 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying Prediction Powered Inference
Jan 28, 2026Machine learning predictions are increasingly used to supplement incomplete or costly-to-measure outcomes in fields such as biomedical research, environmental science, and social science. However, treating predictions as ground truth introduces bias while ignoring them wastes valuable information. Prediction-Powered Inference (PPI) offers a principled framework that leverages predictions from large unlabeled datasets to improve statistical efficiency while maintaining valid inference through explicit bias correction using a smaller labeled subset. Despite its potential, the growing PPI variants and the subtle distinctions between them have made it challenging for practitioners to determine when and how to apply these methods responsibly. This paper demystifies PPI by synthesizing its theoretical foundations, methodological extensions, connections to existing statistics literature, and diagnostic tools into a unified practical workflow. Using the Mosaiks housing price data, we show that PPI variants produce tighter confidence intervals than complete-case analysis, but that double-dipping, i.e. reusing training data for inference, leads to anti-conservative confidence intervals and coverages. Under missing-not-at-random mechanisms, all methods, including classical inference using only labeled data, yield biased estimates. We provide a decision flowchart linking assumption violations to appropriate PPI variants, a summary table of selective methods, and practical diagnostic strategies for evaluating core assumptions. By framing PPI as a general recipe rather than a single estimator, this work bridges methodological innovation and applied practice, helping researchers responsibly integrate predictions into valid inference.
Online Map Vectorization for Autonomous Driving: A Rasterization Perspective
Jun 18, 2023



Vectorized high-definition (HD) map is essential for autonomous driving, providing detailed and precise environmental information for advanced perception and planning. However, current map vectorization methods often exhibit deviations, and the existing evaluation metric for map vectorization lacks sufficient sensitivity to detect these deviations. To address these limitations, we propose integrating the philosophy of rasterization into map vectorization. Specifically, we introduce a new rasterization-based evaluation metric, which has superior sensitivity and is better suited to real-world autonomous driving scenarios. Furthermore, we propose MapVR (Map Vectorization via Rasterization), a novel framework that applies differentiable rasterization to vectorized outputs and then performs precise and geometry-aware supervision on rasterized HD maps. Notably, MapVR designs tailored rasterization strategies for various geometric shapes, enabling effective adaptation to a wide range of map elements. Experiments show that incorporating rasterization into map vectorization greatly enhances performance with no extra computational cost during inference, leading to more accurate map perception and ultimately promoting safer autonomous driving.
Remote Sensing Image Super-resolution and Object Detection: Benchmark and State of the Art
Nov 05, 2021
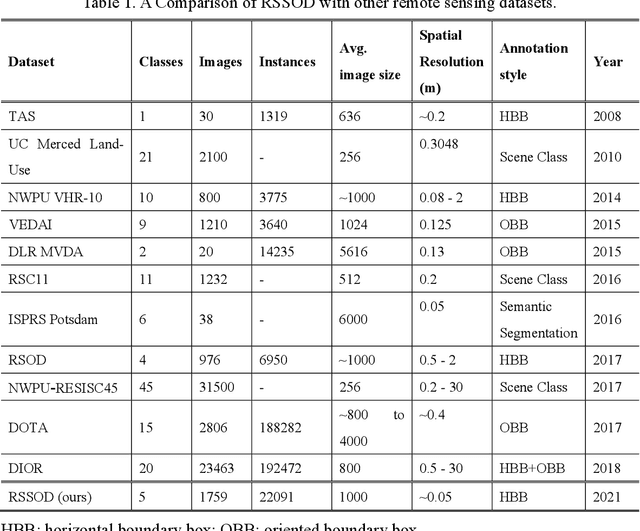
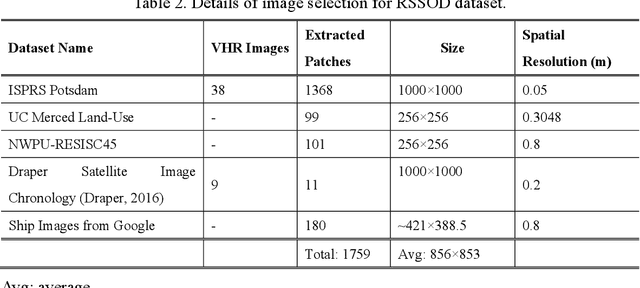
For the past two decades, there have been significant efforts to develop methods for object detection in Remote Sensing (RS) images. In most cases, the datasets for small object detection in remote sensing images are inadequate. Many researchers used scene classification datasets for object detection, which has its limitations; for example, the large-sized objects outnumber the small objects in object categories. Thus, they lack diversity; this further affects the detection performance of small object detectors in RS images. This paper reviews current datasets and object detection methods (deep learning-based) for remote sensing images. We also propose a large-scale, publicly available benchmark Remote Sensing Super-resolution Object Detection (RSSOD) dataset. The RSSOD dataset consists of 1,759 hand-annotated images with 22,091 instances of very high resolution (VHR) images with a spatial resolution of ~0.05 m. There are five classes with varying frequencies of labels per class. The image patches are extracted from satellite images, including real image distortions such as tangential scale distortion and skew distortion. We also propose a novel Multi-class Cyclic super-resolution Generative adversarial network with Residual feature aggregation (MCGR) and auxiliary YOLOv5 detector to benchmark image super-resolution-based object detection and compare with the existing state-of-the-art methods based on image super-resolution (SR). The proposed MCGR achieved state-of-the-art performance for image SR with an improvement of 1.2dB PSNR compared to the current state-of-the-art NLSN method. MCGR achieved best object detection mAPs of 0.758, 0.881, 0.841, and 0.983, respectively, for five-class, four-class, two-class, and single classes, respectively surpassing the performance of the state-of-the-art object detectors YOLOv5, EfficientDet, Faster RCNN, SSD, and RetinaNet.
