 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Geometry Mismatch: Frequency-Aware Anisotropic Serialization for Thin-Structure SSMs
Mar 30, 2026The segmentation of thin linear structures is inherently topology allowbreak-critical, where minor local errors can sever long-range connectivity. While recent State-Space Models (SSMs) offer efficient long-range modeling, their isotropic serialization (e.g., raster scanning) creates a geometry mismatch for anisotropic targets, causing state propagation across rather than along the structure trajectories. To address this, we propose FGOS-Net, a framework based on frequency allowbreak-geometric disentanglement. We first decompose features into a stable topology carrier and directional high-frequency bands, leveraging the latter to explicitly correct spatial misalignments induced by downsampling. Building on this calibrated topology, we introduce frequency-aligned scanning that elevates serialization to a geometry-conditioned decision, preserving direction-consistent traces. Coupled with an active probing strategy to selectively inject high-frequency details and suppress texture ambiguity, FGOS-Net consistently outperforms strong baselines across four challenging benchmarks. Notably, it achieves 91.3% mIoU and 97.1% clDice on DeepCrack while running at 80 FPS with only 7.87 GFLOPs.
Fluxamba: Topology-Aware Anisotropic State Space Models for Geological Lineament Segmentation in Multi-Source Remote Sensing
Jan 24, 2026The precise segmentation of geological linear features, spanning from planetary lineaments to terrestrial fractures, demands capturing long-range dependencies across complex anisotropic topologies. Although State Space Models (SSMs) offer near-linear computational complexity, their dependence on rigid, axis-aligned scanning trajectories induces a fundamental topological mismatch with curvilinear targets, resulting in fragmented context and feature erosion. To bridge this gap, we propose Fluxamba, a lightweight architecture that introduces a topology-aware feature rectification framework. Central to our design is the Structural Flux Block (SFB), which orchestrates an anisotropic information flux by integrating an Anisotropic Structural Gate (ASG) with a Prior-Modulated Flow (PMF). This mechanism decouples feature orientation from spatial location, dynamically gating context aggregation along the target's intrinsic geometry rather than rigid paths. Furthermore, to mitigate serialization-induced noise in low-contrast environments, we incorporate a Hierarchical Spatial Regulator (HSR) for multi-scale semantic alignment and a High-Fidelity Focus Unit (HFFU) to explicitly maximize the signal-to-noise ratio of faint features. Extensive experiments on diverse geological benchmarks (LROC-Lineament, LineaMapper, and GeoCrack) demonstrate that Fluxamba establishes a new state-of-the-art. Notably, on the challenging LROC-Lineament dataset, it achieves an F1-score of 89.22% and mIoU of 89.87%. Achieving a real-time inference speed of over 24 FPS with only 3.4M parameters and 6.3G FLOPs, Fluxamba reduces computational costs by up to two orders of magnitude compared to heavy-weight baselines, thereby establishing a new Pareto frontier between segmentation fidelity and onboard deployment feasibility.
Unsupervised Cross-Domain Regression for Fine-grained 3D Game Character Reconstruction
Dec 11, 2024With the rise of the ``metaverse'' and the rapid development of games, it has become more and more critical to reconstruct characters in the virtual world faithfully. The immersive experience is one of the most central themes of the ``metaverse'', while the reducibility of the avatar is the crucial point. Meanwhile, the game is the carrier of the metaverse, in which players can freely edit the facial appearance of the game character. In this paper, we propose a simple but powerful cross-domain framework that can reconstruct fine-grained 3D game characters from single-view images in an end-to-end manner. Different from the previous methods, which do not resolve the cross-domain gap, we propose an effective regressor that can greatly reduce the discrepancy between the real-world domain and the game domain. To figure out the drawbacks of no ground truth, our unsupervised framework has accomplished the knowledge transfer of the target domain. Additionally, an innovative contrastive loss is proposed to solve the instance-wise disparity, which keeps the person-specific details of the reconstructed character. In contrast, an auxiliary 3D identity-aware extractor is activated to make the results of our model more impeccable. Then a large set of physically meaningful facial parameters is generated robustly and exquisitely. Experiments demonstrate that our method yields state-of-the-art performance in 3D game character reconstruction.
