 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIH-Challenge: A Training Dataset to Improve Instruction Hierarchy on Frontier LLMs
Mar 11, 2026Instruction hierarchy (IH) defines how LLMs prioritize system, developer, user, and tool instructions under conflict, providing a concrete, trust-ordered policy for resolving instruction conflicts. IH is key to defending against jailbreaks, system prompt extractions, and agentic prompt injections. However, robust IH behavior is difficult to train: IH failures can be confounded with instruction-following failures, conflicts can be nuanced, and models can learn shortcuts such as overrefusing. We introduce IH-Challenge, a reinforcement learning training dataset, to address these difficulties. Fine-tuning GPT-5-Mini on IH-Challenge with online adversarial example generation improves IH robustness by +10.0% on average across 16 in-distribution, out-of-distribution, and human red-teaming benchmarks (84.1% to 94.1%), reduces unsafe behavior from 6.6% to 0.7% while improving helpfulness on general safety evaluations, and saturates an internal static agentic prompt injection evaluation, with minimal capability regression. We release the IH-Challenge dataset (https://huggingface.co/datasets/openai/ih-challenge) to support future research on robust instruction hierarchy.
The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text
Jun 05, 2025Large language models (LLMs) are typically trained on enormous quantities of unlicensed text, a practice that has led to scrutiny due to possible intellectual property infringement and ethical concerns. Training LLMs on openly licensed text presents a first step towards addressing these issues, but prior data collection efforts have yielded datasets too small or low-quality to produce performant LLMs. To address this gap, we collect, curate, and release the Common Pile v0.1, an eight terabyte collection of openly licensed text designed for LLM pretraining. The Common Pile comprises content from 30 sources that span diverse domains including research papers, code, books, encyclopedias, educational materials, audio transcripts, and more. Crucially, we validate our efforts by training two 7 billion parameter LLMs on text from the Common Pile: Comma v0.1-1T and Comma v0.1-2T, trained on 1 and 2 trillion tokens respectively. Both models attain competitive performance to LLMs trained on unlicensed text with similar computational budgets, such as Llama 1 and 2 7B. In addition to releasing the Common Pile v0.1 itself, we also release the code used in its creation as well as the training mixture and checkpoints for the Comma v0.1 models.
Enhancing Training Data Attribution with Representational Optimization
May 24, 2025Training data attribution (TDA) methods aim to measure how training data impacts a model's predictions. While gradient-based attribution methods, such as influence functions, offer theoretical grounding, their computational costs make them impractical for large-scale applications. Representation-based approaches are far more scalable, but typically rely on heuristic embeddings that are not optimized for attribution, limiting their fidelity. To address these challenges, we propose AirRep, a scalable, representation-based approach that closes this gap by learning task-specific and model-aligned representations optimized explicitly for TDA. AirRep introduces two key innovations: a trainable encoder tuned for attribution quality, and an attention-based pooling mechanism that enables accurate estimation of group-wise influence. We train AirRep using a ranking objective over automatically constructed training subsets labeled by their empirical effect on target predictions. Experiments on instruction-tuned LLMs demonstrate that AirRep achieves performance on par with state-of-the-art gradient-based approaches while being nearly two orders of magnitude more efficient at inference time. Further analysis highlights its robustness and generalization across tasks and models. Our code is available at https://github.com/sunnweiwei/AirRep.
