 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentOCR: Reimagining Agent History via Optical Self-Compression
Jan 08, 2026Recent advances in large language models (LLMs) enable agentic systems trained with reinforcement learning (RL) over multi-turn interaction trajectories, but practical deployment is bottlenecked by rapidly growing textual histories that inflate token budgets and memory usage. We introduce AgentOCR, a framework that exploits the superior information density of visual tokens by representing the accumulated observation-action history as a compact rendered image. To make multi-turn rollouts scalable, AgentOCR proposes segment optical caching. By decomposing history into hashable segments and maintaining a visual cache, this mechanism eliminates redundant re-rendering. Beyond fixed rendering, AgentOCR introduces agentic self-compression, where the agent actively emits a compression rate and is trained with compression-aware reward to adaptively balance task success and token efficiency. We conduct extensive experiments on challenging agentic benchmarks, ALFWorld and search-based QA. Remarkably, results demonstrate that AgentOCR preserves over 95\% of text-based agent performance while substantially reducing token consumption (>50\%), yielding consistent token and memory efficiency. Our further analysis validates a 20x rendering speedup from segment optical caching and the effective strategic balancing of self-compression.
CaveAgent: Transforming LLMs into Stateful Runtime Operators
Jan 04, 2026LLM-based agents are increasingly capable of complex task execution, yet current agentic systems remain constrained by text-centric paradigms. Traditional approaches rely on procedural JSON-based function calling, which often struggles with long-horizon tasks due to fragile multi-turn dependencies and context drift. In this paper, we present CaveAgent, a framework that transforms the paradigm from "LLM-as-Text-Generator" to "LLM-as-Runtime-Operator." We introduce a Dual-stream Context Architecture that decouples state management into a lightweight semantic stream for reasoning and a persistent, deterministic Python Runtime stream for execution. In addition to leveraging code generation to efficiently resolve interdependent sub-tasks (e.g., loops, conditionals) in a single step, we introduce \textit{Stateful Runtime Management} in CaveAgent. Distinct from existing code-based approaches that remain text-bound and lack the support for external object injection and retrieval, CaveAgent injects, manipulates, and retrieves complex Python objects (e.g., DataFrames, database connections) that persist across turns. This persistence mechanism acts as a high-fidelity external memory to eliminate context drift, avoid catastrophic forgetting, while ensuring that processed data flows losslessly to downstream applications. Comprehensive evaluations on Tau$^2$-bench, BFCL and various case studies across representative SOTA LLMs demonstrate CaveAgent's superiority. Specifically, our framework achieves a 10.5\% success rate improvement on retail tasks and reduces total token consumption by 28.4\% in multi-turn scenarios. On data-intensive tasks, direct variable storage and retrieval reduces token consumption by 59\%, allowing CaveAgent to handle large-scale data that causes context overflow failures in both JSON-based and Code-based agents.
TimeMaster: Training Time-Series Multimodal LLMs to Reason via Reinforcement Learning
Jun 16, 2025Time-series reasoning remains a significant challenge in multimodal large language models (MLLMs) due to the dynamic temporal patterns, ambiguous semantics, and lack of temporal priors. In this work, we introduce TimeMaster, a reinforcement learning (RL)-based method that enables time-series MLLMs to perform structured, interpretable reasoning directly over visualized time-series inputs and task prompts. TimeMaster adopts a three-part structured output format, reasoning, classification, and domain-specific extension, and is optimized via a composite reward function that aligns format adherence, prediction accuracy, and open-ended insight quality. The model is trained using a two-stage pipeline: we first apply supervised fine-tuning (SFT) to establish a good initialization, followed by Group Relative Policy Optimization (GRPO) at the token level to enable stable and targeted reward-driven improvement in time-series reasoning. We evaluate TimeMaster on the TimerBed benchmark across six real-world classification tasks based on Qwen2.5-VL-3B-Instruct. TimeMaster achieves state-of-the-art performance, outperforming both classical time-series models and few-shot GPT-4o by over 14.6% and 7.3% performance gain, respectively. Notably, TimeMaster goes beyond time-series classification: it also exhibits expert-like reasoning behavior, generates context-aware explanations, and delivers domain-aligned insights. Our results highlight that reward-driven RL can be a scalable and promising path toward integrating temporal understanding into time-series MLLMs.