Tactile Aware Dynamic Obstacle Avoidance in Crowded Environment with Deep Reinforcement Learning
Jun 19, 2024Mobile robots operating in crowded environments require the ability to navigate among humans and surrounding obstacles efficiently while adhering to safety standards and socially compliant mannerisms. This scale of the robot navigation problem may be classified as both a local path planning and trajectory optimization problem. This work presents an array of force sensors that act as a tactile layer to complement the use of a LiDAR for the purpose of inducing awareness of contact with any surrounding objects within immediate vicinity of a mobile robot undetected by LiDARs. By incorporating the tactile layer, the robot can take more risks in its movements and possibly go right up to an obstacle or wall, and gently squeeze past it. In addition, we built up a simulation platform via Pybullet which integrates Robot Operating System (ROS) and reinforcement learning (RL) together. A touch-aware neural network model was trained on it to create an RL-based local path planner for dynamic obstacle avoidance. Our proposed method was demonstrated successfully on an omni-directional mobile robot who was able to navigate in a crowded environment with high agility and versatility in movement, while not being overly sensitive to nearby obstacles-not-in-contact.
Depth Awakens: A Depth-perceptual Attention Fusion Network for RGB-D Camouflaged Object Detection
May 09, 2024
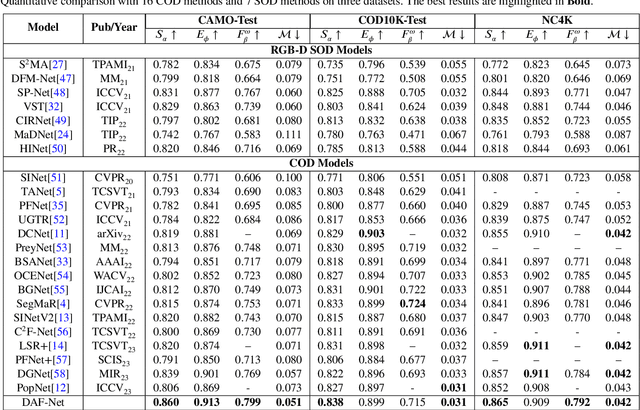
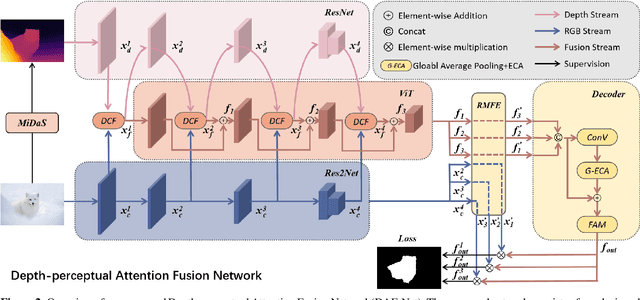

Camouflaged object detection (COD) presents a persistent challenge in accurately identifying objects that seamlessly blend into their surroundings. However, most existing COD models overlook the fact that visual systems operate within a genuine 3D environment. The scene depth inherent in a single 2D image provides rich spatial clues that can assist in the detection of camouflaged objects. Therefore, we propose a novel depth-perception attention fusion network that leverages the depth map as an auxiliary input to enhance the network's ability to perceive 3D information, which is typically challenging for the human eye to discern from 2D images. The network uses a trident-branch encoder to extract chromatic and depth information and their communications. Recognizing that certain regions of a depth map may not effectively highlight the camouflaged object, we introduce a depth-weighted cross-attention fusion module to dynamically adjust the fusion weights on depth and RGB feature maps. To keep the model simple without compromising effectiveness, we design a straightforward feature aggregation decoder that adaptively fuses the enhanced aggregated features. Experiments demonstrate the significant superiority of our proposed method over other states of the arts, which further validates the contribution of depth information in camouflaged object detection. The code will be available at https://github.com/xinran-liu00/DAF-Net.
