 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedCoRAG: Interpretable Hepatology Diagnosis via Hybrid Evidence Retrieval and Multispecialty Consensus
Mar 05, 2026Diagnosing hepatic diseases accurately and interpretably is critical, yet it remains challenging in real-world clinical settings. Existing AI approaches for clinical diagnosis often lack transparency, structured reasoning, and deployability. Recent efforts have leveraged large language models (LLMs), retrieval-augmented generation (RAG), and multi-agent collaboration. However, these approaches typically retrieve evidence from a single source and fail to support iterative, role-specialized deliberation grounded in structured clinical data. To address this, we propose MedCoRAG (i.e., Medical Collaborative RAG), an end-to-end framework that generates diagnostic hypotheses from standardized abnormal findings and constructs a patient-specific evidence package by jointly retrieving and pruning UMLS knowledge graph paths and clinical guidelines. It then performs Multi-Agent Collaborative Reasoning: a Router Agent dynamically dispatches Specialist Agents based on case complexity; these agents iteratively reason over the evidence and trigger targeted re-retrievals when needed, while a Generalist Agent synthesizes all deliberations into a traceable consensus diagnosis that emulates multidisciplinary consultation. Experimental results on hepatic disease cases from MIMIC-IV show that MedCoRAG outperforms existing methods and closed-source models in both diagnostic performance and reasoning interpretability.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Everyone-Can-Sing: Zero-Shot Singing Voice Synthesis and Conversion with Speech Reference
Jan 23, 2025We propose a unified framework for Singing Voice Synthesis (SVS) and Conversion (SVC), addressing the limitations of existing approaches in cross-domain SVS/SVC, poor output musicality, and scarcity of singing data. Our framework enables control over multiple aspects, including language content based on lyrics, performance attributes based on a musical score, singing style and vocal techniques based on a selector, and voice identity based on a speech sample. The proposed zero-shot learning paradigm consists of one SVS model and two SVC models, utilizing pre-trained content embeddings and a diffusion-based generator. The proposed framework is also trained on mixed datasets comprising both singing and speech audio, allowing singing voice cloning based on speech reference. Experiments show substantial improvements in timbre similarity and musicality over state-of-the-art baselines, providing insights into other low-data music tasks such as instrumental style transfer. Examples can be found at: everyone-can-sing.github.io.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Towards Adaptive Unknown Authentication for Universal Domain Adaptation by Classifier Paradox
Jul 10, 2022


Universal domain adaptation (UniDA) is a general unsupervised domain adaptation setting, which addresses both domain and label shifts in adaptation. Its main challenge lies in how to identify target samples in unshared or unknown classes. Previous methods commonly strive to depict sample "confidence" along with a threshold for rejecting unknowns, and align feature distributions of shared classes across domains. However, it is still hard to pre-specify a "confidence" criterion and threshold which are adaptive to various real tasks, and a mis-prediction of unknowns further incurs misalignment of features in shared classes. In this paper, we propose a new UniDA method with adaptive Unknown Authentication by Classifier Paradox (UACP), considering that samples with paradoxical predictions are probably unknowns belonging to none of the source classes. In UACP, a composite classifier is jointly designed with two types of predictors. That is, a multi-class (MC) predictor classifies samples to one of the multiple source classes, while a binary one-vs-all (OVA) predictor further verifies the prediction by MC predictor. Samples with verification failure or paradox are identified as unknowns. Further, instead of feature alignment for shared classes, implicit domain alignment is conducted in output space such that samples across domains share the same decision boundary, though with feature discrepancy. Empirical results validate UACP under both open-set and universal UDA settings.
