 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic Enhancement via Image Translation and Vocoding
Paper and Code
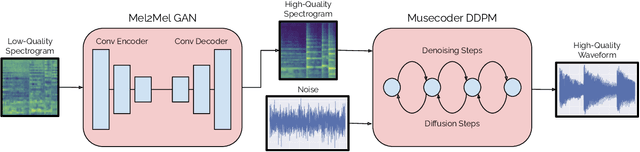
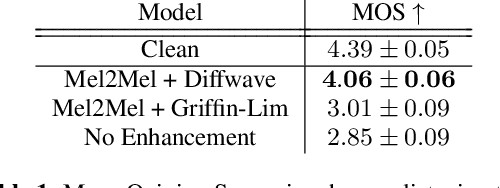


Consumer-grade music recordings such as those captured by mobile devices typically contain distortions in the form of background noise, reverb, and microphone-induced EQ. This paper presents a deep learning approach to enhance low-quality music recordings by combining (i) an image-to-image translation model for manipulating audio in its mel-spectrogram representation and (ii) a music vocoding model for mapping synthetically generated mel-spectrograms to perceptually realistic waveforms. We find that this approach to music enhancement outperforms baselines which use classical methods for mel-spectrogram inversion and an end-to-end approach directly mapping noisy waveforms to clean waveforms. Additionally, in evaluating the proposed method with a listening test, we analyze the reliability of common audio enhancement evaluation metrics when used in the music domain.