 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Data Enhanced Vision-Language Model for Traffic Scene Understanding
Nov 12, 2025Nowadays, navigation and ride-sharing apps have collected numerous images with spatio-temporal data. A core technology for analyzing such images, associated with spatiotemporal information, is Traffic Scene Understanding (TSU), which aims to provide a comprehensive description of the traffic scene. Unlike traditional spatio-temporal data analysis tasks, the dependence on both spatio-temporal and visual-textual data introduces distinct challenges to TSU task. However, recent research often treats TSU as a common image understanding task, ignoring the spatio-temporal information and overlooking the interrelations between different aspects of the traffic scene. To address these issues, we propose a novel SpatioTemporal Enhanced Model based on CILP (ST-CLIP) for TSU. Our model uses the classic vision-language model, CLIP, as the backbone, and designs a Spatio-temporal Context Aware Multiaspect Prompt (SCAMP) learning method to incorporate spatiotemporal information into TSU. The prompt learning method consists of two components: A dynamic spatio-temporal context representation module that extracts representation vectors of spatio-temporal data for each traffic scene image, and a bi-level ST-aware multi-aspect prompt learning module that integrates the ST-context representation vectors into word embeddings of prompts for the CLIP model. The second module also extracts low-level visual features and image-wise high-level semantic features to exploit interactive relations among different aspects of traffic scenes. To the best of our knowledge, this is the first attempt to integrate spatio-temporal information into visionlanguage models to facilitate TSU task. Experiments on two realworld datasets demonstrate superior performance in the complex scene understanding scenarios with a few-shot learning strategy.
Policy Regularization on Globally Accessible States in Cross-Dynamics Reinforcement Learning
Mar 10, 2025To learn from data collected in diverse dynamics, Imitation from Observation (IfO) methods leverage expert state trajectories based on the premise that recovering expert state distributions in other dynamics facilitates policy learning in the current one. However, Imitation Learning inherently imposes a performance upper bound of learned policies. Additionally, as the environment dynamics change, certain expert states may become inaccessible, rendering their distributions less valuable for imitation. To address this, we propose a novel framework that integrates reward maximization with IfO, employing F-distance regularized policy optimization. This framework enforces constraints on globally accessible states--those with nonzero visitation frequency across all considered dynamics--mitigating the challenge posed by inaccessible states. By instantiating F-distance in different ways, we derive two theoretical analysis and develop a practical algorithm called Accessible State Oriented Policy Regularization (ASOR). ASOR serves as a general add-on module that can be incorporated into various RL approaches, including offline RL and off-policy RL. Extensive experiments across multiple benchmarks demonstrate ASOR's effectiveness in enhancing state-of-the-art cross-domain policy transfer algorithms, significantly improving their performance.
Video Diffusion Transformers are In-Context Learners
Dec 14, 2024


This paper investigates a solution for enabling in-context capabilities of video diffusion transformers, with minimal tuning required for activation. Specifically, we propose a simple pipeline to leverage in-context generation: ($\textbf{i}$) concatenate videos along spacial or time dimension, ($\textbf{ii}$) jointly caption multi-scene video clips from one source, and ($\textbf{iii}$) apply task-specific fine-tuning using carefully curated small datasets. Through a series of diverse controllable tasks, we demonstrate qualitatively that existing advanced text-to-video models can effectively perform in-context generation. Notably, it allows for the creation of consistent multi-scene videos exceeding 30 seconds in duration, without additional computational overhead. Importantly, this method requires no modifications to the original models, results in high-fidelity video outputs that better align with prompt specifications and maintain role consistency. Our framework presents a valuable tool for the research community and offers critical insights for advancing product-level controllable video generation systems. The data, code, and model weights are publicly available at: \url{https://github.com/feizc/Video-In-Context}.
Unsupervised Cross-Domain Regression for Fine-grained 3D Game Character Reconstruction
Dec 11, 2024With the rise of the ``metaverse'' and the rapid development of games, it has become more and more critical to reconstruct characters in the virtual world faithfully. The immersive experience is one of the most central themes of the ``metaverse'', while the reducibility of the avatar is the crucial point. Meanwhile, the game is the carrier of the metaverse, in which players can freely edit the facial appearance of the game character. In this paper, we propose a simple but powerful cross-domain framework that can reconstruct fine-grained 3D game characters from single-view images in an end-to-end manner. Different from the previous methods, which do not resolve the cross-domain gap, we propose an effective regressor that can greatly reduce the discrepancy between the real-world domain and the game domain. To figure out the drawbacks of no ground truth, our unsupervised framework has accomplished the knowledge transfer of the target domain. Additionally, an innovative contrastive loss is proposed to solve the instance-wise disparity, which keeps the person-specific details of the reconstructed character. In contrast, an auxiliary 3D identity-aware extractor is activated to make the results of our model more impeccable. Then a large set of physically meaningful facial parameters is generated robustly and exquisitely. Experiments demonstrate that our method yields state-of-the-art performance in 3D game character reconstruction.