Pixel-wise object tracking
Jul 03, 2018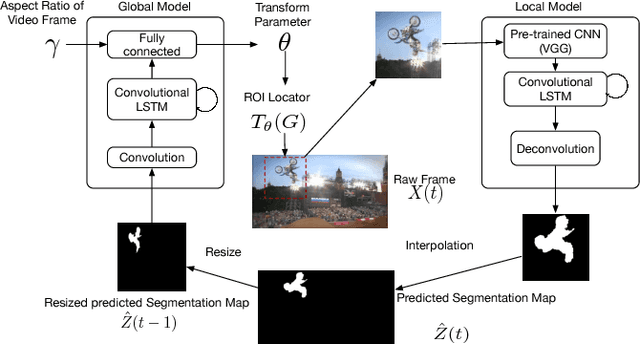
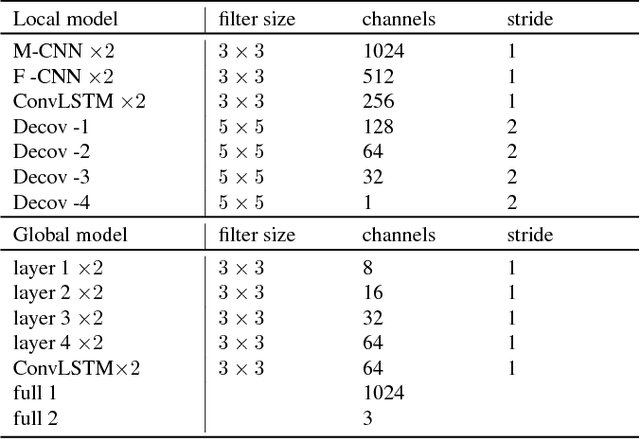
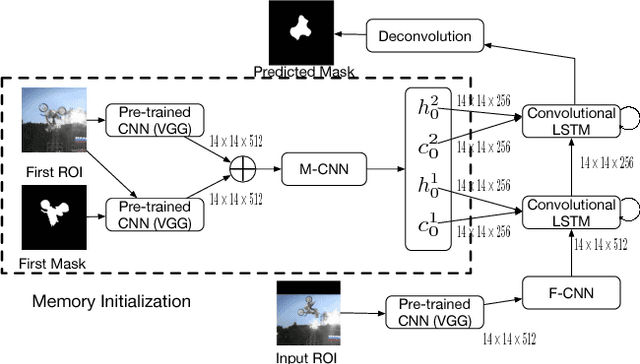
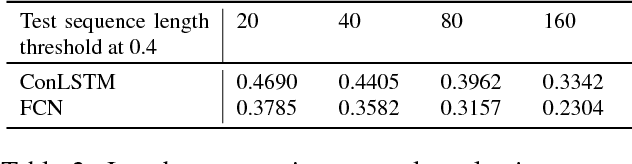
In this paper, we propose a novel pixel-wise visual object tracking framework that can track any anonymous object in a noisy background. The framework consists of two submodels, a global attention model and a local segmentation model. The global model generates a region of interests (ROI) that the object may lie in the new frame based on the past object segmentation maps, while the local model segments the new image in the ROI. Each model uses a LSTM structure to model the temporal dynamics of the motion and appearance, respectively. To circumvent the dependency of the training data between the two models, we use an iterative update strategy. Once the models are trained, there is no need to refine them to track specific objects, making our method efficient compared to online learning approaches. We demonstrate our real time pixel-wise object tracking framework on a challenging VOT dataset
Multi Resolution LSTM For Long Term Prediction In Neural Activity Video
Jul 03, 2018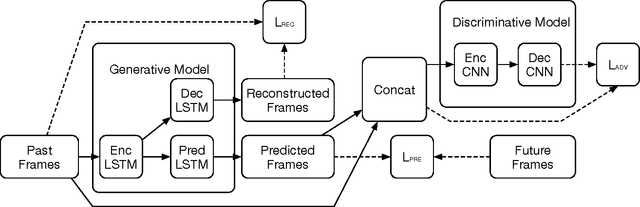
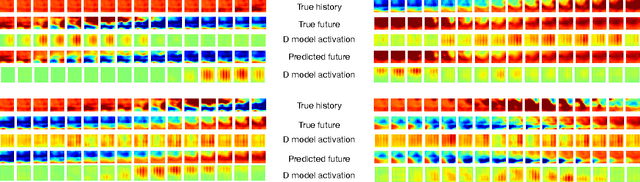
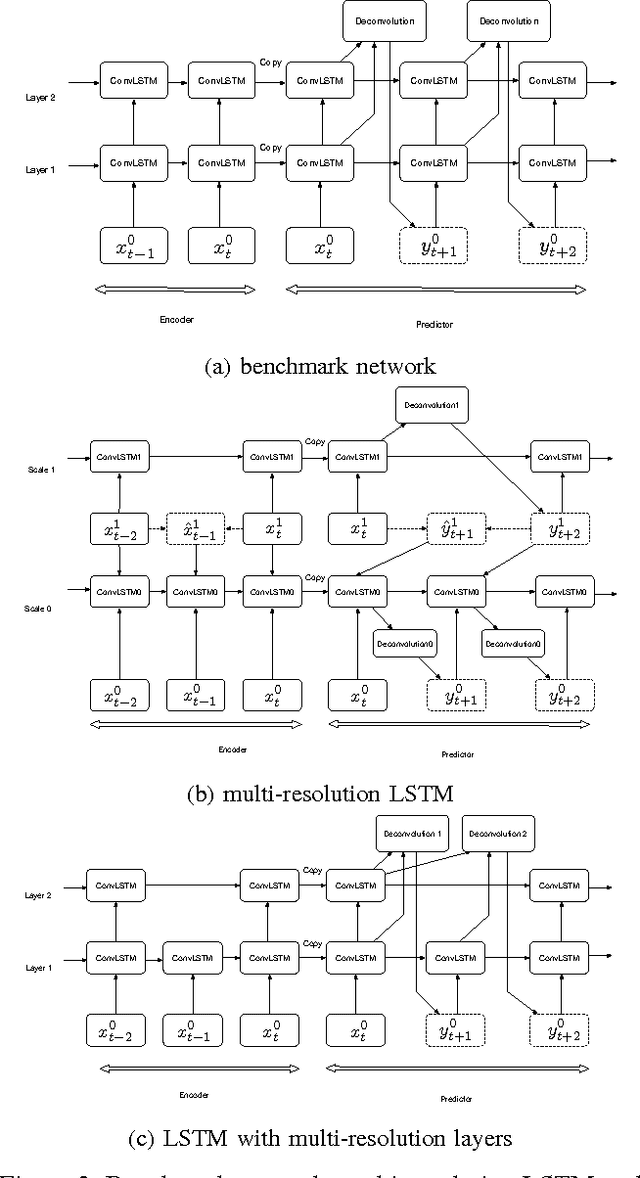