Position: The Most Expensive Part of an LLM should be its Training Data
Apr 16, 2025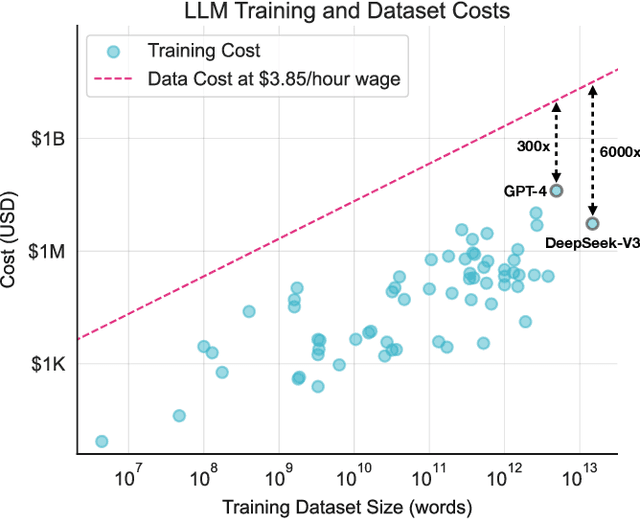
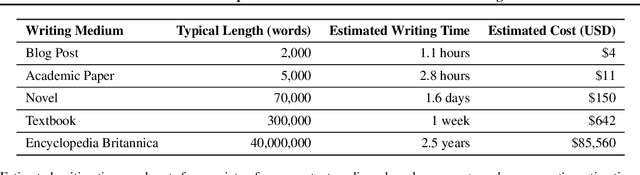
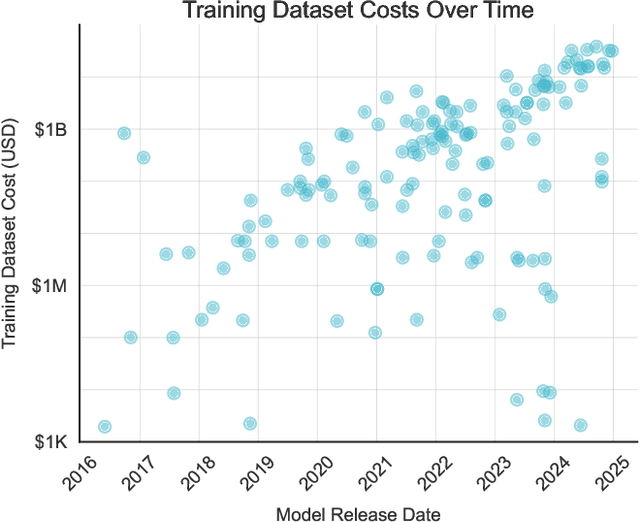
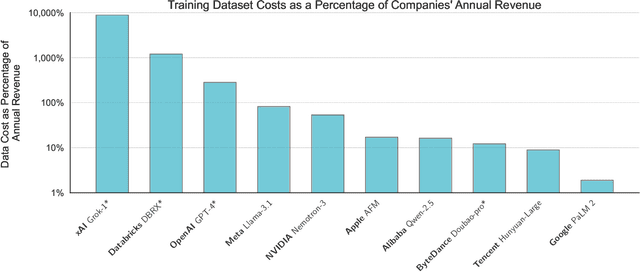
Training a state-of-the-art Large Language Model (LLM) is an increasingly expensive endeavor due to growing computational, hardware, energy, and engineering demands. Yet, an often-overlooked (and seldom paid) expense is the human labor behind these models' training data. Every LLM is built on an unfathomable amount of human effort: trillions of carefully written words sourced from books, academic papers, codebases, social media, and more. This position paper aims to assign a monetary value to this labor and argues that the most expensive part of producing an LLM should be the compensation provided to training data producers for their work. To support this position, we study 64 LLMs released between 2016 and 2024, estimating what it would cost to pay people to produce their training datasets from scratch. Even under highly conservative estimates of wage rates, the costs of these models' training datasets are 10-1000 times larger than the costs to train the models themselves, representing a significant financial liability for LLM providers. In the face of the massive gap between the value of training data and the lack of compensation for its creation, we highlight and discuss research directions that could enable fairer practices in the future.
Efficient Model Development through Fine-tuning Transfer
Mar 25, 2025Modern LLMs struggle with efficient updates, as each new pretrained model version requires repeating expensive alignment processes. This challenge also applies to domain- or language-specific models, where fine-tuning on specialized data must be redone for every new base model release. In this paper, we explore the transfer of fine-tuning updates between model versions. Specifically, we derive the diff vector from one source model version, which represents the weight changes from fine-tuning, and apply it to the base model of a different target version. Through empirical evaluations on various open-weight model versions, we show that transferring diff vectors can significantly improve the target base model, often achieving performance comparable to its fine-tuned counterpart. For example, reusing the fine-tuning updates from Llama 3.0 8B leads to an absolute accuracy improvement of 10.7% on GPQA over the base Llama 3.1 8B without additional training, surpassing Llama 3.1 8B Instruct. In a multilingual model development setting, we show that this approach can significantly increase performance on target-language tasks without retraining, achieving an absolute improvement of 4.7% and 15.5% on Global MMLU for Malagasy and Turkish, respectively, compared to Llama 3.1 8B Instruct. Our controlled experiments reveal that fine-tuning transfer is most effective when the source and target models are linearly connected in the parameter space. Additionally, we demonstrate that fine-tuning transfer offers a stronger and more computationally efficient starting point for further fine-tuning. Finally, we propose an iterative recycling-then-finetuning approach for continuous model development, which improves both efficiency and effectiveness. Our findings suggest that fine-tuning transfer is a viable strategy to reduce training costs while maintaining model performance.
