 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamME: Simplify 3D Gaussian Avatar within Live Stream
Jul 22, 2025We propose StreamME, a method focuses on fast 3D avatar reconstruction. The StreamME synchronously records and reconstructs a head avatar from live video streams without any pre-cached data, enabling seamless integration of the reconstructed appearance into downstream applications. This exceptionally fast training strategy, which we refer to as on-the-fly training, is central to our approach. Our method is built upon 3D Gaussian Splatting (3DGS), eliminating the reliance on MLPs in deformable 3DGS and relying solely on geometry, which significantly improves the adaptation speed to facial expression. To further ensure high efficiency in on-the-fly training, we introduced a simplification strategy based on primary points, which distributes the point clouds more sparsely across the facial surface, optimizing points number while maintaining rendering quality. Leveraging the on-the-fly training capabilities, our method protects the facial privacy and reduces communication bandwidth in VR system or online conference. Additionally, it can be directly applied to downstream application such as animation, toonify, and relighting. Please refer to our project page for more details: https://songluchuan.github.io/StreamME/.
A Closer Look at the Limitations of Instruction Tuning
Feb 03, 2024Instruction Tuning (IT), the process of training large language models (LLMs) using instruction-response pairs, has emerged as the predominant method for transforming base pre-trained LLMs into open-domain conversational agents. While IT has achieved notable success and widespread adoption, its limitations and shortcomings remain underexplored. In this paper, through rigorous experiments and an in-depth analysis of the changes LLMs undergo through IT, we reveal various limitations of IT. In particular, we show that (1) IT fails to enhance knowledge or skills in LLMs. LoRA fine-tuning is limited to learning response initiation and style tokens, and full-parameter fine-tuning leads to knowledge degradation. (2) Copying response patterns from IT datasets derived from knowledgeable sources leads to a decline in response quality. (3) Full-parameter fine-tuning increases hallucination by inaccurately borrowing tokens from conceptually similar instances in the IT dataset for generating responses. (4) Popular methods to improve IT do not lead to performance improvements over a simple LoRA fine-tuned model. Our findings reveal that responses generated solely from pre-trained knowledge consistently outperform responses by models that learn any form of new knowledge from IT on open-source datasets. We hope the insights and challenges revealed inspire future work.
