 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeeMamba: Efficient Acceleration Framework for Mamba Models in Edge Computing
Aug 14, 2025State Space Model (SSM)-based machine learning architectures have recently gained significant attention for processing sequential data. Mamba, a recent sequence-to-sequence SSM, offers competitive accuracy with superior computational efficiency compared to state-of-the-art transformer models. While this advantage makes Mamba particularly promising for resource-constrained edge devices, no hardware acceleration frameworks are currently optimized for deploying it in such environments. This paper presents eMamba, a comprehensive end-to-end hardware acceleration framework explicitly designed for deploying Mamba models on edge platforms. eMamba maximizes computational efficiency by replacing complex normalization layers with lightweight hardware-aware alternatives and approximating expensive operations, such as SiLU activation and exponentiation, considering the target applications. Then, it performs an approximation-aware neural architecture search (NAS) to tune the learnable parameters used during approximation. Evaluations with Fashion-MNIST, CIFAR-10, and MARS, an open-source human pose estimation dataset, show eMamba achieves comparable accuracy to state-of-the-art techniques using 1.63-19.9$\times$ fewer parameters. In addition, it generalizes well to large-scale natural language tasks, demonstrating stable perplexity across varying sequence lengths on the WikiText2 dataset. We also quantize and implement the entire eMamba pipeline on an AMD ZCU102 FPGA and ASIC using GlobalFoundries (GF) 22 nm technology. Experimental results show 4.95-5.62$\times$ lower latency and 2.22-9.95$\times$ higher throughput, with 4.77$\times$ smaller area, 9.84$\times$ lower power, and 48.6$\times$ lower energy consumption than baseline solutions while maintaining competitive accuracy.
Bidirectional Distillation: A Mixed-Play Framework for Multi-Agent Generalizable Behaviors
May 16, 2025Population-population generalization is a challenging problem in multi-agent reinforcement learning (MARL), particularly when agents encounter unseen co-players. However, existing self-play-based methods are constrained by the limitation of inside-space generalization. In this study, we propose Bidirectional Distillation (BiDist), a novel mixed-play framework, to overcome this limitation in MARL. BiDist leverages knowledge distillation in two alternating directions: forward distillation, which emulates the historical policies' space and creates an implicit self-play, and reverse distillation, which systematically drives agents towards novel distributions outside the known policy space in a non-self-play manner. In addition, BiDist operates as a concise and efficient solution without the need for the complex and costly storage of past policies. We provide both theoretical analysis and empirical evidence to support BiDist's effectiveness. Our results highlight its remarkable generalization ability across a variety of cooperative, competitive, and social dilemma tasks, and reveal that BiDist significantly diversifies the policy distribution space. We also present comprehensive ablation studies to reinforce BiDist's effectiveness and key success factors. Source codes are available in the supplementary material.
Learning When to Think: Shaping Adaptive Reasoning in R1-Style Models via Multi-Stage RL
May 16, 2025



Large reasoning models (LRMs) are proficient at generating explicit, step-by-step reasoning sequences before producing final answers. However, such detailed reasoning can introduce substantial computational overhead and latency, particularly for simple problems. To address this over-thinking problem, we explore how to equip LRMs with adaptive thinking capabilities: enabling them to dynamically decide whether or not to engage in explicit reasoning based on problem complexity. Building on R1-style distilled models, we observe that inserting a simple ellipsis ("...") into the prompt can stochastically trigger either a thinking or no-thinking mode, revealing a latent controllability in the reasoning behavior. Leveraging this property, we propose AutoThink, a multi-stage reinforcement learning (RL) framework that progressively optimizes reasoning policies via stage-wise reward shaping. AutoThink learns to invoke explicit reasoning only when necessary, while defaulting to succinct responses for simpler tasks. Experiments on five mainstream mathematical benchmarks demonstrate that AutoThink achieves favorable accuracy-efficiency trade-offs compared to recent prompting and RL-based pruning methods. It can be seamlessly integrated into any R1-style model, including both distilled and further fine-tuned variants. Notably, AutoThink improves relative accuracy by 6.4 percent while reducing token usage by 52 percent on DeepSeek-R1-Distill-Qwen-1.5B, establishing a scalable and adaptive reasoning paradigm for LRMs.
Enhancing LLM Reasoning with Iterative DPO: A Comprehensive Empirical Investigation
Mar 17, 2025