MovieCharacter: A Tuning-Free Framework for Controllable Character Video Synthesis
Oct 28, 2024



Recent advancements in character video synthesis still depend on extensive fine-tuning or complex 3D modeling processes, which can restrict accessibility and hinder real-time applicability. To address these challenges, we propose a simple yet effective tuning-free framework for character video synthesis, named MovieCharacter, designed to streamline the synthesis process while ensuring high-quality outcomes. Our framework decomposes the synthesis task into distinct, manageable modules: character segmentation and tracking, video object removal, character motion imitation, and video composition. This modular design not only facilitates flexible customization but also ensures that each component operates collaboratively to effectively meet user needs. By leveraging existing open-source models and integrating well-established techniques, MovieCharacter achieves impressive synthesis results without necessitating substantial resources or proprietary datasets. Experimental results demonstrate that our framework enhances the efficiency, accessibility, and adaptability of character video synthesis, paving the way for broader creative and interactive applications.
LucidFusion: Generating 3D Gaussians with Arbitrary Unposed Images
Oct 21, 2024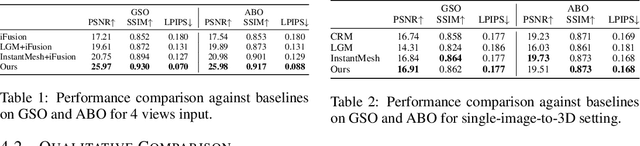
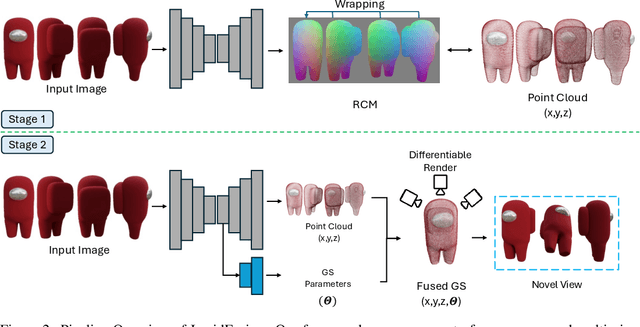

Recent large reconstruction models have made notable progress in generating high-quality 3D objects from single images. However, these methods often struggle with controllability, as they lack information from multiple views, leading to incomplete or inconsistent 3D reconstructions. To address this limitation, we introduce LucidFusion, a flexible end-to-end feed-forward framework that leverages the Relative Coordinate Map (RCM). Unlike traditional methods linking images to 3D world thorough pose, LucidFusion utilizes RCM to align geometric features coherently across different views, making it highly adaptable for 3D generation from arbitrary, unposed images. Furthermore, LucidFusion seamlessly integrates with the original single-image-to-3D pipeline, producing detailed 3D Gaussians at a resolution of $512 \times 512$, making it well-suited for a wide range of applications.