Audio-driven Neural Gesture Reenactment with Video Motion Graphs
Jul 23, 2022
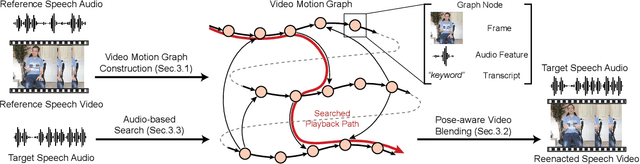
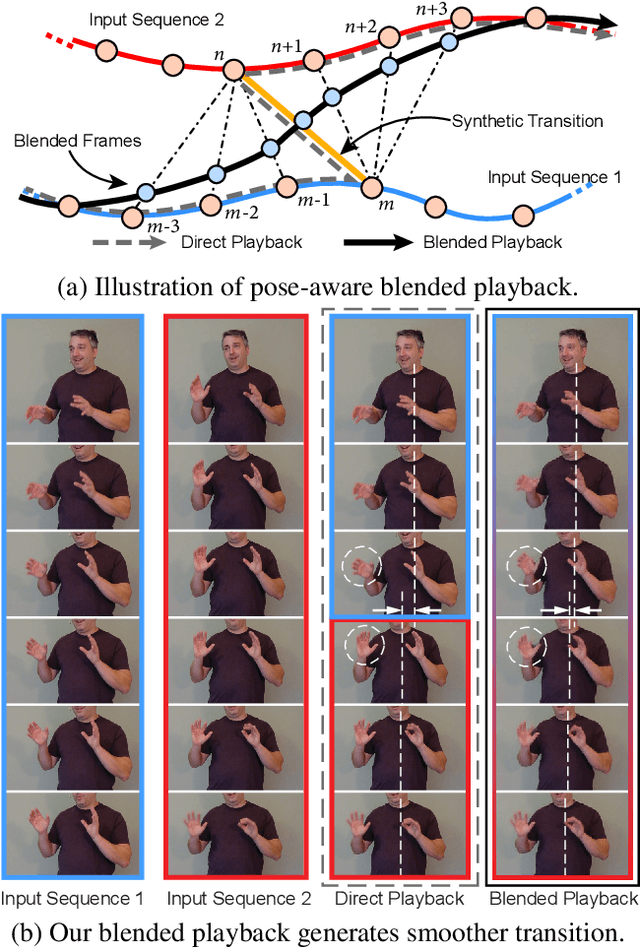
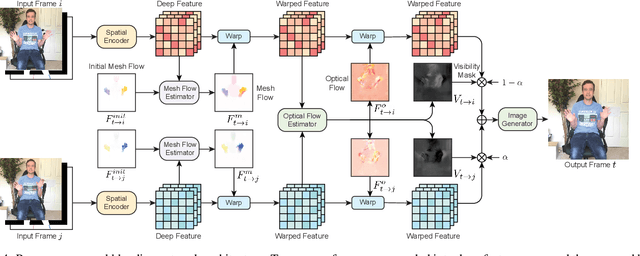
Human speech is often accompanied by body gestures including arm and hand gestures. We present a method that reenacts a high-quality video with gestures matching a target speech audio. The key idea of our method is to split and re-assemble clips from a reference video through a novel video motion graph encoding valid transitions between clips. To seamlessly connect different clips in the reenactment, we propose a pose-aware video blending network which synthesizes video frames around the stitched frames between two clips. Moreover, we developed an audio-based gesture searching algorithm to find the optimal order of the reenacted frames. Our system generates reenactments that are consistent with both the audio rhythms and the speech content. We evaluate our synthesized video quality quantitatively, qualitatively, and with user studies, demonstrating that our method produces videos of much higher quality and consistency with the target audio compared to previous work and baselines.
APES: Articulated Part Extraction from Sprite Sheets
Jun 04, 2022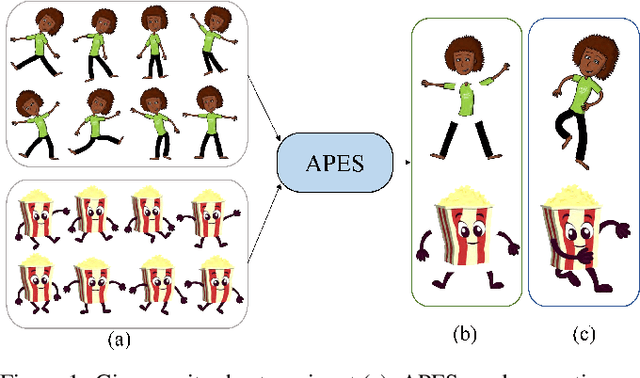
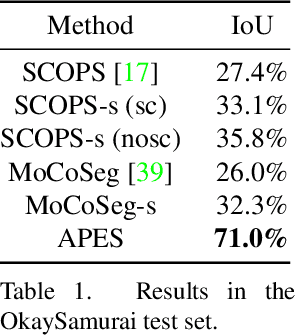
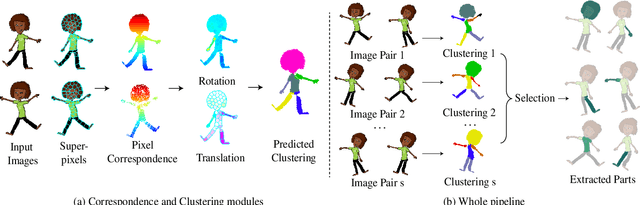

Rigged puppets are one of the most prevalent representations to create 2D character animations. Creating these puppets requires partitioning characters into independently moving parts. In this work, we present a method to automatically identify such articulated parts from a small set of character poses shown in a sprite sheet, which is an illustration of the character that artists often draw before puppet creation. Our method is trained to infer articulated parts, e.g. head, torso and limbs, that can be re-assembled to best reconstruct the given poses. Our results demonstrate significantly better performance than alternatives qualitatively and quantitatively.Our project page https://zhan-xu.github.io/parts/ includes our code and data.