AttriBoT: A Bag of Tricks for Efficiently Approximating Leave-One-Out Context Attribution
Nov 22, 2024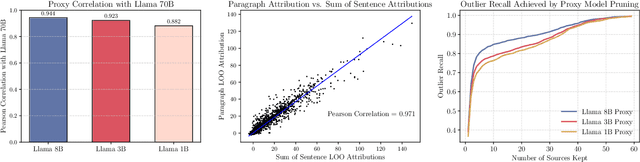



The influence of contextual input on the behavior of large language models (LLMs) has prompted the development of context attribution methods that aim to quantify each context span's effect on an LLM's generations. The leave-one-out (LOO) error, which measures the change in the likelihood of the LLM's response when a given span of the context is removed, provides a principled way to perform context attribution, but can be prohibitively expensive to compute for large models. In this work, we introduce AttriBoT, a series of novel techniques for efficiently computing an approximation of the LOO error for context attribution. Specifically, AttriBoT uses cached activations to avoid redundant operations, performs hierarchical attribution to reduce computation, and emulates the behavior of large target models with smaller proxy models. Taken together, AttriBoT can provide a >300x speedup while remaining more faithful to a target model's LOO error than prior context attribution methods. This stark increase in performance makes computing context attributions for a given response 30x faster than generating the response itself, empowering real-world applications that require computing attributions at scale. We release a user-friendly and efficient implementation of AttriBoT to enable efficient LLM interpretability as well as encourage future development of efficient context attribution methods.
User Inference Attacks on Large Language Models
Oct 13, 2023



Fine-tuning is a common and effective method for tailoring large language models (LLMs) to specialized tasks and applications. In this paper, we study the privacy implications of fine-tuning LLMs on user data. To this end, we define a realistic threat model, called user inference, wherein an attacker infers whether or not a user's data was used for fine-tuning. We implement attacks for this threat model that require only a small set of samples from a user (possibly different from the samples used for training) and black-box access to the fine-tuned LLM. We find that LLMs are susceptible to user inference attacks across a variety of fine-tuning datasets, at times with near perfect attack success rates. Further, we investigate which properties make users vulnerable to user inference, finding