SkyScript-100M: 1,000,000,000 Pairs of Scripts and Shooting Scripts for Short Drama
Aug 18, 2024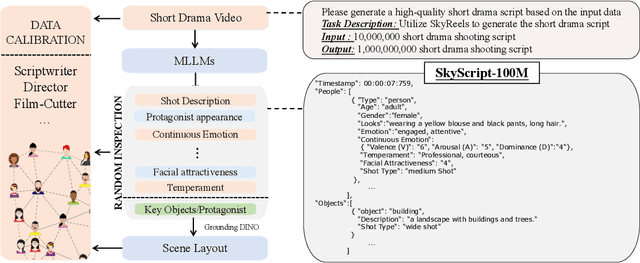
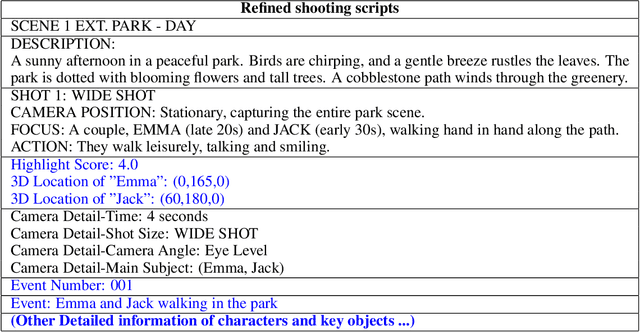
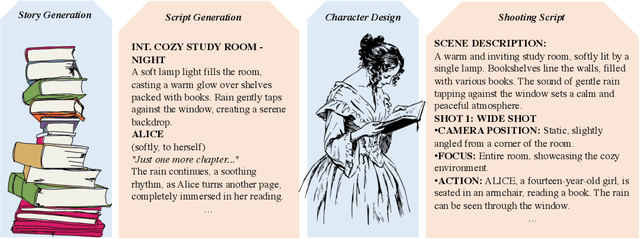
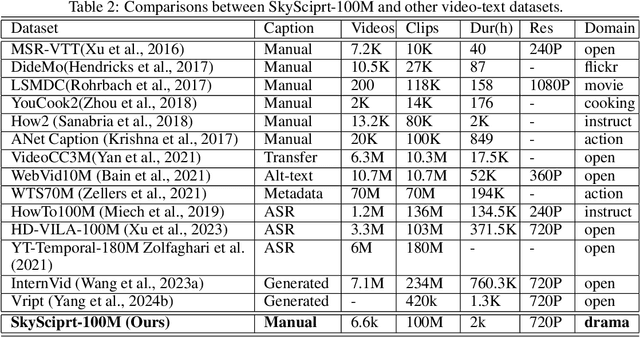
Generating high-quality shooting scripts containing information such as scene and shot language is essential for short drama script generation. We collect 6,660 popular short drama episodes from the Internet, each with an average of 100 short episodes, and the total number of short episodes is about 80,000, with a total duration of about 2,000 hours and totaling 10 terabytes (TB). We perform keyframe extraction and annotation on each episode to obtain about 10,000,000 shooting scripts. We perform 100 script restorations on the extracted shooting scripts based on our self-developed large short drama generation model SkyReels. This leads to a dataset containing 1,000,000,000 pairs of scripts and shooting scripts for short dramas, called SkyScript-100M. We compare SkyScript-100M with the existing dataset in detail and demonstrate some deeper insights that can be achieved based on SkyScript-100M. Based on SkyScript-100M, researchers can achieve several deeper and more far-reaching script optimization goals, which may drive a paradigm shift in the entire field of text-to-video and significantly advance the field of short drama video generation. The data and code are available at https://github.com/vaew/SkyScript-100M.
InTeX: Interactive Text-to-texture Synthesis via Unified Depth-aware Inpainting
Mar 18, 2024Text-to-texture synthesis has become a new frontier in 3D content creation thanks to the recent advances in text-to-image models. Existing methods primarily adopt a combination of pretrained depth-aware diffusion and inpainting models, yet they exhibit shortcomings such as 3D inconsistency and limited controllability. To address these challenges, we introduce InteX, a novel framework for interactive text-to-texture synthesis. 1) InteX includes a user-friendly interface that facilitates interaction and control throughout the synthesis process, enabling region-specific repainting and precise texture editing. 2) Additionally, we develop a unified depth-aware inpainting model that integrates depth information with inpainting cues, effectively mitigating 3D inconsistencies and improving generation speed. Through extensive experiments, our framework has proven to be both practical and effective in text-to-texture synthesis, paving the way for high-quality 3D content creation.
