models (VLMs) such as generative pre-trained transformer (GPT), GEMINI, large language and vision assistant (LLAVA), PaliGemma, and Microsoft Florence2 to recognize facial attributes such as race, gender, age, and emotion from images with human faces. Various datasets like FairFace, AffectNet, and UTKFace have been utilized to evaluate the solutions. The results show that VLMs are competitive if not superior to traditional techniques. Additionally, we propose "FaceScanPaliGemma"--a fine-tuned PaliGemma model--for race, gender, age, and emotion recognition. The results show an accuracy of 81.1%, 95.8%, 80%, and 59.4% for race, gender, age group, and emotion classification, respectively, outperforming pre-trained version of PaliGemma, other VLMs, and SotA methods. Finally, we propose "FaceScanGPT", which is a GPT-4o model to recognize the above attributes when several individuals are present in the image using a prompt engineered for a person with specific facial and/or physical attributes. The results underscore the superior multitasking capability of FaceScanGPT to detect the individual's attributes like hair cut, clothing color, postures, etc., using only a prompt to drive the detection and recognition tasks.