Recent advancements in post-training methodologies for large language models (LLMs) have highlighted reinforcement learning (RL) as a critical component for enhancing reasoning. However, the substantial computational costs associated with RL-based approaches have led to growing interest in alternative paradigms, such as Direct Preference Optimization (DPO). In this study, we investigate the effectiveness of DPO in facilitating self-improvement for LLMs through iterative preference-based learning. We demonstrate that a single round of DPO with coarse filtering significantly enhances mathematical reasoning performance, particularly for strong base model. Furthermore, we design an iterative enhancement framework for both the generator and the reward model (RM), enabling their mutual improvement through online interaction across multiple rounds of DPO. Finally, with simple verifiable rewards, our model DPO-VP achieves RL-level performance with significantly lower computational overhead. These findings highlight DPO as a scalable and cost-effective alternative to RL, offering a practical solution for enhancing LLM reasoning in resource-constrained situations.
GHuNeRF: Generalizable Human NeRF from a Monocular Video
Sep 03, 2023

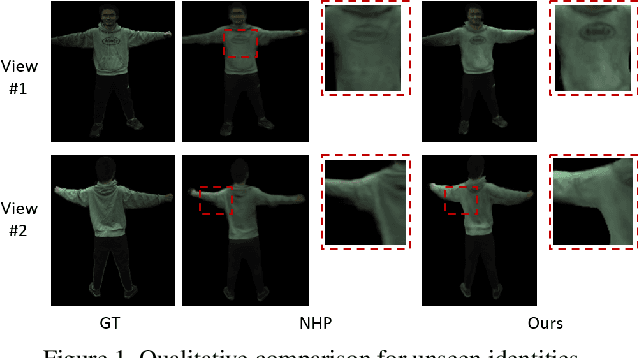

In this paper, we tackle the challenging task of learning a generalizable human NeRF model from a monocular video. Although existing generalizable human NeRFs have achieved impressive results, they require muti-view images or videos which might not be always available. On the other hand, some works on free-viewpoint rendering of human from monocular videos cannot be generalized to unseen identities. In view of these limitations, we propose GHuNeRF to learn a generalizable human NeRF model from a monocular video of the human performer. We first introduce a visibility-aware aggregation scheme to compute vertex-wise features, which is used to construct a 3D feature volume. The feature volume can only represent the overall geometry of the human performer with insufficient accuracy due to the limited resolution. To solve this, we further enhance the volume feature with temporally aligned point-wise features using an attention mechanism. Finally, the enhanced feature is used for predicting density and color for each sampled point. A surface-guided sampling strategy is also introduced to improve the efficiency for both training and inference. We validate our approach on the widely-used ZJU-MoCap dataset, where we achieve comparable performance with existing multi-view video based approaches. We also test on the monocular People-Snapshot dataset and achieve better performance than existing works when only monocular video is used.
Online Map Vectorization for Autonomous Driving: A Rasterization Perspective
Jun 18, 2023



Vectorized high-definition (HD) map is essential for autonomous driving, providing detailed and precise environmental information for advanced perception and planning. However, current map vectorization methods often exhibit deviations, and the existing evaluation metric for map vectorization lacks sufficient sensitivity to detect these deviations. To address these limitations, we propose integrating the philosophy of rasterization into map vectorization. Specifically, we introduce a new rasterization-based evaluation metric, which has superior sensitivity and is better suited to real-world autonomous driving scenarios. Furthermore, we propose MapVR (Map Vectorization via Rasterization), a novel framework that applies differentiable rasterization to vectorized outputs and then performs precise and geometry-aware supervision on rasterized HD maps. Notably, MapVR designs tailored rasterization strategies for various geometric shapes, enabling effective adaptation to a wide range of map elements. Experiments show that incorporating rasterization into map vectorization greatly enhances performance with no extra computational cost during inference, leading to more accurate map perception and ultimately promoting safer autonomous driving.
Learning Spatial Context with Graph Neural Network for Multi-Person Pose Grouping
Apr 06, 2021
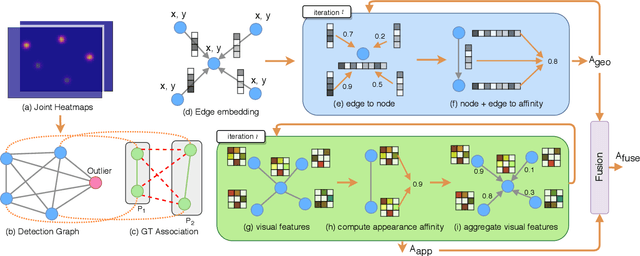