Bidirectional Distillation: A Mixed-Play Framework for Multi-Agent Generalizable Behaviors
May 16, 2025Population-population generalization is a challenging problem in multi-agent reinforcement learning (MARL), particularly when agents encounter unseen co-players. However, existing self-play-based methods are constrained by the limitation of inside-space generalization. In this study, we propose Bidirectional Distillation (BiDist), a novel mixed-play framework, to overcome this limitation in MARL. BiDist leverages knowledge distillation in two alternating directions: forward distillation, which emulates the historical policies' space and creates an implicit self-play, and reverse distillation, which systematically drives agents towards novel distributions outside the known policy space in a non-self-play manner. In addition, BiDist operates as a concise and efficient solution without the need for the complex and costly storage of past policies. We provide both theoretical analysis and empirical evidence to support BiDist's effectiveness. Our results highlight its remarkable generalization ability across a variety of cooperative, competitive, and social dilemma tasks, and reveal that BiDist significantly diversifies the policy distribution space. We also present comprehensive ablation studies to reinforce BiDist's effectiveness and key success factors. Source codes are available in the supplementary material.
Group-in-Group Policy Optimization for LLM Agent Training
May 16, 2025Recent advances in group-based reinforcement learning (RL) have driven frontier large language models (LLMs) in single-turn tasks like mathematical reasoning. However, their scalability to long-horizon LLM agent training remains limited. Unlike static tasks, agent-environment interactions unfold over many steps and often yield sparse or delayed rewards, making credit assignment across individual steps significantly more challenging. In this work, we propose Group-in-Group Policy Optimization (GiGPO), a novel RL algorithm that achieves fine-grained credit assignment for LLM agents while preserving the appealing properties of group-based RL: critic-free, low memory, and stable convergence. GiGPO introduces a two-level structure for estimating relative advantage: (i) At the episode-level, GiGPO computes macro relative advantages based on groups of complete trajectories; (ii) At the step-level, GiGPO introduces an anchor state grouping mechanism that retroactively constructs step-level groups by identifying repeated environment states across trajectories. Actions stemming from the same state are grouped together, enabling micro relative advantage estimation. This hierarchical structure effectively captures both global trajectory quality and local step effectiveness without relying on auxiliary models or additional rollouts. We evaluate GiGPO on two challenging agent benchmarks, ALFWorld and WebShop, using Qwen2.5-1.5B-Instruct and Qwen2.5-7B-Instruct. Crucially, GiGPO delivers fine-grained per-step credit signals and achieves performance gains of > 12\% on ALFWorld and > 9\% on WebShop over the GRPO baseline: all while maintaining the same GPU memory overhead, identical LLM rollout, and incurring little to no additional time cost.
Towards Efficient Online Tuning of VLM Agents via Counterfactual Soft Reinforcement Learning
May 01, 2025Online fine-tuning vision-language model (VLM) agents with reinforcement learning (RL) has shown promise for equipping agents with multi-step, goal-oriented capabilities in dynamic environments. However, their open-ended textual action space and non-end-to-end nature of action generation present significant challenges to effective online exploration in RL, e.g., explosion of the exploration space. We propose a novel online fine-tuning method, Counterfactual Soft Reinforcement Learning (CoSo), better suited to the textual output space of VLM agents. Compared to prior methods that assign uniform uncertainty to all tokens, CoSo leverages counterfactual reasoning to dynamically assess the causal influence of individual tokens on post-processed actions. By prioritizing the exploration of action-critical tokens while reducing the impact of semantically redundant or low-impact tokens, CoSo enables a more targeted and efficient online rollout process. We provide theoretical analysis proving CoSo's convergence and policy improvement guarantees, and extensive empirical evaluations supporting CoSo's effectiveness. Our results across a diverse set of agent tasks, including Android device control, card gaming, and embodied AI, highlight its remarkable ability to enhance exploration efficiency and deliver consistent performance gains. The code is available at https://github.com/langfengQ/CoSo.