Learning Stylized Character Expressions from Humans
Nov 19, 2019
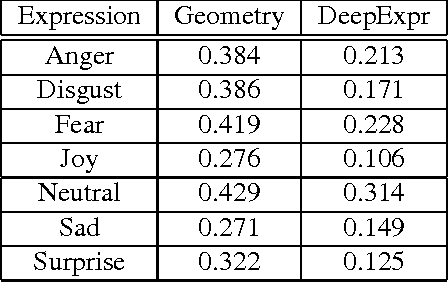

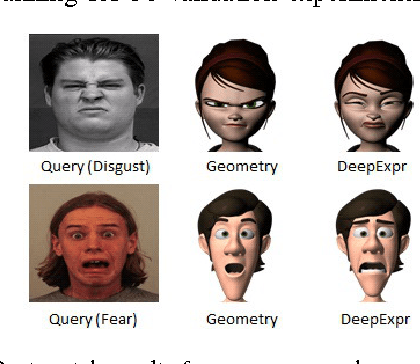
We present DeepExpr, a novel expression transfer system from humans to multiple stylized characters via deep learning. We developed : 1) a data-driven perceptual model of facial expressions, 2) a novel stylized character data set with cardinal expression annotations : FERG (Facial Expression Research Group) - DB (added two new characters), and 3) . We evaluated our method on a set of retrieval tasks on our collected stylized character dataset of expressions. We have also shown that the ranking order predicted by the proposed features is highly correlated with the ranking order provided by a facial expression expert and Mechanical Turk (MT) experiments.
Real-Time Lip Sync for Live 2D Animation
Oct 19, 2019
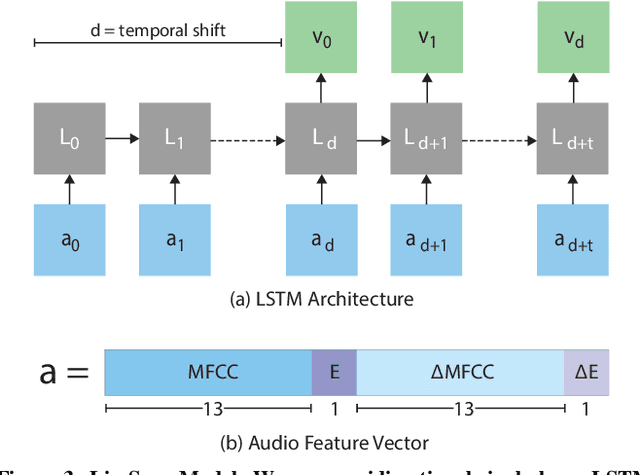
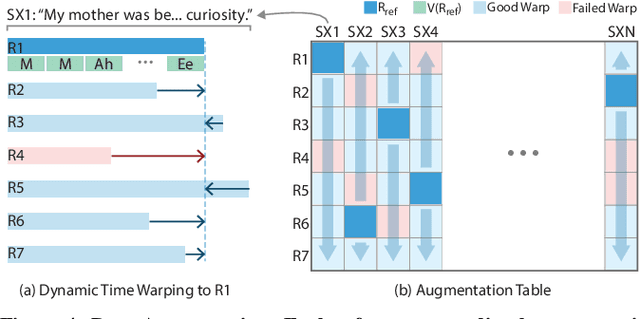
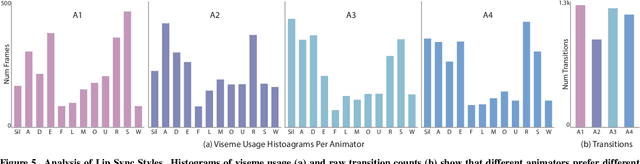
The emergence of commercial tools for real-time performance-based 2D animation has enabled 2D characters to appear on live broadcasts and streaming platforms. A key requirement for live animation is fast and accurate lip sync that allows characters to respond naturally to other actors or the audience through the voice of a human performer. In this work, we present a deep learning based interactive system that automatically generates live lip sync for layered 2D characters using a Long Short Term Memory (LSTM) model. Our system takes streaming audio as input and produces viseme sequences with less than 200ms of latency (including processing time). Our contributions include specific design decisions for our feature definition and LSTM configuration that provide a small but useful amount of lookahead to produce