 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automatic Soccer Commentary Generation with Knowledge-Enhanced Visual Reasoning
Mar 31, 2026Soccer commentary plays a crucial role in enhancing the soccer game viewing experience for audiences. Previous studies in automatic soccer commentary generation typically adopt an end-to-end method to generate anonymous live text commentary. Such generated commentary is insufficient in the context of real-world live televised commentary, as it contains anonymous entities, context-dependent errors and lacks statistical insights of the game events. To bridge the gap, we propose GameSight, a two-stage model to address soccer commentary generation as a knowledge-enhanced visual reasoning task, enabling live-televised-like knowledgeable commentary with accurate reference to entities (players and teams). GameSight starts by performing visual reasoning to align anonymous entities with fine-grained visual and contextual analysis. Subsequently, the entity-aligned commentary is refined with knowledge by incorporating external historical statistics and iteratively updated internal game state information. Consequently, GameSight improves the player alignment accuracy by 18.5% on SN-Caption-test-align dataset compared to Gemini 2.5-pro. Combined with further knowledge enhancement, GameSight outperforms in segment-level accuracy and commentary quality, as well as game-level contextual relevance and structural composition. We believe that our work paves the way for a more informative and engaging human-centric experience with the AI sports application. Demo Page: https://gamesight2025.github.io/gamesight2025
VoxInstruct: Expressive Human Instruction-to-Speech Generation with Unified Multilingual Codec Language Modelling
Aug 28, 2024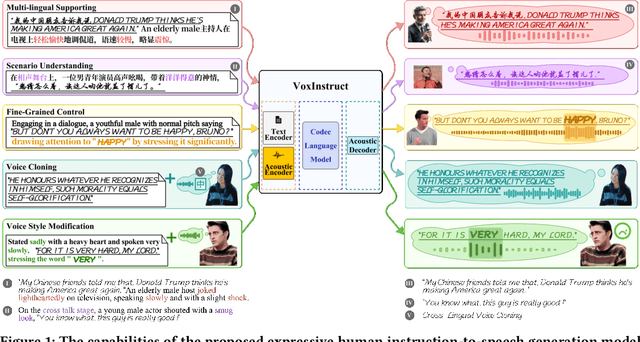

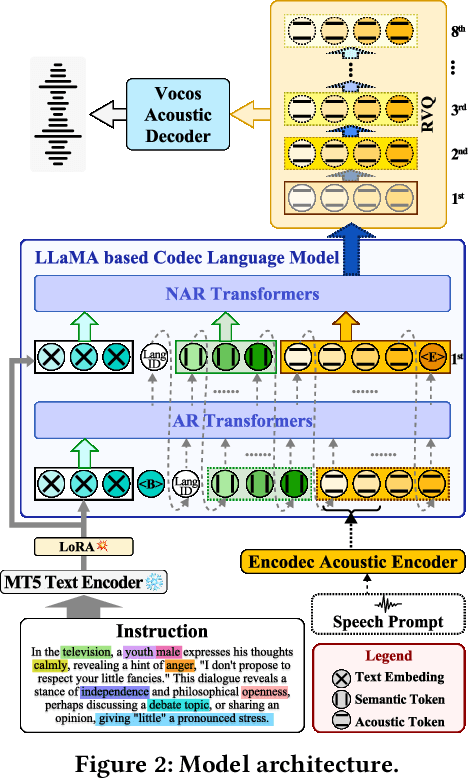

Recent AIGC systems possess the capability to generate digital multimedia content based on human language instructions, such as text, image and video. However, when it comes to speech, existing methods related to human instruction-to-speech generation exhibit two limitations. Firstly, they require the division of inputs into content prompt (transcript) and description prompt (style and speaker), instead of directly supporting human instruction. This division is less natural in form and does not align with other AIGC models. Secondly, the practice of utilizing an independent description prompt to model speech style, without considering the transcript content, restricts the ability to control speech at a fine-grained level. To address these limitations, we propose VoxInstruct, a novel unified multilingual codec language modeling framework that extends traditional text-to-speech tasks into a general human instruction-to-speech task. Our approach enhances the expressiveness of human instruction-guided speech generation and aligns the speech generation paradigm with other modalities. To enable the model to automatically extract the content of synthesized speech from raw text instructions, we introduce speech semantic tokens as an intermediate representation for instruction-to-content guidance. We also incorporate multiple Classifier-Free Guidance (CFG) strategies into our codec language model, which strengthens the generated speech following human instructions. Furthermore, our model architecture and training strategies allow for the simultaneous support of combining speech prompt and descriptive human instruction for expressive speech synthesis, which is a first-of-its-kind attempt. Codes, models and demos are at: https://github.com/thuhcsi/VoxInstruct.