Dual-Correction Adaptation Network for Noisy Knowledge Transfer
Jul 10, 2022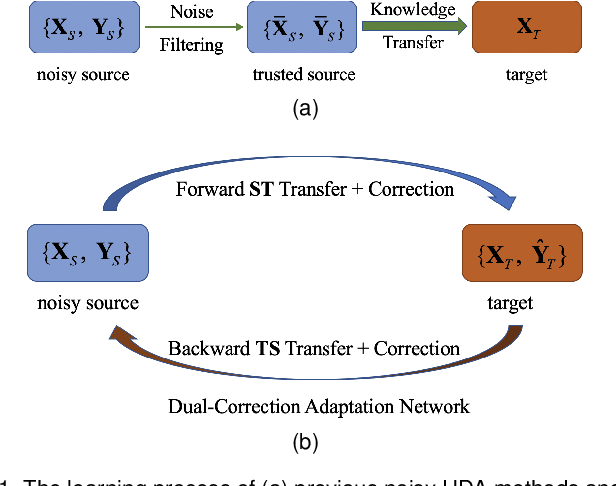

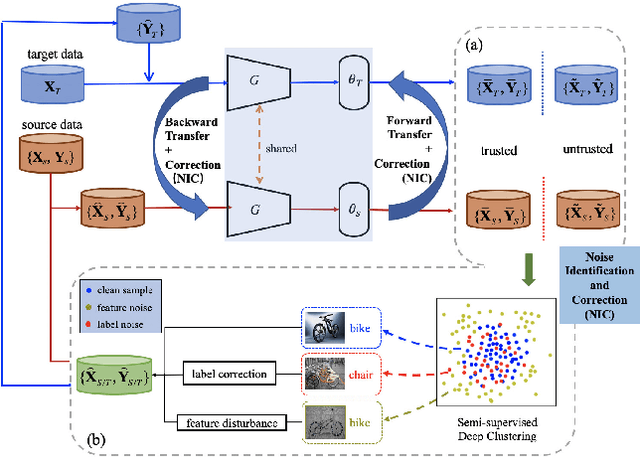
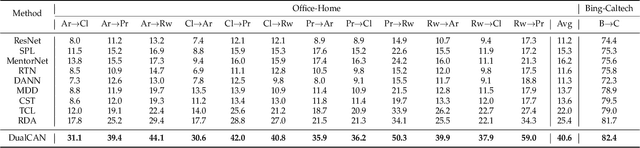
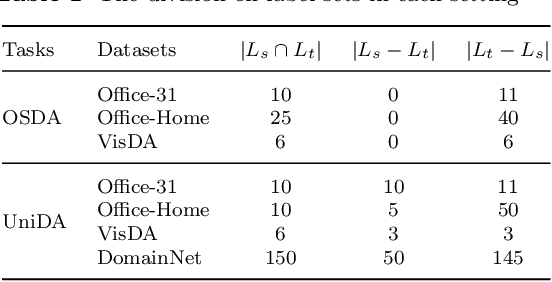
Previous unsupervised domain adaptation (UDA) methods aim to promote target learning via a single-directional knowledge transfer from label-rich source domain to unlabeled target domain, while its reverse adaption from target to source has not jointly been considered yet so far. In fact, in some real teaching practice, a teacher helps students learn while also gets promotion from students to some extent, which inspires us to explore a dual-directional knowledge transfer between domains, and thus propose a Dual-Correction Adaptation Network (DualCAN) in this paper. However, due to the asymmetrical label knowledge across domains, transfer from unlabeled target to labeled source poses a more difficult challenge than the common source-to-target counterpart. First, the target pseudo-labels predicted by source commonly involve noises due to model bias, hence in the reverse adaptation, they may hurt the source performance and bring a negative target-to-source transfer. Secondly, source domain usually contains innate noises, which will inevitably aggravate the target noises, leading to noise amplification across domains. To this end, we further introduce a Noise Identification and Correction (NIC) module to correct and recycle noises in both domains. To our best knowledge, this is the first naive attempt of dual-directional adaptation for noisy UDA, and naturally applicable to noise-free UDA. A theory justification is given to state the rationality of our intuition. Empirical results confirm the effectiveness of DualCAN with remarkable performance gains over state-of-the-arts, particularly for extreme noisy tasks (e.g., ~+ 15% on Pw->Pr and Pr->Rw of Office-Home).