Speech-Driven 3D Face Animation with Composite and Regional Facial Movements
Aug 10, 2023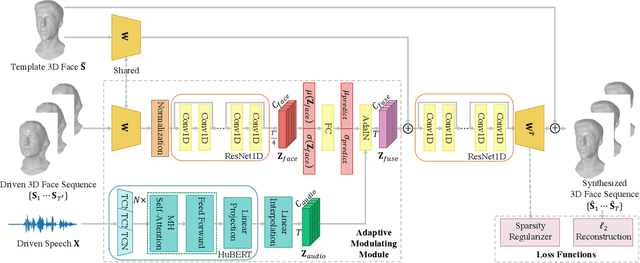
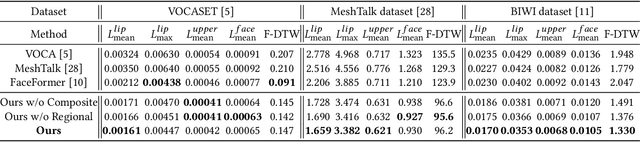
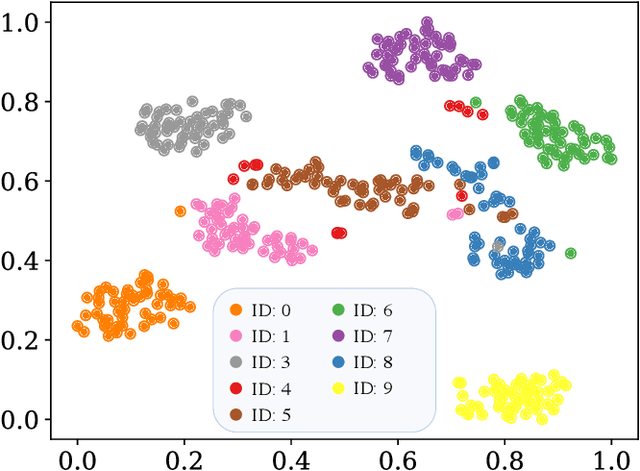
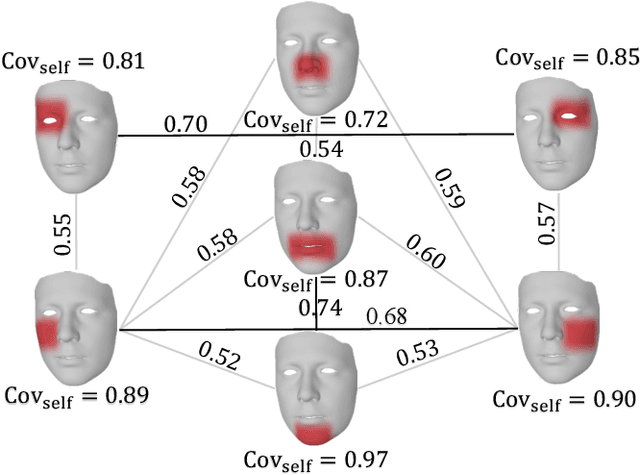
Speech-driven 3D face animation poses significant challenges due to the intricacy and variability inherent in human facial movements. This paper emphasizes the importance of considering both the composite and regional natures of facial movements in speech-driven 3D face animation. The composite nature pertains to how speech-independent factors globally modulate speech-driven facial movements along the temporal dimension. Meanwhile, the regional nature alludes to the notion that facial movements are not globally correlated but are actuated by local musculature along the spatial dimension. It is thus indispensable to incorporate both natures for engendering vivid animation. To address the composite nature, we introduce an adaptive modulation module that employs arbitrary facial movements to dynamically adjust speech-driven facial movements across frames on a global scale. To accommodate the regional nature, our approach ensures that each constituent of the facial features for every frame focuses on the local spatial movements of 3D faces. Moreover, we present a non-autoregressive backbone for translating audio to 3D facial movements, which maintains high-frequency nuances of facial movements and facilitates efficient inference. Comprehensive experiments and user studies demonstrate that our method surpasses contemporary state-of-the-art approaches both qualitatively and quantitatively.
AgileAvatar: Stylized 3D Avatar Creation via Cascaded Domain Bridging
Nov 15, 2022



Stylized 3D avatars have become increasingly prominent in our modern life. Creating these avatars manually usually involves laborious selection and adjustment of continuous and discrete parameters and is time-consuming for average users. Self-supervised approaches to automatically create 3D avatars from user selfies promise high quality with little annotation cost but fall short in application to stylized avatars due to a large style domain gap. We propose a novel self-supervised learning framework to create high-quality stylized 3D avatars with a mix of continuous and discrete parameters. Our cascaded domain bridging framework first leverages a modified portrait stylization approach to translate input selfies into stylized avatar renderings as the targets for desired 3D avatars. Next, we find the best parameters of the avatars to match the stylized avatar renderings through a differentiable imitator we train to mimic the avatar graphics engine. To ensure we can effectively optimize the discrete parameters, we adopt a cascaded relaxation-and-search pipeline. We use a human preference study to evaluate how well our method preserves user identity compared to previous work as well as manual creation. Our results achieve much higher preference scores than previous work and close to those of manual creation. We also provide an ablation study to justify the design choices in our pipeline.