 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Master Key Hypothesis: Unlocking Cross-Model Capability Transfer via Linear Subspace Alignment
Apr 07, 2026We investigate whether post-trained capabilities can be transferred across models without retraining, with a focus on transfer across different model scales. We propose the Master Key Hypothesis, which states that model capabilities correspond to directions in a low-dimensional latent subspace that induce specific behaviors and are transferable across models through linear alignment. Based on this hypothesis, we introduce UNLOCK, a training-free and label-free framework that extracts a capability direction by contrasting activations between capability-present and capability-absent Source variants, aligns it with a Target model through a low-rank linear transformation, and applies it at inference time to elicit the behavior. Experiments on reasoning behaviors, including Chain-of-Thought (CoT) and mathematical reasoning, demonstrate substantial improvements across model scales without training. For example, transferring CoT reasoning from Qwen1.5-14B to Qwen1.5-7B yields an accuracy gain of 12.1% on MATH, and transferring a mathematical reasoning direction from Qwen3-4B-Base to Qwen3-14B-Base improves AGIEval Math accuracy from 61.1% to 71.3%, surpassing the 67.8% achieved by the 14B post-trained model. Our analysis shows that the success of transfer depends on the capabilities learned during pre-training, and that our intervention amplifies latent capabilities by sharpening the output distribution toward successful reasoning trajectories.
Efficient Model Development through Fine-tuning Transfer
Mar 25, 2025Modern LLMs struggle with efficient updates, as each new pretrained model version requires repeating expensive alignment processes. This challenge also applies to domain- or language-specific models, where fine-tuning on specialized data must be redone for every new base model release. In this paper, we explore the transfer of fine-tuning updates between model versions. Specifically, we derive the diff vector from one source model version, which represents the weight changes from fine-tuning, and apply it to the base model of a different target version. Through empirical evaluations on various open-weight model versions, we show that transferring diff vectors can significantly improve the target base model, often achieving performance comparable to its fine-tuned counterpart. For example, reusing the fine-tuning updates from Llama 3.0 8B leads to an absolute accuracy improvement of 10.7% on GPQA over the base Llama 3.1 8B without additional training, surpassing Llama 3.1 8B Instruct. In a multilingual model development setting, we show that this approach can significantly increase performance on target-language tasks without retraining, achieving an absolute improvement of 4.7% and 15.5% on Global MMLU for Malagasy and Turkish, respectively, compared to Llama 3.1 8B Instruct. Our controlled experiments reveal that fine-tuning transfer is most effective when the source and target models are linearly connected in the parameter space. Additionally, we demonstrate that fine-tuning transfer offers a stronger and more computationally efficient starting point for further fine-tuning. Finally, we propose an iterative recycling-then-finetuning approach for continuous model development, which improves both efficiency and effectiveness. Our findings suggest that fine-tuning transfer is a viable strategy to reduce training costs while maintaining model performance.
Adversarial Attacks on Combinatorial Multi-Armed Bandits
Oct 08, 2023We study reward poisoning attacks on Combinatorial Multi-armed Bandits (CMAB). We first provide a sufficient and necessary condition for the attackability of CMAB, which depends on the intrinsic properties of the corresponding CMAB instance such as the reward distributions of super arms and outcome distributions of base arms. Additionally, we devise an attack algorithm for attackable CMAB instances. Contrary to prior understanding of multi-armed bandits, our work reveals a surprising fact that the attackability of a specific CMAB instance also depends on whether the bandit instance is known or unknown to the adversary. This finding indicates that adversarial attacks on CMAB are difficult in practice and a general attack strategy for any CMAB instance does not exist since the environment is mostly unknown to the adversary. We validate our theoretical findings via extensive experiments on real-world CMAB applications including probabilistic maximum covering problem, online minimum spanning tree, cascading bandits for online ranking, and online shortest path.