Pre-Training on Dynamic Graph Neural Networks
Feb 24, 2021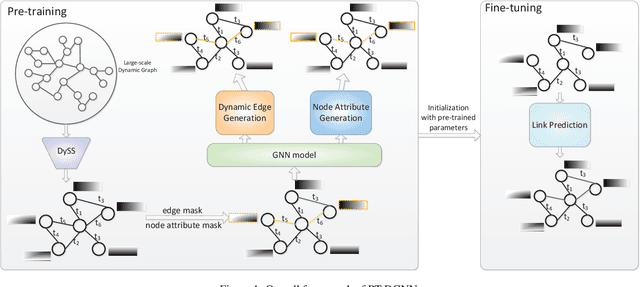

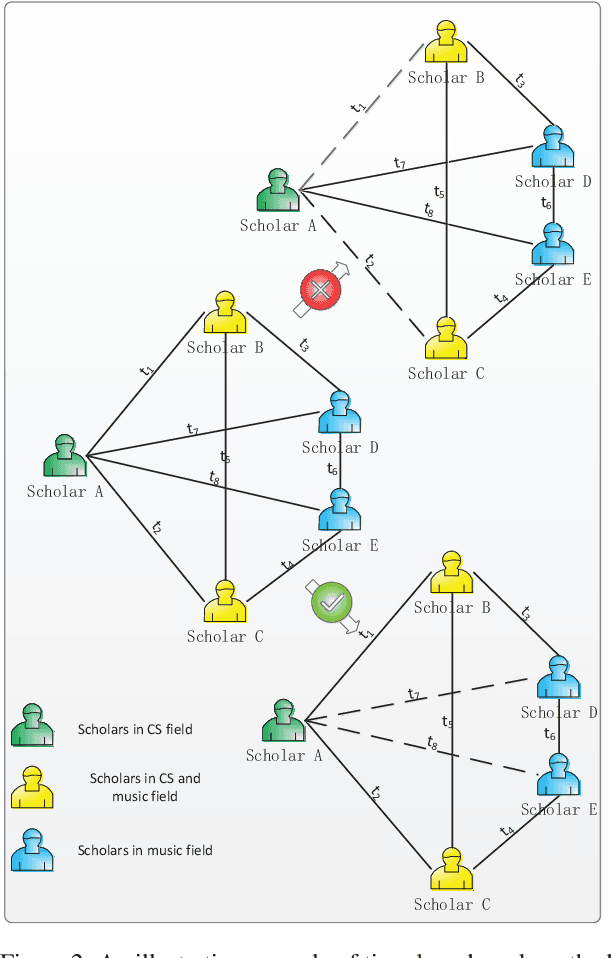
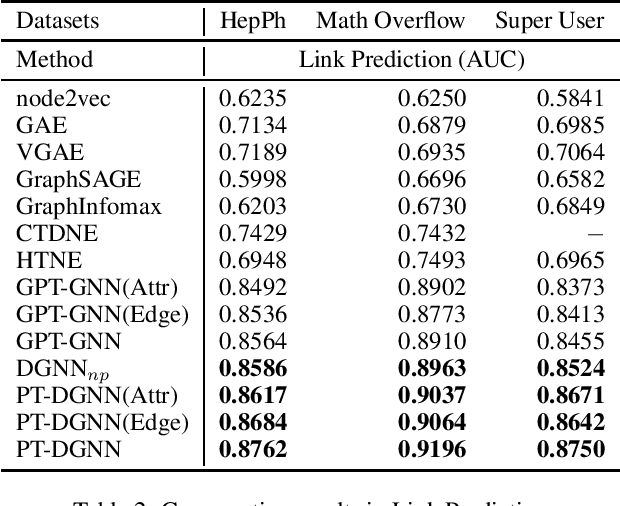
The pre-training on the graph neural network model can learn the general features of large-scale networks or networks of the same type by self-supervised methods, which allows the model to work even when node labels are missing. However, the existing pre-training methods do not take network evolution into consideration. This paper proposes a pre-training method on dynamic graph neural networks (PT-DGNN), which uses dynamic attributed graph generation tasks to simultaneously learn the structure, semantics, and evolution features of the graph. The method includes two steps: 1) dynamic sub-graph sampling, and 2) pre-training with dynamic attributed graph generation task. Comparative experiments on three realistic dynamic network datasets show that the proposed method achieves the best results on the link prediction fine-tuning task.