 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrontierCS: Evolving Challenges for Evolving Intelligence
Dec 17, 2025



We introduce FrontierCS, a benchmark of 156 open-ended problems across diverse areas of computer science, designed and reviewed by experts, including CS PhDs and top-tier competitive programming participants and problem setters. Unlike existing benchmarks that focus on tasks with known optimal solutions, FrontierCS targets problems where the optimal solution is unknown, but the quality of a solution can be objectively evaluated. Models solve these tasks by implementing executable programs rather than outputting a direct answer. FrontierCS includes algorithmic problems, which are often NP-hard variants of competitive programming problems with objective partial scoring, and research problems with the same property. For each problem we provide an expert reference solution and an automatic evaluator. Combining open-ended design, measurable progress, and expert curation, FrontierCS provides a benchmark at the frontier of computer-science difficulty. Empirically, we find that frontier reasoning models still lag far behind human experts on both the algorithmic and research tracks, that increasing reasoning budgets alone does not close this gap, and that models often over-optimize for generating merely workable code instead of discovering high-quality algorithms and system designs.
Bidirectional Distillation: A Mixed-Play Framework for Multi-Agent Generalizable Behaviors
May 16, 2025Population-population generalization is a challenging problem in multi-agent reinforcement learning (MARL), particularly when agents encounter unseen co-players. However, existing self-play-based methods are constrained by the limitation of inside-space generalization. In this study, we propose Bidirectional Distillation (BiDist), a novel mixed-play framework, to overcome this limitation in MARL. BiDist leverages knowledge distillation in two alternating directions: forward distillation, which emulates the historical policies' space and creates an implicit self-play, and reverse distillation, which systematically drives agents towards novel distributions outside the known policy space in a non-self-play manner. In addition, BiDist operates as a concise and efficient solution without the need for the complex and costly storage of past policies. We provide both theoretical analysis and empirical evidence to support BiDist's effectiveness. Our results highlight its remarkable generalization ability across a variety of cooperative, competitive, and social dilemma tasks, and reveal that BiDist significantly diversifies the policy distribution space. We also present comprehensive ablation studies to reinforce BiDist's effectiveness and key success factors. Source codes are available in the supplementary material.
Segment Any RGB-Thermal Model with Language-aided Distillation
May 04, 2025The recent Segment Anything Model (SAM) demonstrates strong instance segmentation performance across various downstream tasks. However, SAM is trained solely on RGB data, limiting its direct applicability to RGB-thermal (RGB-T) semantic segmentation. Given that RGB-T provides a robust solution for scene understanding in adverse weather and lighting conditions, such as low light and overexposure, we propose a novel framework, SARTM, which customizes the powerful SAM for RGB-T semantic segmentation. Our key idea is to unleash the potential of SAM while introduce semantic understanding modules for RGB-T data pairs. Specifically, our framework first involves fine tuning the original SAM by adding extra LoRA layers, aiming at preserving SAM's strong generalization and segmentation capabilities for downstream tasks. Secondly, we introduce language information as guidance for training our SARTM. To address cross-modal inconsistencies, we introduce a Cross-Modal Knowledge Distillation(CMKD) module that effectively achieves modality adaptation while maintaining its generalization capabilities. This semantic module enables the minimization of modality gaps and alleviates semantic ambiguity, facilitating the combination of any modality under any visual conditions. Furthermore, we enhance the segmentation performance by adjusting the segmentation head of SAM and incorporating an auxiliary semantic segmentation head, which integrates multi-scale features for effective fusion. Extensive experiments are conducted across three multi-modal RGBT semantic segmentation benchmarks: MFNET, PST900, and FMB. Both quantitative and qualitative results consistently demonstrate that the proposed SARTM significantly outperforms state-of-the-art approaches across a variety of conditions.
FP3O: Enabling Proximal Policy Optimization in Multi-Agent Cooperation with Parameter-Sharing Versatility
Oct 08, 2023



