 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Pattern Structure Using Differentiable Compositing
Oct 17, 2020

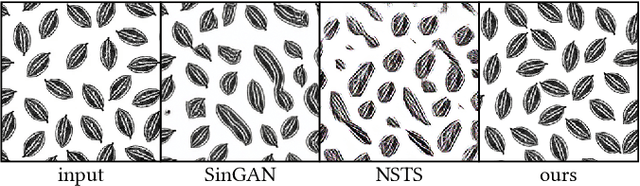
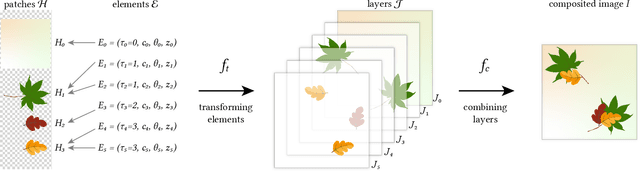
Patterns, which are collections of elements arranged in regular or near-regular arrangements, are an important graphic art form and widely used due to their elegant simplicity and aesthetic appeal. When a pattern is encoded as a flat image without the underlying structure, manually editing the pattern is tedious and challenging as one has to both preserve the individual element shapes and their original relative arrangements. State-of-the-art deep learning frameworks that operate at the pixel level are unsuitable for manipulating such patterns. Specifically, these methods can easily disturb the shapes of the individual elements or their arrangement, and thus fail to preserve the latent structures of the input patterns. We present a novel differentiable compositing operator using pattern elements and use it to discover structures, in the form of a layered representation of graphical objects, directly from raw pattern images. This operator allows us to adapt current deep learning based image methods to effectively handle patterns. We evaluate our method on a range of patterns and demonstrate superiority in the context of pattern manipulations when compared against state-of-the-art
Real-Time Lip Sync for Live 2D Animation
Oct 19, 2019
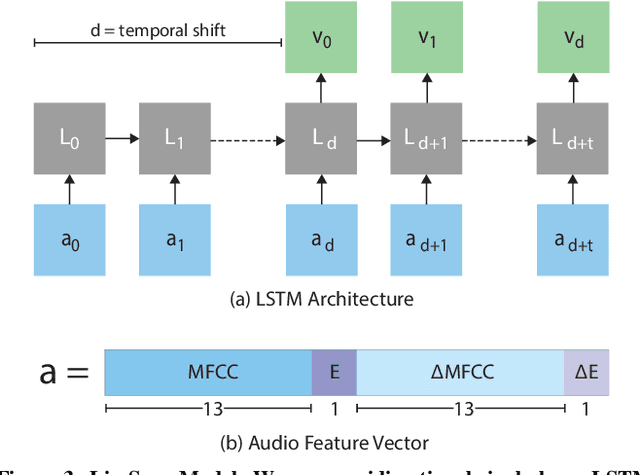
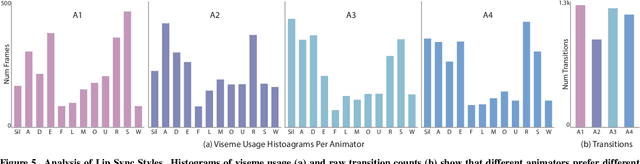
The emergence of commercial tools for real-time performance-based 2D animation has enabled 2D characters to appear on live broadcasts and streaming platforms. A key requirement for live animation is fast and accurate lip sync that allows characters to respond naturally to other actors or the audience through the voice of a human performer. In this work, we present a deep learning based interactive system that automatically generates live lip sync for layered 2D characters using a Long Short Term Memory (LSTM) model. Our system takes streaming audio as input and produces viseme sequences with less than 200ms of latency (including processing time). Our contributions include specific design decisions for our feature definition and LSTM configuration that provide a small but useful amount of lookahead to produce accurate lip sync. We also describe a data augmentation procedure that allows us to achieve good results with a very small amount of hand-animated training data (13-20 minutes). Extensive human judgement experiments show that our results are preferred over several competing methods, including those that only support offline (non-live) processing. Video summary and supplementary results at GitHub link: https://github.com/deepalianeja/CharacterLipSync2D
DepthCut: Improved Depth Edge Estimation Using Multiple Unreliable Channels
May 26, 2017



In the context of scene understanding, a variety of methods exists to estimate different information channels from mono or stereo images, including disparity, depth, and normals. Although several advances have been reported in the recent years for these tasks, the estimated information is often imprecise particularly near depth discontinuities or creases. Studies have however shown that precisely such depth edges carry critical cues for the perception of shape, and play important roles in tasks like depth-based segmentation or foreground selection. Unfortunately, the currently extracted channels often carry conflicting signals, making it difficult for subsequent applications to effectively use them. In this paper, we focus on the problem of obtaining high-precision depth edges (i.e., depth contours and creases) by jointly analyzing such unreliable information channels. We propose DepthCut, a data-driven fusion of the channels using a convolutional neural network trained on a large dataset with known depth. The resulting depth edges can be used for segmentation, decomposing a scene into depth layers with relatively flat depth, or improving the accuracy of the depth estimate near depth edges by constraining its gradients to agree with these edges. Quantitatively, we compare against 15 variants of baselines and demonstrate that our depth edges result in an improved segmentation performance and an improved depth estimate near depth edges compared to data-agnostic channel fusion. Qualitatively, we demonstrate that the depth edges result in superior segmentation and depth orderings.