Speech-Driven 3D Face Animation with Composite and Regional Facial Movements
Aug 10, 2023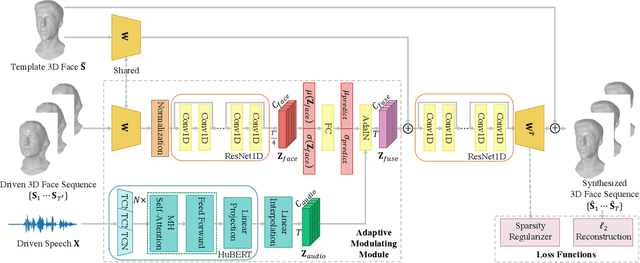
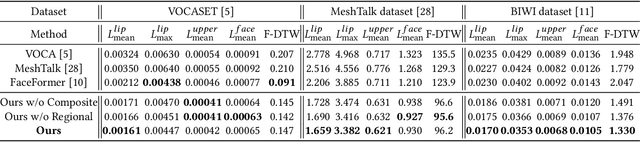
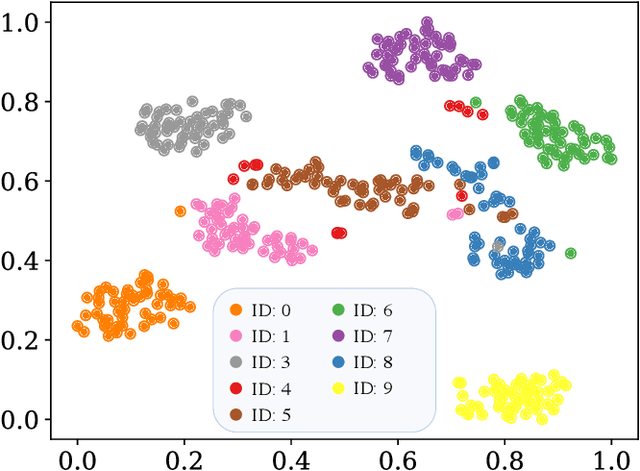
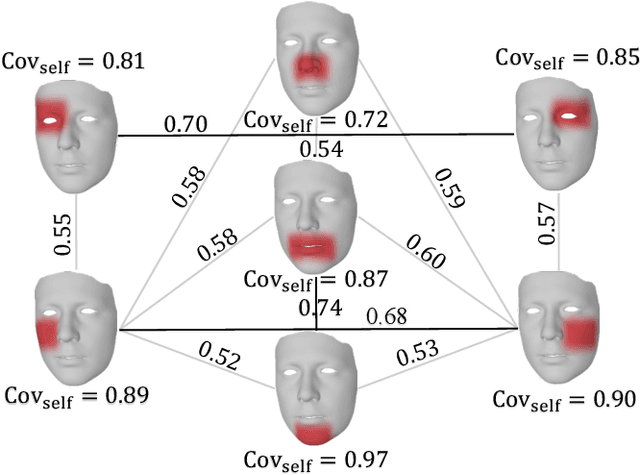
Speech-driven 3D face animation poses significant challenges due to the intricacy and variability inherent in human facial movements. This paper emphasizes the importance of considering both the composite and regional natures of facial movements in speech-driven 3D face animation. The composite nature pertains to how speech-independent factors globally modulate speech-driven facial movements along the temporal dimension. Meanwhile, the regional nature alludes to the notion that facial movements are not globally correlated but are actuated by local musculature along the spatial dimension. It is thus indispensable to incorporate both natures for engendering vivid animation. To address the composite nature, we introduce an adaptive modulation module that employs arbitrary facial movements to dynamically adjust speech-driven facial movements across frames on a global scale. To accommodate the regional nature, our approach ensures that each constituent of the facial features for every frame focuses on the local spatial movements of 3D faces. Moreover, we present a non-autoregressive backbone for translating audio to 3D facial movements, which maintains high-frequency nuances of facial movements and facilitates efficient inference. Comprehensive experiments and user studies demonstrate that our method surpasses contemporary state-of-the-art approaches both qualitatively and quantitatively.