that outlier users (i.e. those with data distributions sufficiently different from other users) and users who contribute large quantities of data are most susceptible to attack. Finally, we explore several heuristics for mitigating privacy attacks. We find that interventions in the training algorithm, such as batch or per-example gradient clipping and early stopping fail to prevent user inference. However, limiting the number of fine-tuning samples from a single user can reduce attack effectiveness, albeit at the cost of reducing the total amount of fine-tuning data.
Git-Theta: A Git Extension for Collaborative Development of Machine Learning Models
Jun 07, 2023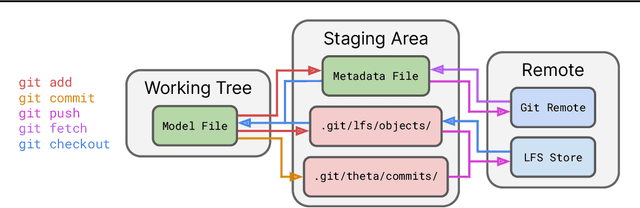
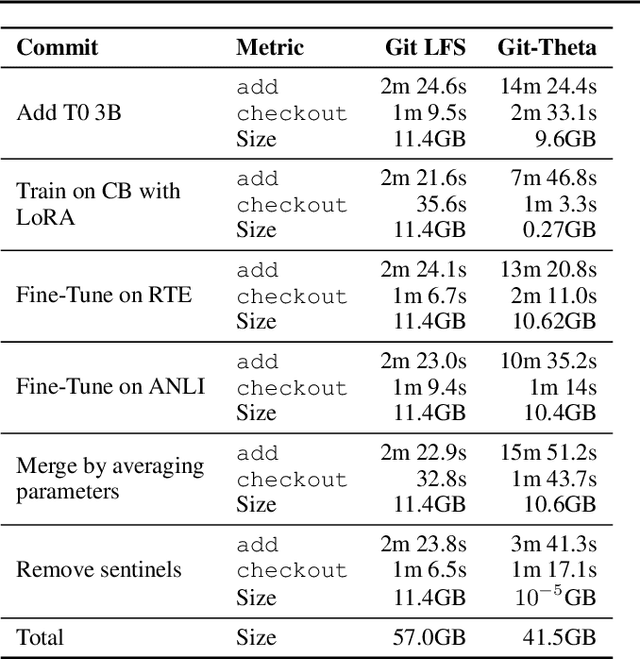
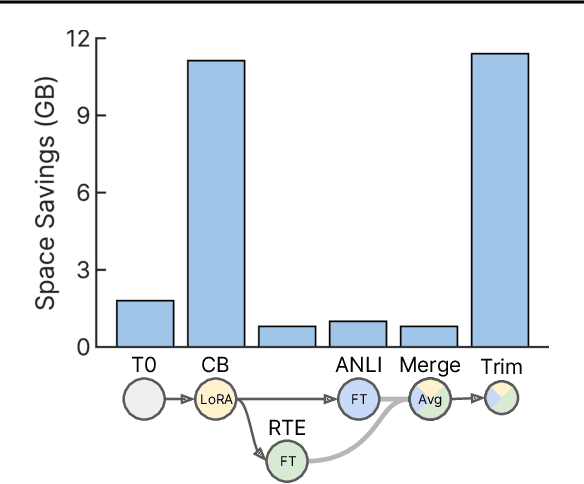
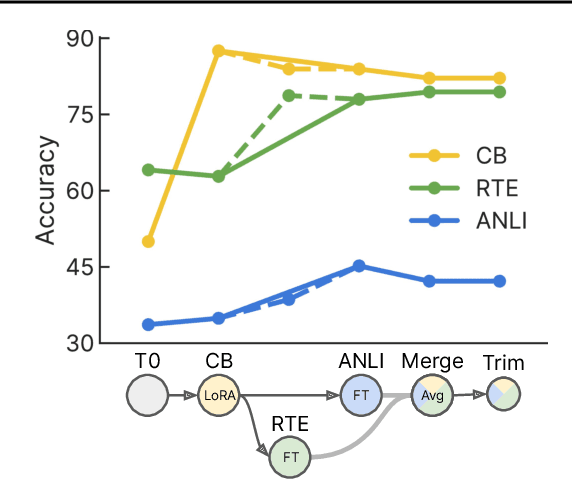
Currently, most machine learning models are trained by centralized teams and are rarely updated. In contrast, open-source software development involves the iterative development of a shared artifact through distributed collaboration using a version control system. In the interest of enabling collaborative and continual improvement of machine learning models, we introduce Git-Theta, a version control system for machine learning models. Git-Theta is an extension to Git, the most widely used version control software, that allows fine-grained tracking of changes to model parameters alongside code and other artifacts. Unlike existing version control systems that treat a model checkpoint as a blob of data, Git-Theta leverages the structure of checkpoints to support communication-efficient updates, automatic model merges, and meaningful reporting about the difference between two versions of a model. In addition, Git-Theta includes a plug-in system that enables users to easily add support for new functionality. In this paper, we introduce Git-Theta's design and features and include an example use-case of Git-Theta where a pre-trained model is continually adapted and modified. We publicly release Git-Theta in hopes of kickstarting a new era of collaborative model development.
Large Language Models Struggle to Learn Long-Tail Knowledge
Nov 15, 2022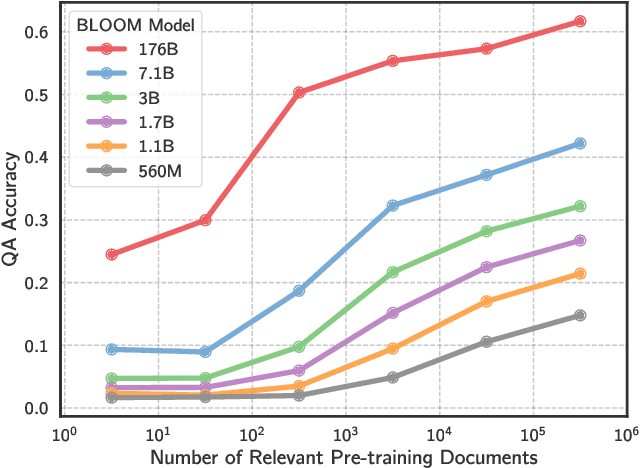
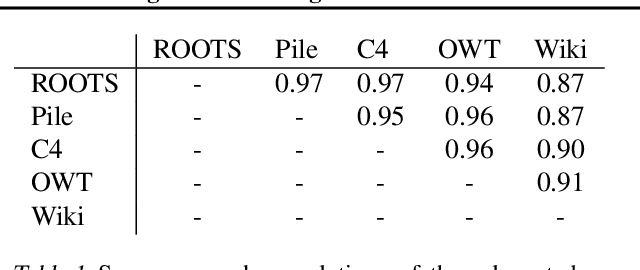
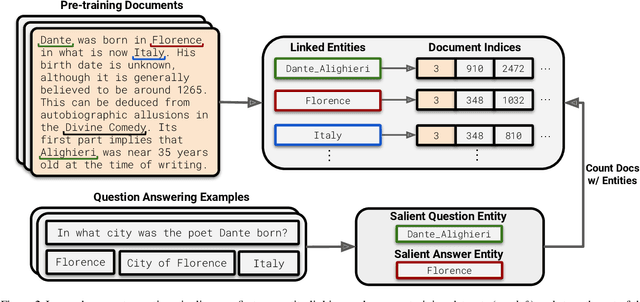
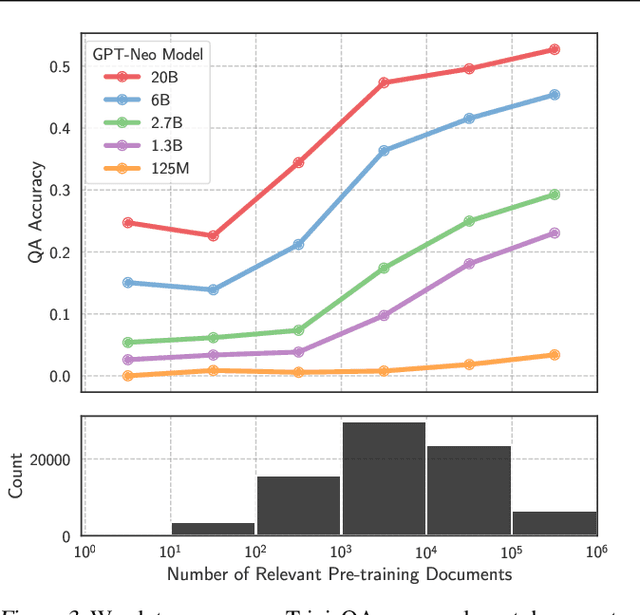