Policy Regularization on Globally Accessible States in Cross-Dynamics Reinforcement Learning
Mar 10, 2025To learn from data collected in diverse dynamics, Imitation from Observation (IfO) methods leverage expert state trajectories based on the premise that recovering expert state distributions in other dynamics facilitates policy learning in the current one. However, Imitation Learning inherently imposes a performance upper bound of learned policies. Additionally, as the environment dynamics change, certain expert states may become inaccessible, rendering their distributions less valuable for imitation. To address this, we propose a novel framework that integrates reward maximization with IfO, employing F-distance regularized policy optimization. This framework enforces constraints on globally accessible states--those with nonzero visitation frequency across all considered dynamics--mitigating the challenge posed by inaccessible states. By instantiating F-distance in different ways, we derive two theoretical analysis and develop a practical algorithm called Accessible State Oriented Policy Regularization (ASOR). ASOR serves as a general add-on module that can be incorporated into various RL approaches, including offline RL and off-policy RL. Extensive experiments across multiple benchmarks demonstrate ASOR's effectiveness in enhancing state-of-the-art cross-domain policy transfer algorithms, significantly improving their performance.
A High Efficient and Scalable Obstacle-Avoiding VLSI Global Routing Flow
Mar 10, 2025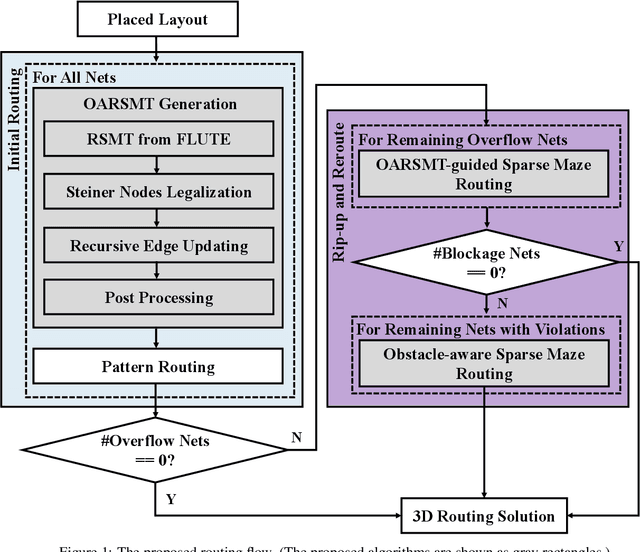

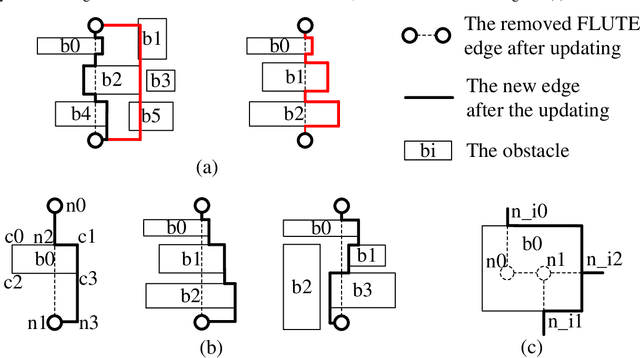

Routing is a crucial step in the VLSI design flow. With the advancement of manufacturing technologies, more constraints have emerged in design rules, particularly regarding obstacles during routing, leading to increased routing complexity. Unfortunately, many global routers struggle to efficiently generate obstacle-free solutions due to the lack of scalable obstacle-avoiding tree generation methods and the capability of handling modern designs with complex obstacles and nets. In this work, we propose an efficient obstacle-aware global routing flow for VLSI designs with obstacles. The flow includes a rule-based obstacle-avoiding rectilinear Steiner minimal tree (OARSMT) algorithm during the tree generation phase. This algorithm is both scalable and fast to provide tree topologies avoiding obstacles in the early stage globally. With its guidance, OARSMT-guided and obstacle-aware sparse maze routing are proposed in the later stages to minimize obstacle violations further and reduce overflow costs. Compared to advanced methods on the benchmark with obstacles, our approach successfully eliminates obstacle violations, and reduces wirelength and overflow cost, while sacrificing only a limited number of via counts and runtime overhead.