ZiGAN: Fine-grained Chinese Calligraphy Font Generation via a Few-shot Style Transfer Approach
Aug 08, 2021
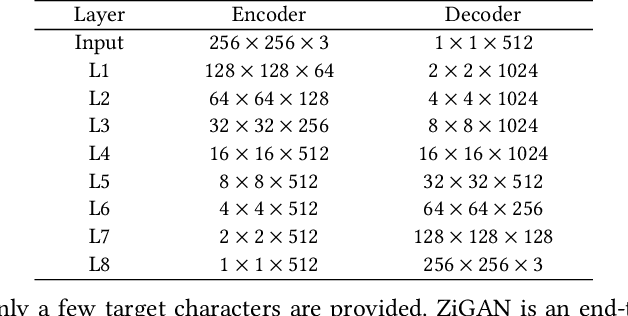
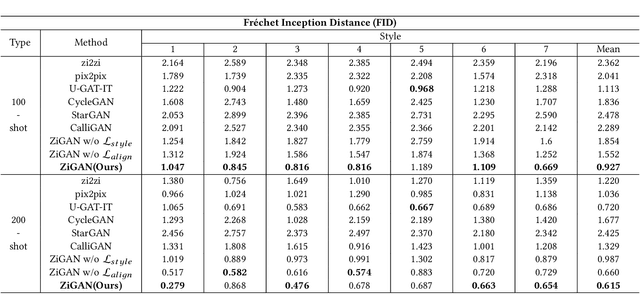

Chinese character style transfer is a very challenging problem because of the complexity of the glyph shapes or underlying structures and large numbers of existed characters, when comparing with English letters. Moreover, the handwriting of calligraphy masters has a more irregular stroke and is difficult to obtain in real-world scenarios. Recently, several GAN-based methods have been proposed for font synthesis, but some of them require numerous reference data and the other part of them have cumbersome preprocessing steps to divide the character into different parts to be learned and transferred separately. In this paper, we propose a simple but powerful end-to-end Chinese calligraphy font generation framework ZiGAN, which does not require any manual operation or redundant preprocessing to generate fine-grained target-style characters with few-shot references. To be specific, a few paired samples from different character styles are leveraged to attain a fine-grained correlation between structures underlying different glyphs. To capture valuable style knowledge in target and strengthen the coarse-grained understanding of character content, we utilize multiple unpaired samples to align the feature distributions belonging to different character styles. By doing so, only a few target Chinese calligraphy characters are needed to generated expected style transferred characters. Experiments demonstrate that our method has a state-of-the-art generalization ability in few-shot Chinese character style transfer.
PSCNet: Pyramidal Scale and Global Context Guided Network for Crowd Counting
Dec 07, 2020

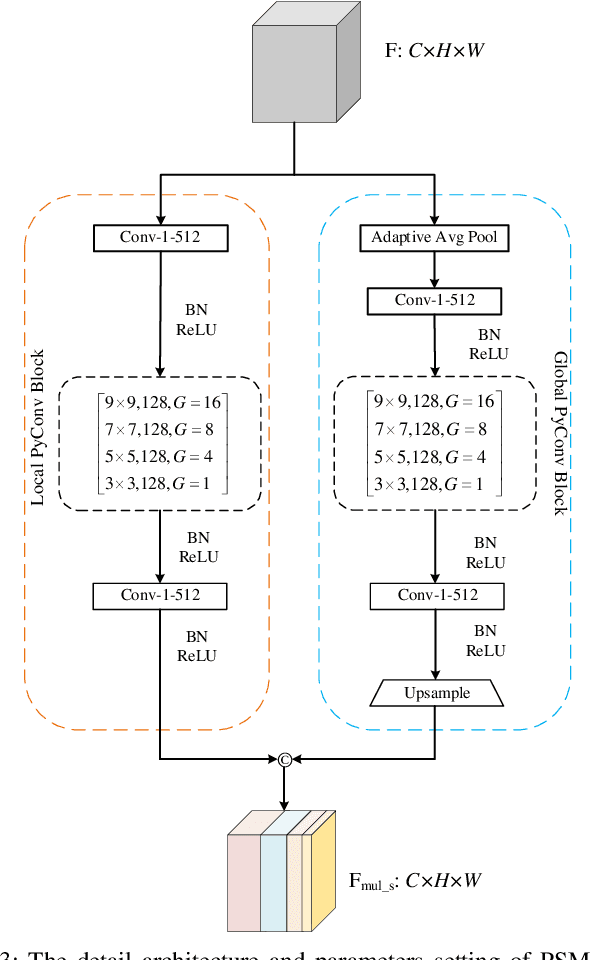
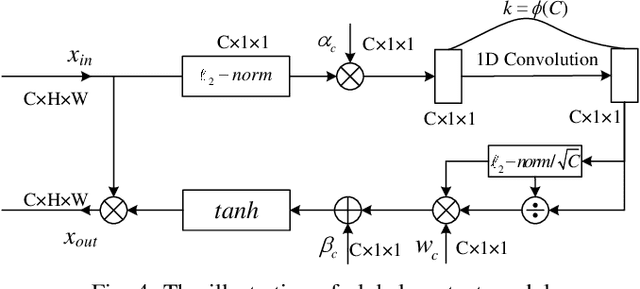
Crowd counting, which towards to accurately count the number of the objects in images, has been attracted more and more attention by researchers recently. However, challenges from severely occlusion, large scale variation, complex background interference and non-uniform density distribution, limit the crowd number estimation accuracy. To mitigate above issues, this paper proposes a novel crowd counting approach based on pyramidal scale module (PSM) and global context module (GCM), dubbed PSCNet. Moreover, a reliable supervision manner combined Bayesian and counting loss (BCL) is utilized to learn the density probability and then computes the count exception at each annotation point. Specifically, PSM is used to adaptively capture multi-scale information, which can identify a fine boundary of crowds with