The internet contains a wealth of knowledge -- from the birthdays of historical figures to tutorials on how to code -- all of which may be learned by language models. However, there is a huge variability in the number of times a given piece of information appears on the web. In this paper, we study the relationship between the knowledge memorized by large language models and the information in their pre-training datasets. In particular, we show that a language model's ability to answer a fact-based question relates to how many documents associated with that question were seen during pre-training. We identify these relevant documents by entity linking pre-training datasets and counting documents that contain the same entities as a given question-answer pair. Our results demonstrate strong correlational and causal relationships between accuracy and relevant document count for numerous question answering datasets (e.g., TriviaQA), pre-training corpora (e.g., ROOTS), and model sizes (e.g., 176B parameters). Moreover, we find that while larger models are better at learning long-tail knowledge, we estimate that today's models must be scaled by many orders of magnitude to reach competitive QA performance on questions with little support in the pre-training data. Finally, we show that retrieval-augmentation can reduce the dependence on relevant document count, presenting a promising approach for capturing the long-tail.
Music Enhancement via Image Translation and Vocoding
Apr 28, 2022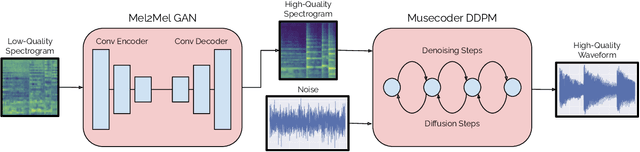
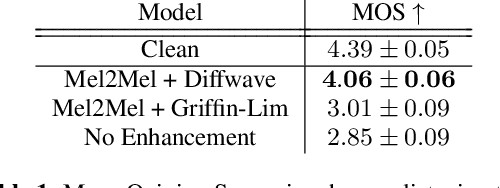


Consumer-grade music recordings such as those captured by mobile devices typically contain distortions in the form of background noise, reverb, and microphone-induced EQ. This paper presents a deep learning approach to enhance low-quality music recordings by combining (i) an image-to-image translation model for manipulating audio in its mel-spectrogram representation and (ii) a music vocoding model for mapping synthetically generated mel-spectrograms to perceptually realistic waveforms. We find that this approach to music enhancement outperforms baselines which use classical methods for mel-spectrogram inversion and an end-to-end approach directly mapping noisy waveforms to clean waveforms. Additionally, in evaluating the proposed method with a listening test, we analyze the reliability of common audio enhancement evaluation metrics when used in the music domain.