Speech-Driven 3D Face Animation with Composite and Regional Facial Movements
Aug 10, 2023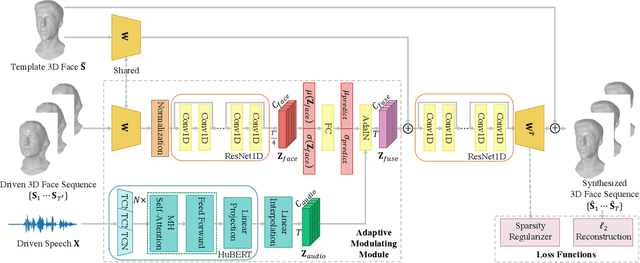
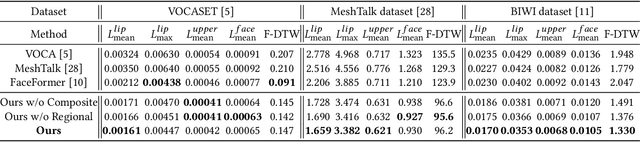
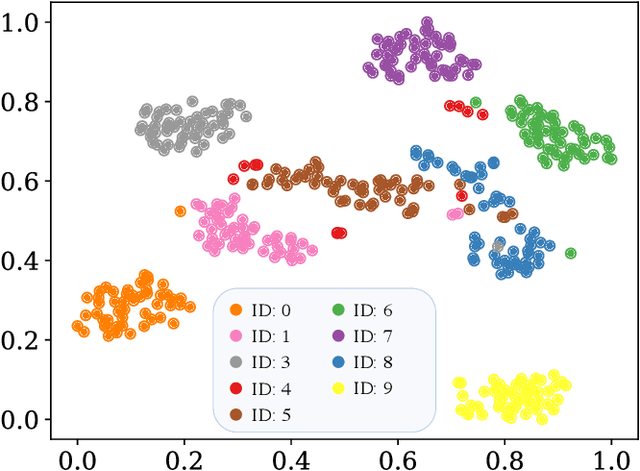
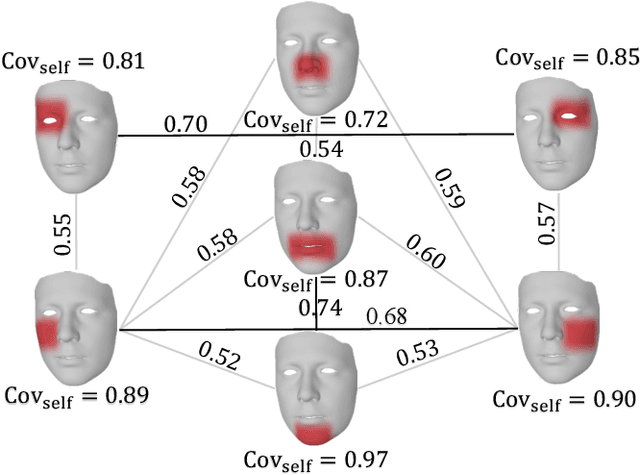
Speech-driven 3D face animation poses significant challenges due to the intricacy and variability inherent in human facial movements. This paper emphasizes the importance of considering both the composite and regional natures of facial movements in speech-driven 3D face animation. The composite nature pertains to how speech-independent factors globally modulate speech-driven facial movements along the temporal dimension. Meanwhile, the regional nature alludes to the notion that facial movements are not globally correlated but are actuated by local musculature along the spatial dimension. It is thus indispensable to incorporate both natures for engendering vivid animation. To address the composite nature, we introduce an adaptive modulation module that employs arbitrary facial movements to dynamically adjust speech-driven facial movements across frames on a global scale. To accommodate the regional nature, our approach ensures that each constituent of the facial features for every frame focuses on the local spatial movements of 3D faces. Moreover, we present a non-autoregressive backbone for translating audio to 3D facial movements, which maintains high-frequency nuances of facial movements and facilitates efficient inference. Comprehensive experiments and user studies demonstrate that our method surpasses contemporary state-of-the-art approaches both qualitatively and quantitatively.