 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
Towards Automatic Soccer Commentary Generation with Knowledge-Enhanced Visual Reasoning
Mar 31, 2026Soccer commentary plays a crucial role in enhancing the soccer game viewing experience for audiences. Previous studies in automatic soccer commentary generation typically adopt an end-to-end method to generate anonymous live text commentary. Such generated commentary is insufficient in the context of real-world live televised commentary, as it contains anonymous entities, context-dependent errors and lacks statistical insights of the game events. To bridge the gap, we propose GameSight, a two-stage model to address soccer commentary generation as a knowledge-enhanced visual reasoning task, enabling live-televised-like knowledgeable commentary with accurate reference to entities (players and teams). GameSight starts by performing visual reasoning to align anonymous entities with fine-grained visual and contextual analysis. Subsequently, the entity-aligned commentary is refined with knowledge by incorporating external historical statistics and iteratively updated internal game state information. Consequently, GameSight improves the player alignment accuracy by 18.5% on SN-Caption-test-align dataset compared to Gemini 2.5-pro. Combined with further knowledge enhancement, GameSight outperforms in segment-level accuracy and commentary quality, as well as game-level contextual relevance and structural composition. We believe that our work paves the way for a more informative and engaging human-centric experience with the AI sports application. Demo Page: https://gamesight2025.github.io/gamesight2025
Gencho: Room Impulse Response Generation from Reverberant Speech and Text via Diffusion Transformers
Feb 09, 2026Blind room impulse response (RIR) estimation is a core task for capturing and transferring acoustic properties; yet existing methods often suffer from limited modeling capability and degraded performance under unseen conditions. Moreover, emerging generative audio applications call for more flexible impulse response generation methods. We propose Gencho, a diffusion-transformer-based model that predicts complex spectrogram RIRs from reverberant speech. A structure-aware encoder leverages isolation between early and late reflections to encode the input audio into a robust representation for conditioning, while the diffusion decoder generates diverse and perceptually realistic impulse responses from it. Gencho integrates modularly with standard speech processing pipelines for acoustic matching. Results show richer generated RIRs than non-generative baselines while maintaining strong performance in standard RIR metrics. We further demonstrate its application to text-conditioned RIR generation, highlighting Gencho's versatility for controllable acoustic simulation and generative audio tasks.
PromptSep: Generative Audio Separation via Multimodal Prompting
Nov 06, 2025Recent breakthroughs in language-queried audio source separation (LASS) have shown that generative models can achieve higher separation audio quality than traditional masking-based approaches. However, two key limitations restrict their practical use: (1) users often require operations beyond separation, such as sound removal; and (2) relying solely on text prompts can be unintuitive for specifying sound sources. In this paper, we propose PromptSep to extend LASS into a broader framework for general-purpose sound separation. PromptSep leverages a conditional diffusion model enhanced with elaborated data simulation to enable both audio extraction and sound removal. To move beyond text-only queries, we incorporate vocal imitation as an additional and more intuitive conditioning modality for our model, by incorporating Sketch2Sound as a data augmentation strategy. Both objective and subjective evaluations on multiple benchmarks demonstrate that PromptSep achieves state-of-the-art performance in sound removal and vocal-imitation-guided source separation, while maintaining competitive results on language-queried source separation.
Deep Audio Watermarks are Shallow: Limitations of Post-Hoc Watermarking Techniques for Speech
Apr 15, 2025In the audio modality, state-of-the-art watermarking methods leverage deep neural networks to allow the embedding of human-imperceptible signatures in generated audio. The ideal is to embed signatures that can be detected with high accuracy when the watermarked audio is altered via compression, filtering, or other transformations. Existing audio watermarking techniques operate in a post-hoc manner, manipulating "low-level" features of audio recordings after generation (e.g. through the addition of a low-magnitude watermark signal). We show that this post-hoc formulation makes existing audio watermarks vulnerable to transformation-based removal attacks. Focusing on speech audio, we (1) unify and extend existing evaluations of the effect of audio transformations on watermark detectability, and (2) demonstrate that state-of-the-art post-hoc audio watermarks can be removed with no knowledge of the watermarking scheme and minimal degradation in audio quality.