accurate lip sync. We also describe a data augmentation procedure that allows us to achieve good results with a very small amount of hand-animated training data (13-20 minutes). Extensive human judgement experiments show that our results are preferred over several competing methods, including those that only support offline (non-live) processing. Video summary and supplementary results at GitHub link: https://github.com/deepalianeja/CharacterLipSync2D
Designing Style Matching Conversational Agents
Oct 16, 2019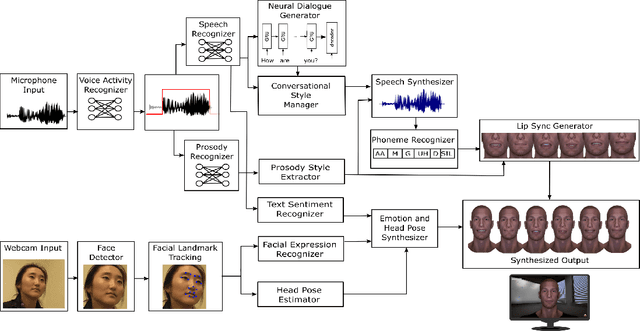
Advances in machine intelligence have enabled conversational interfaces that have the potential to radically change the way humans interact with machines. However, even with the progress in the abilities of these agents, there remain critical gaps in their capacity for natural interactions. One limitation is that the agents are often monotonic in behavior and do not adapt to their partner. We built two end-to-end conversational agents: a voice-based agent that can engage in naturalistic, multi-turn dialogue and align with the interlocutor's conversational style, and a 2nd, expressive, embodied conversational agent (ECA) that can recognize human behavior during open-ended conversations and automatically align its responses to the visual and conversational style of the other party. The embodied conversational agent leverages multimodal inputs to produce rich and perceptually valid vocal and facial responses (e.g., lip syncing and expressions) during the conversation. Based on empirical results from a set of user studies, we highlight several significant challenges in building such systems and provide design guidelines for multi-turn dialogue interactions using style adaptation for future research.
A High-Fidelity Open Embodied Avatar with Lip Syncing and Expression Capabilities