Diverse Intra- and Inter-Domain Activity Style Fusion for Cross-Person Generalization in Activity Recognition
Jun 07, 2024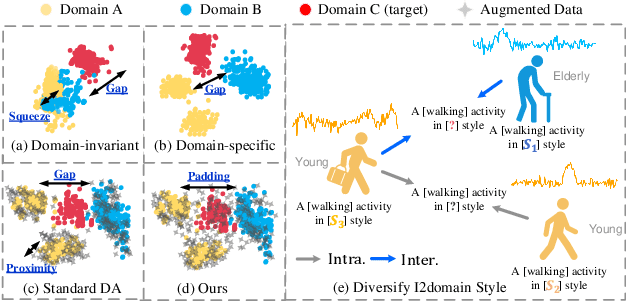
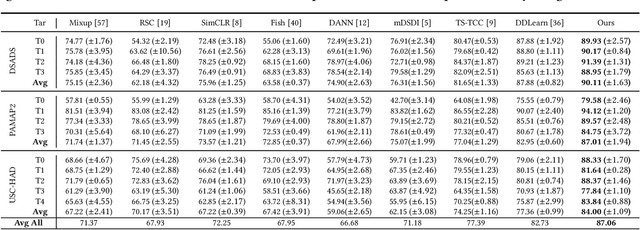
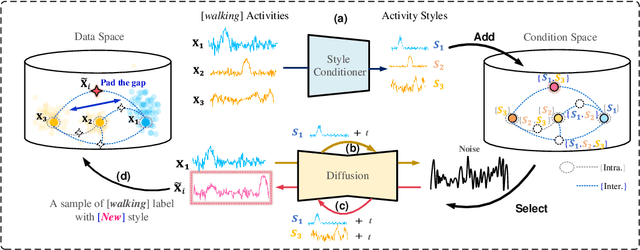
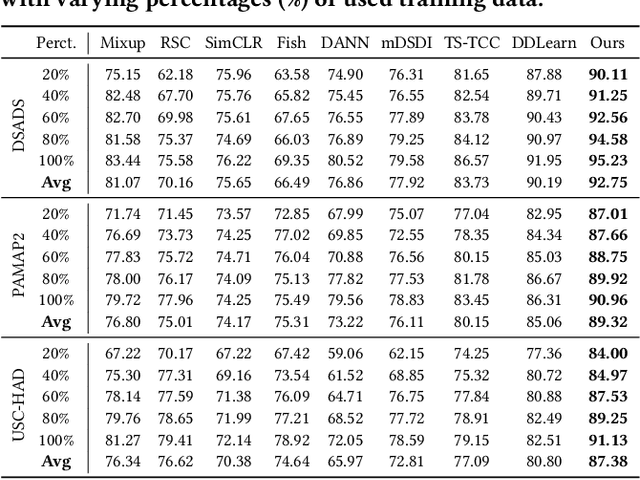
Existing domain generalization (DG) methods for cross-person generalization tasks often face challenges in capturing intra- and inter-domain style diversity, resulting in domain gaps with the target domain. In this study, we explore a novel perspective to tackle this problem, a process conceptualized as domain padding. This proposal aims to enrich the domain diversity by synthesizing intra- and inter-domain style data while maintaining robustness to class labels. We instantiate this concept using a conditional diffusion model and introduce a style-fused sampling strategy to enhance data generation diversity. In contrast to traditional condition-guided sampling, our style-fused sampling strategy allows for the flexible use of one or more random styles to guide data synthesis. This feature presents a notable advancement: it allows for the maximum utilization of possible permutations and combinations among existing styles to generate a broad spectrum of new style instances. Empirical evaluations on a board of datasets demonstrate that our generated data achieves remarkable diversity within the domain space. Both intra- and inter-domain generated data have proven to be significant and valuable, contributing to varying degrees of performance enhancements. Notably, our approach outperforms state-of-the-art DG methods in all human activity recognition tasks.
Resisting Stochastic Risks in Diffusion Planners with the Trajectory Aggregation Tree
May 28, 2024Diffusion planners have shown promise in handling long-horizon and sparse-reward tasks due to the non-autoregressive plan generation. However, their inherent stochastic risk of generating infeasible trajectories presents significant challenges to their reliability and stability. We introduce a novel approach, the Trajectory Aggregation Tree (TAT), to address this issue in diffusion planners. Compared to prior methods that rely solely on raw trajectory predictions, TAT aggregates information from both historical and current trajectories, forming a dynamic tree-like structure. Each trajectory is conceptualized as a branch and individual states as nodes. As the structure evolves with the integration of new trajectories, unreliable states are marginalized, and the most impactful nodes are prioritized for decision-making. TAT can be deployed without modifying the original training and sampling pipelines of diffusion planners, making it a training-free, ready-to-deploy solution. We provide both theoretical analysis and empirical evidence to support TAT's effectiveness. Our results highlight its remarkable ability to resist the risk from unreliable trajectories, guarantee the performance boosting of diffusion planners in $100\%$ of tasks, and exhibit an appreciable tolerance margin for sample quality, thereby enabling planning with a more than $3\times$ acceleration.