Unified Off-Policy Learning to Rank: a Reinforcement Learning Perspective
Jun 13, 2023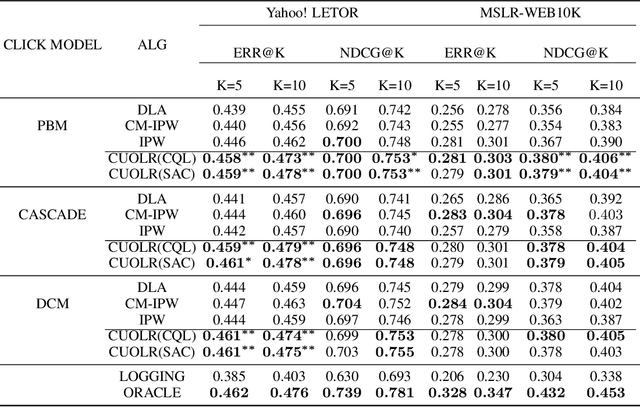
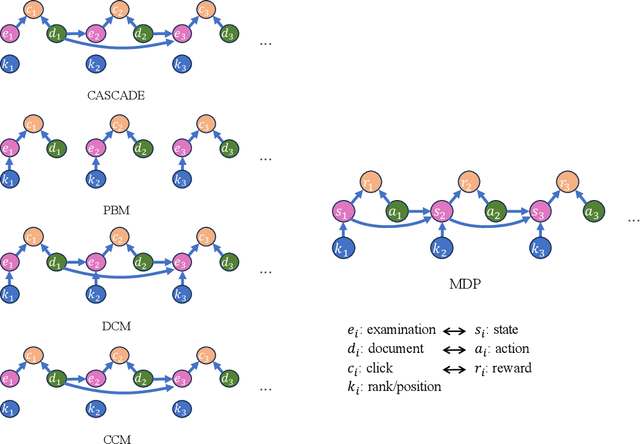

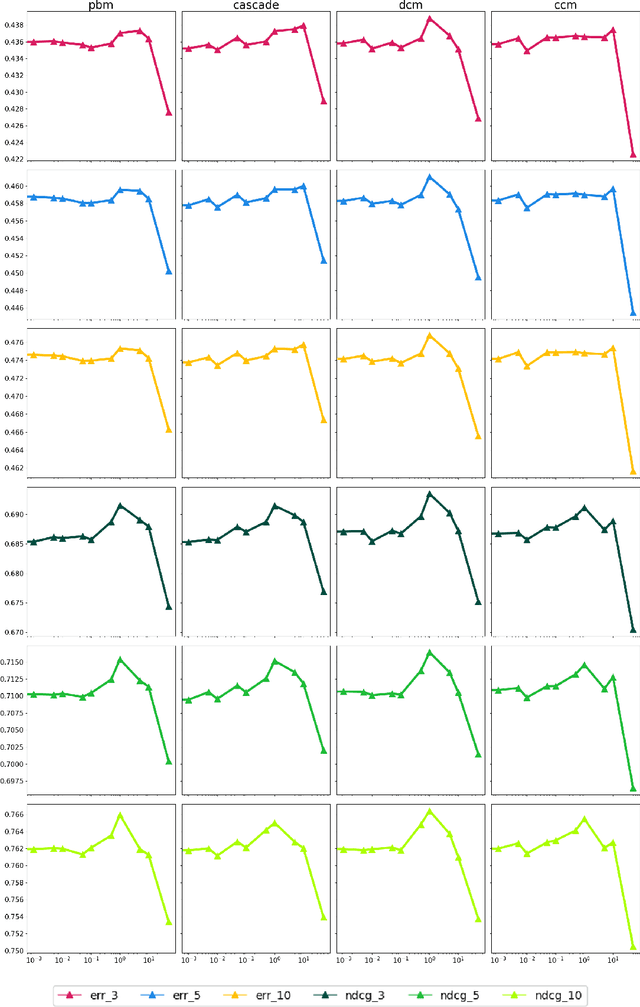
Off-policy Learning to Rank (LTR) aims to optimize a ranker from data collected by a deployed logging policy. However, existing off-policy learning to rank methods often make strong assumptions about how users generate the click data, i.e., the click model, and hence need to tailor their methods specifically under different click models. In this paper, we unified the ranking process under general stochastic click models as a Markov Decision Process (MDP), and the optimal ranking could be learned with offline reinforcement learning (RL) directly. Building upon this, we leverage offline RL techniques for off-policy LTR and propose the Click Model-Agnostic Unified Off-policy Learning to Rank (CUOLR) method, which could be easily applied to a wide range of click models. Through a dedicated formulation of the MDP, we show that offline RL algorithms can adapt to various click models without complex debiasing techniques and prior knowledge of the model. Results on various large-scale datasets demonstrate that CUOLR consistently outperforms the state-of-the-art off-policy learning to rank algorithms while maintaining consistency and robustness under different click models.