Oct 15, 2019
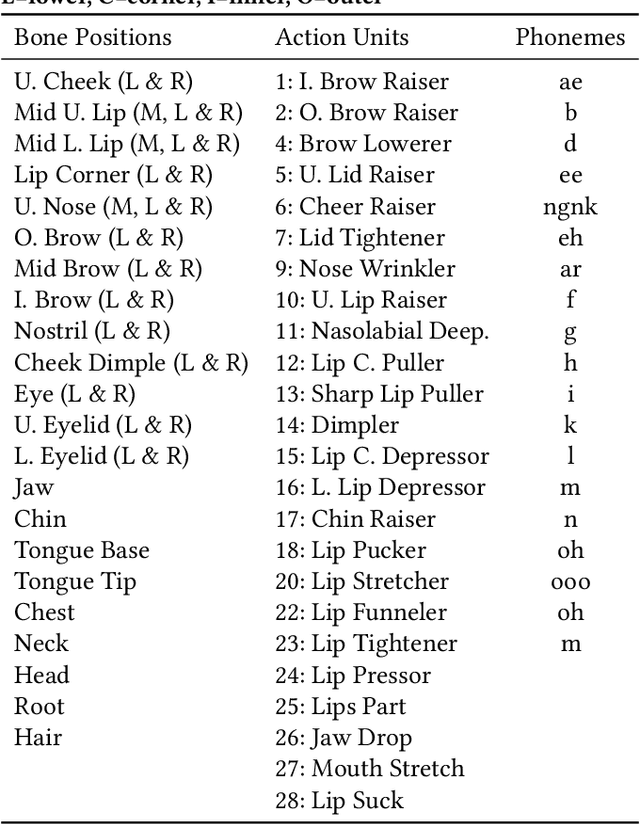
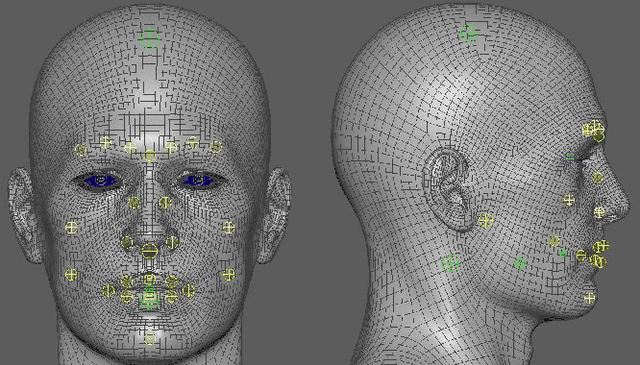

Embodied avatars as virtual agents have many applications and provide benefits over disembodied agents, allowing non-verbal social and interactional cues to be leveraged, in a similar manner to how humans interact with each other. We present an open embodied avatar built upon the Unreal Engine that can be controlled via a simple python programming interface. The avatar has lip syncing (phoneme control), head gesture and facial expression (using either facial action units or cardinal emotion categories) capabilities. We release code and models to illustrate how the avatar can be controlled like a puppet or used to create a simple conversational agent using public application programming interfaces (APIs). GITHUB link: https://github.com/danmcduff/AvatarSim
A Facial Affect Analysis System for Autism Spectrum Disorder
Apr 07, 2019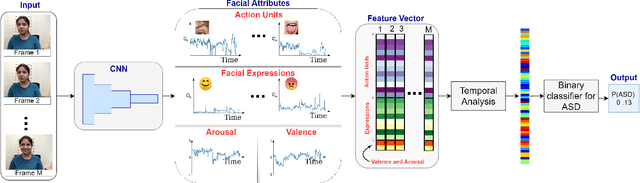
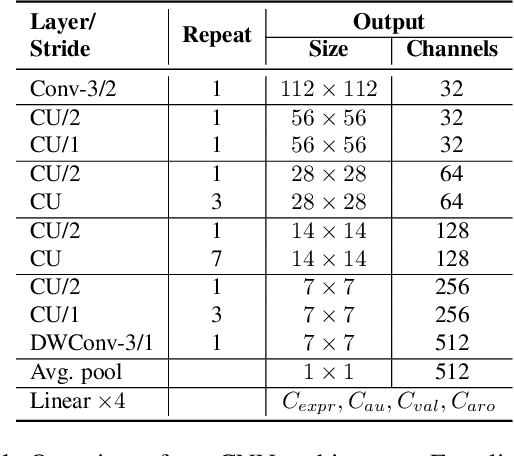

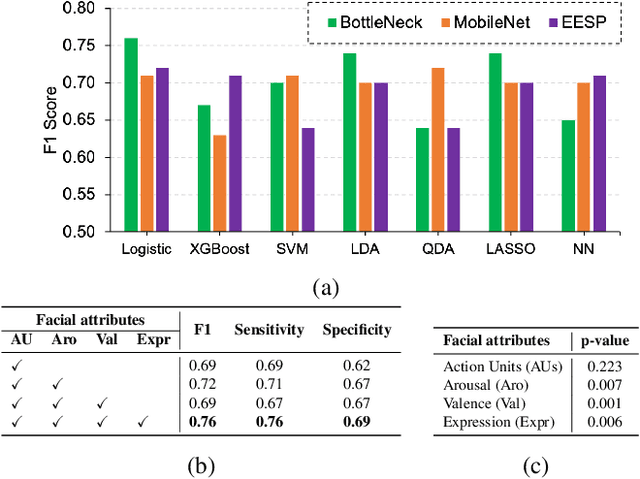
In this paper, we introduce an end-to-end machine learning-based system for classifying autism spectrum disorder (ASD) using facial attributes such as expressions, action units, arousal, and valence. Our system classifies ASD using representations of different facial attributes from convolutional neural networks, which are trained on images in the wild. Our experimental results show that different facial attributes used in our system are statistically significant and improve sensitivity, specificity, and F1 score of ASD classification by a large margin. In particular, the addition of different facial attributes improves the performance of ASD classification by about 7% which achieves a F1 score of 76%.