DiTSE: High-Fidelity Generative Speech Enhancement via Latent Diffusion Transformers
Apr 13, 2025Real-world speech recordings suffer from degradations such as background noise and reverberation. Speech enhancement aims to mitigate these issues by generating clean high-fidelity signals. While recent generative approaches for speech enhancement have shown promising results, they still face two major challenges: (1) content hallucination, where plausible phonemes generated differ from the original utterance; and (2) inconsistency, failing to preserve speaker's identity and paralinguistic features from the input speech. In this work, we introduce DiTSE (Diffusion Transformer for Speech Enhancement), which addresses quality issues of degraded speech in full bandwidth. Our approach employs a latent diffusion transformer model together with robust conditioning features, effectively addressing these challenges while remaining computationally efficient. Experimental results from both subjective and objective evaluations demonstrate that DiTSE achieves state-of-the-art audio quality that, for the first time, matches real studio-quality audio from the DAPS dataset. Furthermore, DiTSE significantly improves the preservation of speaker identity and content fidelity, reducing hallucinations across datasets compared to state-of-the-art enhancers. Audio samples are available at: http://hguimaraes.me/DiTSE
SpeakEasy: Enhancing Text-to-Speech Interactions for Expressive Content Creation
Apr 07, 2025



Novice content creators often invest significant time recording expressive speech for social media videos. While recent advancements in text-to-speech (TTS) technology can generate highly realistic speech in various languages and accents, many struggle with unintuitive or overly granular TTS interfaces. We propose simplifying TTS generation by allowing users to specify high-level context alongside their script. Our Wizard-of-Oz system, SpeakEasy, leverages user-provided context to inform and influence TTS output, enabling iterative refinement with high-level feedback. This approach was informed by two 8-subject formative studies: one examining content creators' experiences with TTS, and the other drawing on effective strategies from voice actors. Our evaluation shows that participants using SpeakEasy were more successful in generating performances matching their personal standards, without requiring significantly more effort than leading industry interfaces.
Everyone-Can-Sing: Zero-Shot Singing Voice Synthesis and Conversion with Speech Reference
Jan 23, 2025We propose a unified framework for Singing Voice Synthesis (SVS) and Conversion (SVC), addressing the limitations of existing approaches in cross-domain SVS/SVC, poor output musicality, and scarcity of singing data. Our framework enables control over multiple aspects, including language content based on lyrics, performance attributes based on a musical score, singing style and vocal techniques based on a selector, and voice identity based on a speech sample. The proposed zero-shot learning paradigm consists of one SVS model and two SVC models, utilizing pre-trained content embeddings and a diffusion-based generator. The proposed framework is also trained on mixed datasets comprising both singing and speech audio, allowing singing voice cloning based on speech reference. Experiments show substantial improvements in timbre similarity and musicality over state-of-the-art baselines, providing insights into other low-data music tasks such as instrumental style transfer. Examples can be found at: everyone-can-sing.github.io.