Adversarial Attacks on Online Learning to Rank with Stochastic Click Models
May 30, 2023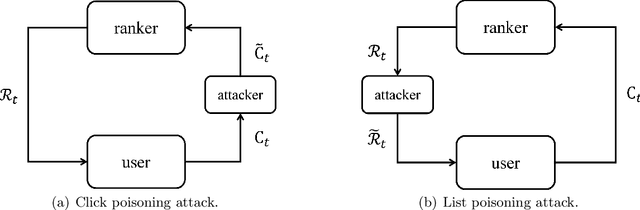
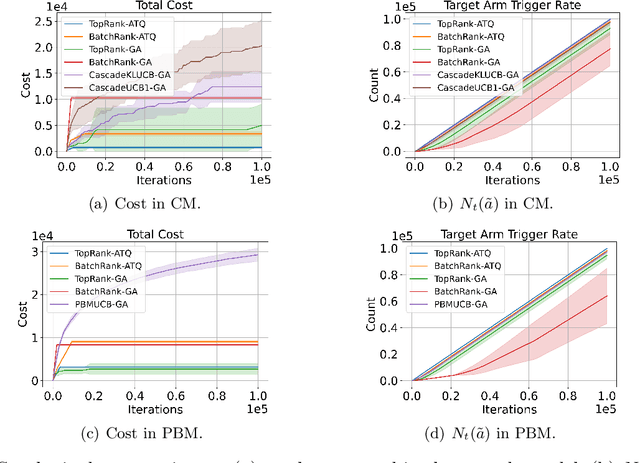
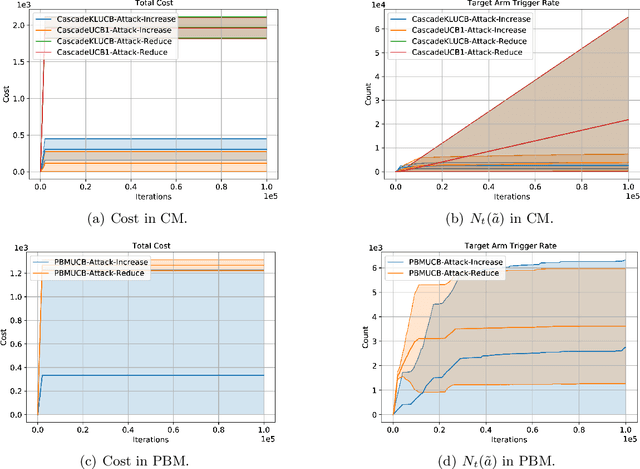
We propose the first study of adversarial attacks on online learning to rank. The goal of the adversary is to misguide the online learning to rank algorithm to place the target item on top of the ranking list linear times to time horizon $T$ with a sublinear attack cost. We propose generalized list poisoning attacks that perturb the ranking list presented to the user. This strategy can efficiently attack any no-regret ranker in general stochastic click models. Furthermore, we propose a click poisoning-based strategy named attack-then-quit that can efficiently attack two representative OLTR algorithms for stochastic click models. We theoretically analyze the success and cost upper bound of the two proposed methods. Experimental results based on synthetic and real-world data further validate the effectiveness and cost-efficiency of the proposed attack strategies.
Contrastive Learning for Object Detection
Aug 12, 2022

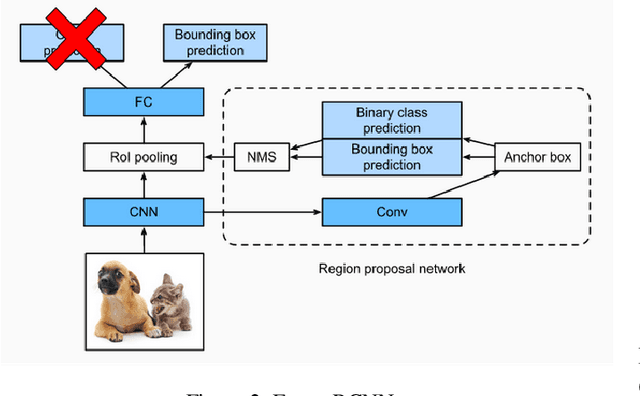
Contrastive learning is commonly used as a method of self-supervised learning with the "anchor" and "positive" being two random augmentations of a given input image, and the "negative" is the set of all other images. However, the requirement of large batch sizes and memory banks has made it difficult and slow to train. This has motivated the rise of Supervised Contrasative approaches that overcome these problems by using annotated data. We look to further improve supervised contrastive learning by ranking classes based on their similarity, and observe the impact of human bias (in the form of ranking) on the learned representations. We feel this is an important question to address, as learning good feature embeddings has been a long sought after problem in computer vision.