Bottom-up approaches for image-based multi-person pose estimation consist of two stages: (1) keypoint detection and (2) grouping of the detected keypoints to form person instances. Current grouping approaches rely on learned embedding from only visual features that completely ignore the spatial configuration of human poses. In this work, we formulate the grouping task as a graph partitioning problem, where we learn the affinity matrix with a Graph Neural Network (GNN). More specifically, we design a Geometry-aware Association GNN that utilizes spatial information of the keypoints and learns local affinity from the global context. The learned geometry-based affinity is further fused with appearance-based affinity to achieve robust keypoint association. Spectral clustering is used to partition the graph for the formation of the pose instances. Experimental results on two benchmark datasets show that our proposed method outperforms existing appearance-only grouping frameworks, which shows the effectiveness of utilizing spatial context for robust grouping. Source code is available at: https://github.com/jiahaoLjh/PoseGrouping.
Multi-View Multi-Person 3D Pose Estimation with Plane Sweep Stereo
Apr 06, 2021



Existing approaches for multi-view multi-person 3D pose estimation explicitly establish cross-view correspondences to group 2D pose detections from multiple camera views and solve for the 3D pose estimation for each person. Establishing cross-view correspondences is challenging in multi-person scenes, and incorrect correspondences will lead to sub-optimal performance for the multi-stage pipeline. In this work, we present our multi-view 3D pose estimation approach based on plane sweep stereo to jointly address the cross-view fusion and 3D pose reconstruction in a single shot. Specifically, we propose to perform depth regression for each joint of each 2D pose in a target camera view. Cross-view consistency constraints are implicitly enforced by multiple reference camera views via the plane sweep algorithm to facilitate accurate depth regression. We adopt a coarse-to-fine scheme to first regress the person-level depth followed by a per-person joint-level relative depth estimation. 3D poses are obtained from a simple back-projection given the estimated depths. We evaluate our approach on benchmark datasets where it outperforms previous state-of-the-arts while being remarkably efficient. Our code is available at https://github.com/jiahaoLjh/PlaneSweepPose.
HDNet: Human Depth Estimation for Multi-Person Camera-Space Localization
Jul 17, 2020

Current works on multi-person 3D pose estimation mainly focus on the estimation of the 3D joint locations relative to the root joint and ignore the absolute locations of each pose. In this paper, we propose the Human Depth Estimation Network (HDNet), an end-to-end framework for absolute root joint localization in the camera coordinate space. Our HDNet first estimates the 2D human pose with heatmaps of the joints. These estimated heatmaps serve as attention masks for pooling features from image regions corresponding to the target person. A skeleton-based Graph Neural Network (GNN) is utilized to propagate features among joints. We formulate the target depth regression as a bin index estimation problem, which can be transformed with a soft-argmax operation from the classification output of our HDNet. We evaluate our HDNet on the root joint localization and root-relative 3D pose estimation tasks with two benchmark datasets, i.e., Human3.6M and MuPoTS-3D. The experimental results show that we outperform the previous state-of-the-art consistently under multiple evaluation metrics. Our source code is available at: https://github.com/jiahaoLjh/HumanDepth.
Robust Vision-based Obstacle Avoidance for Micro Aerial Vehicles in Dynamic Environments
Feb 13, 2020
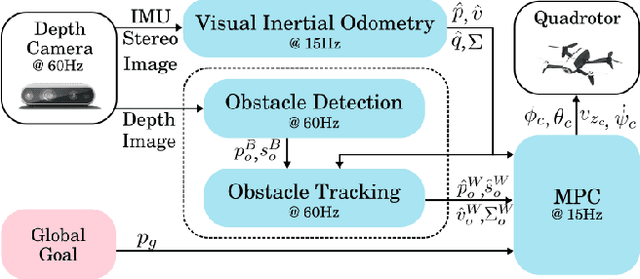


In this paper, we present an on-board vision-based approach for avoidance of moving obstacles in dynamic environments. Our approach relies on an efficient obstacle detection and tracking algorithm based on depth image pairs, which provides the estimated position, velocity and size of the obstacles. Robust collision avoidance is achieved by formulating a chance-constrained model predictive controller (CC-MPC) to ensure that the collision probability between the micro aerial vehicle (MAV) and each moving obstacle is below a specified threshold. The method takes into account MAV dynamics, state estimation and obstacle sensing uncertainties. The proposed approach is implemented on a quadrotor equipped with a stereo camera and is tested in a variety of environments, showing effective on-line collision avoidance of moving obstacles.