Code Drift: Towards Idempotent Neural Audio Codecs
Oct 14, 2024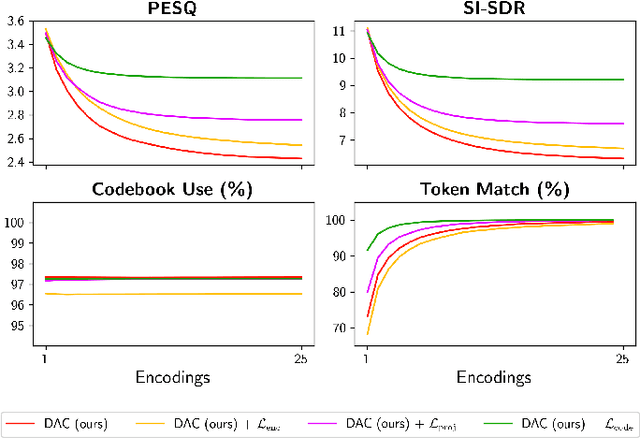
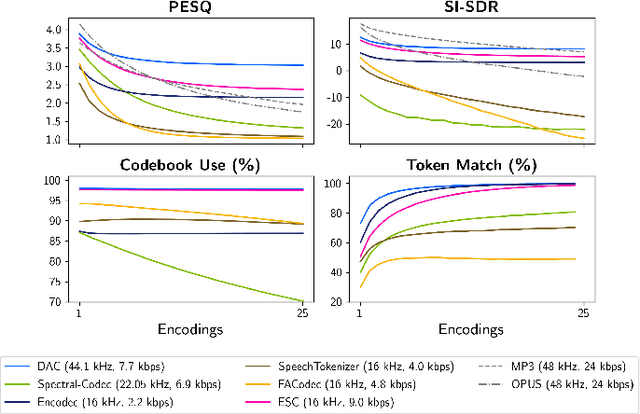
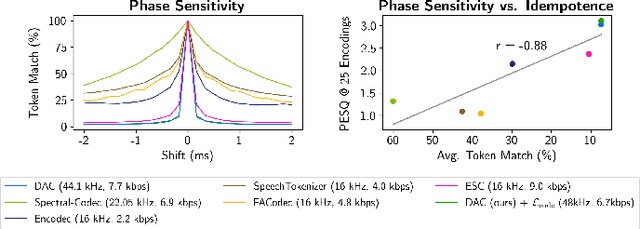
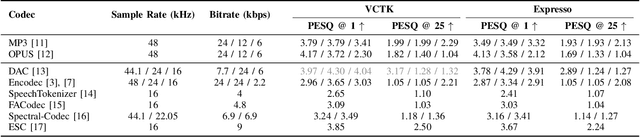
Neural codecs have demonstrated strong performance in high-fidelity compression of audio signals at low bitrates. The token-based representations produced by these codecs have proven particularly useful for generative modeling. While much research has focused on improvements in compression ratio and perceptual transparency, recent works have largely overlooked another desirable codec property -- idempotence, the stability of compressed outputs under multiple rounds of encoding. We find that state-of-the-art neural codecs exhibit varied degrees of idempotence, with some degrading audio outputs significantly after as few as three encodings. We investigate possible causes of low idempotence and devise a method for improving idempotence through fine-tuning a codec model. We then examine the effect of idempotence on a simple conditional generative modeling task, and find that increased idempotence can be achieved without negatively impacting downstream modeling performance -- potentially extending the usefulness of neural codecs for practical file compression and iterative generative modeling workflows.
DMDSpeech: Distilled Diffusion Model Surpassing The Teacher in Zero-shot Speech Synthesis via Direct Metric Optimization
Oct 14, 2024



Diffusion models have demonstrated significant potential in speech synthesis tasks, including text-to-speech (TTS) and voice cloning. However, their iterative denoising processes are inefficient and hinder the application of end-to-end optimization with perceptual metrics. In this paper, we propose a novel method of distilling TTS diffusion models with direct end-to-end evaluation metric optimization, achieving state-of-the-art performance. By incorporating Connectionist Temporal Classification (CTC) loss and Speaker Verification (SV) loss, our approach optimizes perceptual evaluation metrics, leading to notable improvements in word error rate and speaker similarity. Our experiments show that DMDSpeech consistently surpasses prior state-of-the-art models in both naturalness and speaker similarity while being significantly faster. Moreover, our synthetic speech has a higher level of voice similarity to the prompt than the ground truth in both human evaluation and objective speaker similarity metric. This work highlights the potential of direct metric optimization in speech synthesis, allowing models to better align with human auditory preferences. The audio samples are available at https://dmdspeech.github.io/.