Contrastive Learning for OOD in Object detection
Aug 12, 2022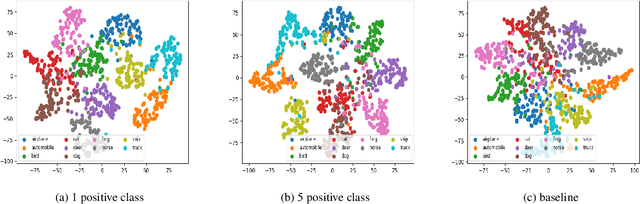
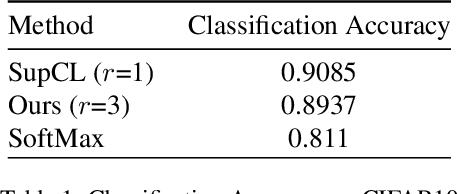
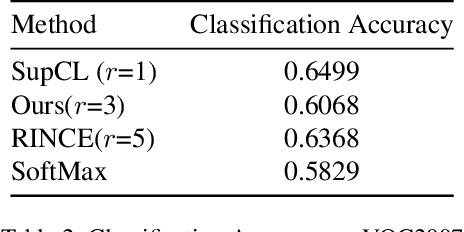
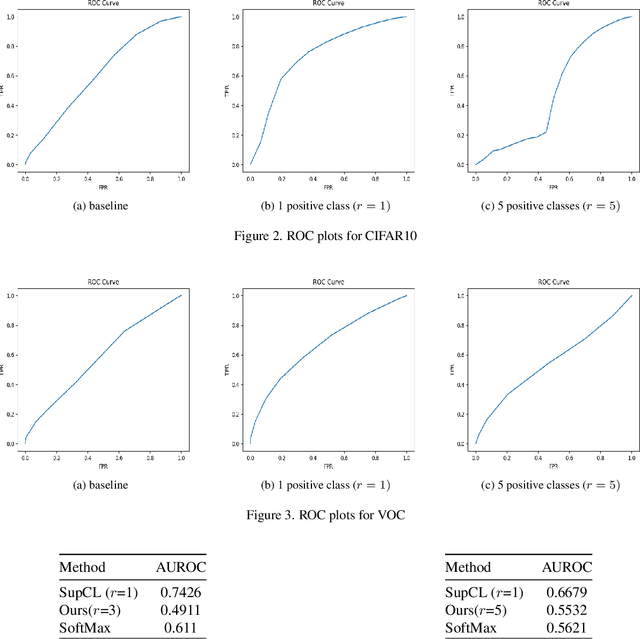
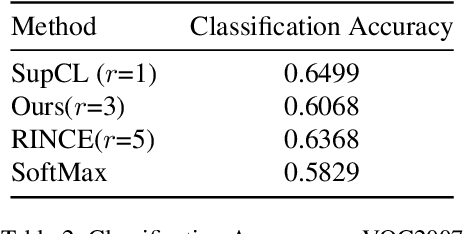
Contrastive learning is commonly applied to self-supervised learning, and has been shown to outperform traditional approaches such as the triplet loss and N-pair loss. However, the requirement of large batch sizes and memory banks has made it difficult and slow to train. Recently, Supervised Contrasative approaches have been developed to overcome these problems. They focus more on learning a good representation for each class individually, or between a cluster of classes. In this work we attempt to rank classes based on similarity using a user-defined ranking, to learn an efficient representation between all classes. We observe how incorporating human bias into the learning process could improve learning representations in the parameter space. We show that our results are comparable to Supervised Contrastive Learning for image classification and object detection, and discuss it's shortcomings in OOD Detection
Risk-Aware Submodular Optimization for Multi-objective Travelling Salesperson Problem
Nov 02, 2020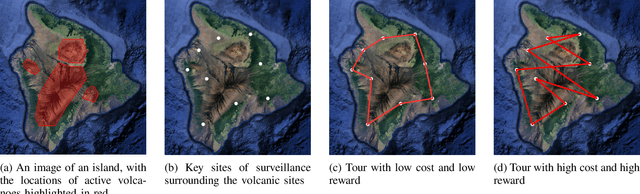
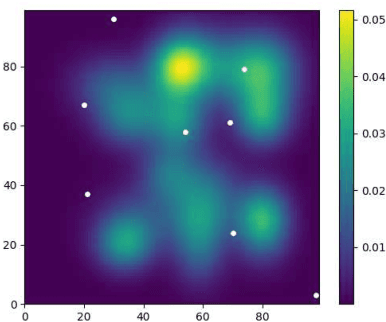
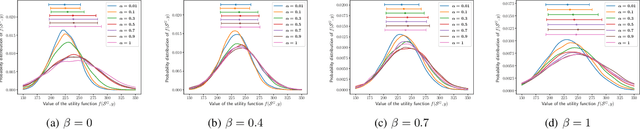
We introduce a risk-aware multi-objective Traveling Salesperson Problem (TSP) variant, where the robot tour cost and tour reward have to be optimized simultaneously. The robot obtains reward along the edges in the graph. We study the case where the rewards and the costs exhibit diminishing marginal gains, i.e., are submodular. Unlike prior work, we focus on the scenario where the costs and the rewards are uncertain and seek to maximize the Conditional-Value-at-Risk (CVaR) metric of the submodular function. We propose a risk-aware greedy algorithm (RAGA) to find a bounded-approximation algorithm. The approximation algorithm runs in polynomial time and is within a constant factor of the optimal and an additive term that depends on the optimal solution. We use the submodular function's curvature to improve approximation results further and verify the algorithm's performance through simulations.