different image scales. GCM is devised with low-complexity and lightweight manner, to make the interactive information across the channels of the feature maps more efficient, meanwhile guide the model to select more suitable scales generated from PSM. Furthermore, BL is leveraged to construct a credible density contribution probability supervision manner, which relieves non-uniform density distribution in crowds to a certain extent. Extensive experiments on four crowd counting datasets show the effectiveness and superiority of the proposed model. Additionally, some experiments extended on a remote sensing object counting (RSOC) dataset further validate the generalization ability of the model. Our resource code will be released upon the acceptance of this work.
Deep Residual Correction Network for Partial Domain Adaptation
Apr 10, 2020


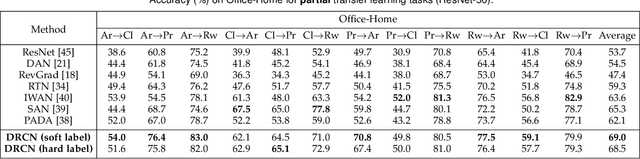
Deep domain adaptation methods have achieved appealing performance by learning transferable representations from a well-labeled source domain to a different but related unlabeled target domain. Most existing works assume source and target data share the identical label space, which is often difficult to be satisfied in many real-world applications. With the emergence of big data, there is a more practical scenario called partial domain adaptation, where we are always accessible to a more large-scale source domain while working on a relative small-scale target domain. In this case, the conventional domain adaptation assumption should be relaxed, and the target label space tends to be a subset of the source label space. Intuitively, reinforcing the positive effects of the most relevant source subclasses and reducing the negative impacts of irrelevant source subclasses are of vital importance to address partial domain adaptation challenge. This paper proposes an efficiently-implemented Deep Residual Correction Network (DRCN) by plugging one residual block into the source network along with the task-specific feature layer, which effectively enhances the adaptation from source to target and explicitly weakens the influence from the irrelevant source classes. Specifically, the plugged residual block, which consists of several fully-connected layers, could deepen basic network and boost its feature representation capability correspondingly. Moreover, we design a weighted class-wise domain alignment loss to couple two domains by matching the feature distributions of shared classes between source and target. Comprehensive experiments on partial, traditional and fine-grained cross-domain visual recognition demonstrate that DRCN is superior to the competitive deep domain adaptation approaches.