Existing multi-agent PPO algorithms lack compatibility with different types of parameter sharing when extending the theoretical guarantee of PPO to cooperative multi-agent reinforcement learning (MARL). In this paper, we propose a novel and versatile multi-agent PPO algorithm for cooperative MARL to overcome this limitation. Our approach is achieved upon the proposed full-pipeline paradigm, which establishes multiple parallel optimization pipelines by employing various equivalent decompositions of the advantage function. This procedure successfully formulates the interconnections among agents in a more general manner, i.e., the interconnections among pipelines, making it compatible with diverse types of parameter sharing. We provide a solid theoretical foundation for policy improvement and subsequently develop a practical algorithm called Full-Pipeline PPO (FP3O) by several approximations. Empirical evaluations on Multi-Agent MuJoCo and StarCraftII tasks demonstrate that FP3O outperforms other strong baselines and exhibits remarkable versatility across various parameter-sharing configurations.
Adaptive Value Decomposition with Greedy Marginal Contribution Computation for Cooperative Multi-Agent Reinforcement Learning
Feb 14, 2023



Real-world cooperation often requires intensive coordination among agents simultaneously. This task has been extensively studied within the framework of cooperative multi-agent reinforcement learning (MARL), and value decomposition methods are among those cutting-edge solutions. However, traditional methods that learn the value function as a monotonic mixing of per-agent utilities cannot solve the tasks with non-monotonic returns. This hinders their application in generic scenarios. Recent methods tackle this problem from the perspective of implicit credit assignment by learning value functions with complete expressiveness or using additional structures to improve cooperation. However, they are either difficult to learn due to large joint action spaces or insufficient to capture the complicated interactions among agents which are essential to solving tasks with non-monotonic returns. To address these problems, we propose a novel explicit credit assignment method to address the non-monotonic problem. Our method, Adaptive Value decomposition with Greedy Marginal contribution (AVGM), is based on an adaptive value decomposition that learns the cooperative value of a group of dynamically changing agents. We first illustrate that the proposed value decomposition can consider the complicated interactions among agents and is feasible to learn in large-scale scenarios. Then, our method uses a greedy marginal contribution computed from the value decomposition as an individual credit to incentivize agents to learn the optimal cooperative policy. We further extend the module with an action encoder to guarantee the linear time complexity for computing the greedy marginal contribution. Experimental results demonstrate that our method achieves significant performance improvements in several non-monotonic domains.
TinyLight: Adaptive Traffic Signal Control on Devices with Extremely Limited Resources
May 01, 2022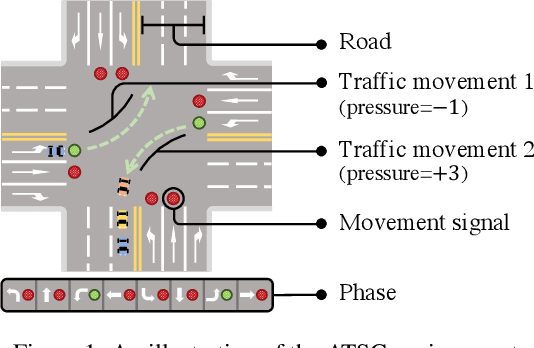
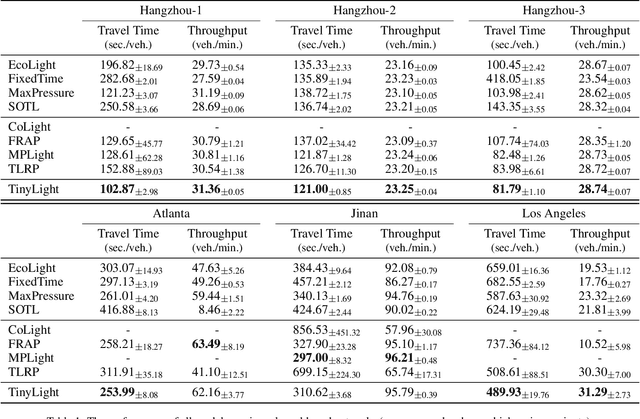
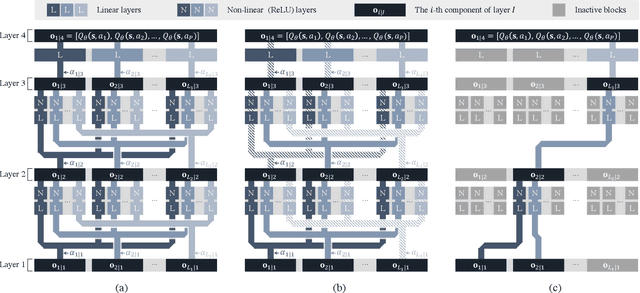

Recent advances in deep reinforcement learning (DRL) have largely promoted the performance of adaptive traffic signal control (ATSC). Nevertheless, regarding the implementation, most works are cumbersome in terms of storage and computation. This hinders their deployment on scenarios where resources are limited. In this work, we propose TinyLight, the first DRL-based ATSC model that is designed for devices with extremely limited resources. TinyLight first constructs a super-graph to associate a rich set of candidate features with a group of light-weighted network blocks. Then, to diminish the model's resource consumption, we ablate edges in the super-graph automatically with a novel entropy-minimized objective function. This enables TinyLight to work on a standalone microcontroller with merely 2KB RAM and 32KB ROM. We evaluate TinyLight on multiple road networks with real-world traffic demands. Experiments show that even with extremely limited resources, TinyLight still achieves competitive performance. The source code and appendix of this work can be found at \url{https://bit.ly/38hH8t8}.
A Spatial-Temporal Attention Multi-Graph Convolution Network for Ride-Hailing Demand Prediction Based on Periodicity with Offset
Apr 08, 2022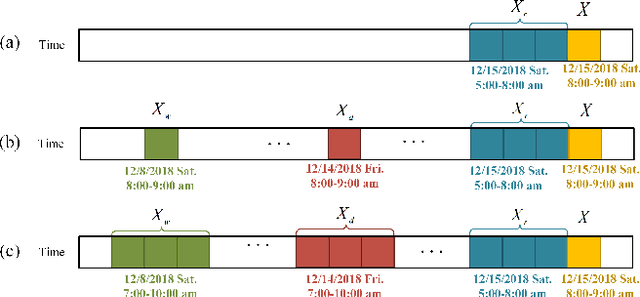

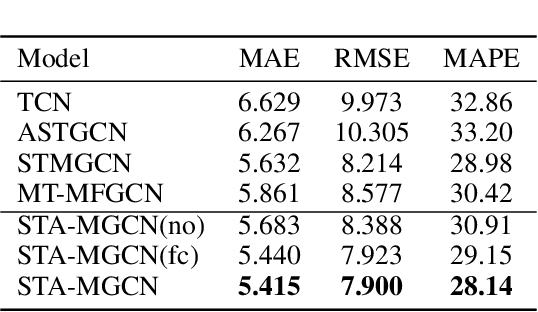
Ride-hailing service is becoming a leading part in urban transportation. To improve the efficiency of ride-hailing service, accurate prediction of transportation demand is a fundamental challenge. In this paper, we tackle this problem from both aspects of network structure and data-set formulation. For network design, we propose a spatial-temporal attention multi-graph convolution network (STA-MGCN). A spatial-temporal layer in STA-MGCN is developed to capture the temporal correlations by temporal attention mechanism and temporal gate convolution, and the spatial correlations by multigraph convolution. A feature cluster layer is introduced to learn latent regional functions and to reduce the computation burden. For the data-set formulation, we develop a novel approach which considers the transportation feature of periodicity with offset. Instead of only using history data during the same time period, the history order demand in forward and backward neighboring time periods from yesterday and last week are also included. Extensive experiments on the three real-world datasets of New-York, Chicago and Chengdu show that the proposed algorithm achieves the state-of-the-art performance for ride-hailing demand prediction.
Effective AER Object Classification Using Segmented Probability-Maximization Learning in Spiking Neural Networks
Feb 14, 2020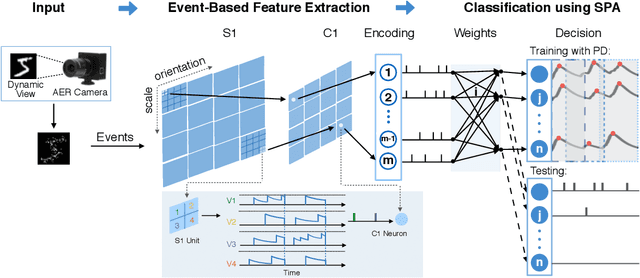

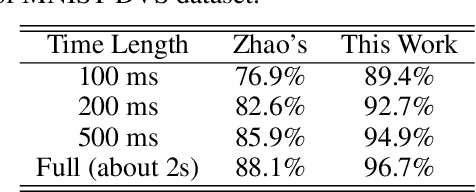

Address event representation (AER) cameras have recently attracted more attention due to the advantages of high temporal resolution and low power consumption, compared with traditional frame-based cameras. Since AER cameras record the visual input as asynchronous discrete events, they are inherently suitable to coordinate with the spiking neural network (SNN), which is biologically plausible and energy-efficient on neuromorphic hardware. However, using SNN to perform the AER object classification is still challenging, due to the lack of effective learning algorithms for this new representation. To tackle this issue, we propose an AER object classification model using a novel segmented probability-maximization (SPA) learning algorithm. Technically, 1) the SPA learning algorithm iteratively maximizes the probability of the classes that samples belong to, in order to improve the reliability of neuron responses and effectiveness of learning; 2) a peak detection (PD) mechanism is introduced in SPA to locate informative time points segment by segment, based on which information within the whole event stream can be fully utilized by the learning. Extensive experimental results show that, compared to state-of-the-art methods, not only our model is more effective, but also it requires less information to reach a certain level of accuracy.
Unsupervised AER Object Recognition Based on Multiscale Spatio-Temporal Features and Spiking Neurons
Nov 19, 2019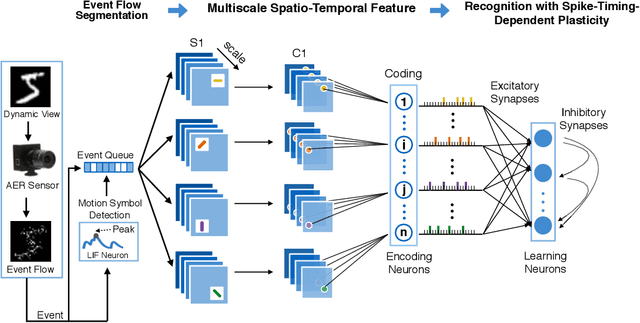


This paper proposes an unsupervised address event representation (AER) object recognition approach. The proposed approach consists of a novel multiscale spatio-temporal feature (MuST) representation of input AER events and a spiking neural network (SNN) using spike-timing-dependent plasticity (STDP) for object recognition with MuST. MuST extracts the features contained in both the spatial and temporal information of AER event flow, and meanwhile forms an informative and compact feature spike representation. We show not only how MuST exploits spikes to convey information more effectively, but also how it benefits the recognition using SNN. The recognition process is performed in an unsupervised manner, which does not need to specify the desired status of every single neuron of SNN, and thus can be flexibly applied in real-world recognition tasks. The experiments are performed on five AER datasets including a new one named GESTURE-DVS. Extensive experimental results show the effectiveness and advantages of this proposed approach.