Epileptic seizures are caused by abnormal, overly syn- chronized, electrical activity in the brain. The abnor- mal electrical activity manifests as waves, propagating across the brain. Accurate prediction of the propagation velocity and direction of these waves could enable real- time responsive brain stimulation to suppress or prevent the seizures entirely. However, this problem is very chal- lenging because the algorithm must be able to predict the neural signals in a sufficiently long time horizon to allow enough time for medical intervention. We consider how to accomplish long term prediction using a LSTM network. To alleviate the vanishing gradient problem, we propose two encoder-decoder-predictor structures, both using multi-resolution representation. The novel LSTM structure with multi-resolution layers could significantly outperform the single-resolution benchmark with similar number of parameters. To overcome the blurring effect associated with video prediction in the pixel domain using standard mean square error (MSE) loss, we use energy- based adversarial training to improve the long-term pre- diction. We demonstrate and analyze how a discriminative model with an encoder-decoder structure using 3D CNN model improves long term prediction.
Diversity encouraged learning of unsupervised LSTM ensemble for neural activity video prediction
Jul 03, 2018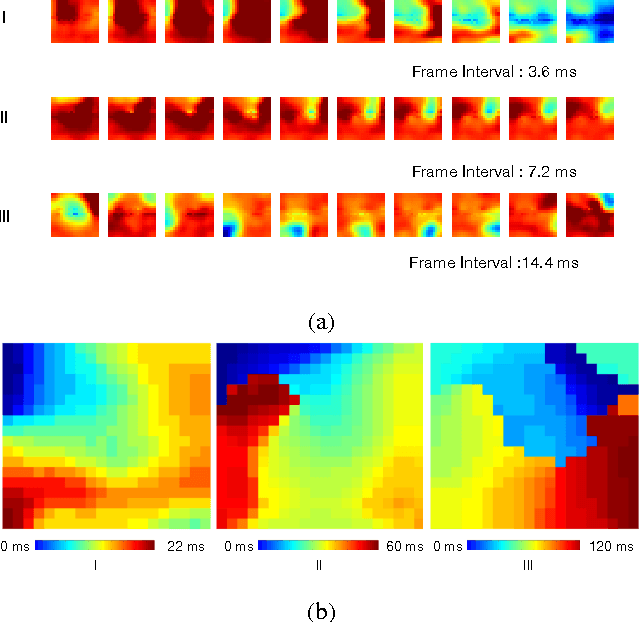

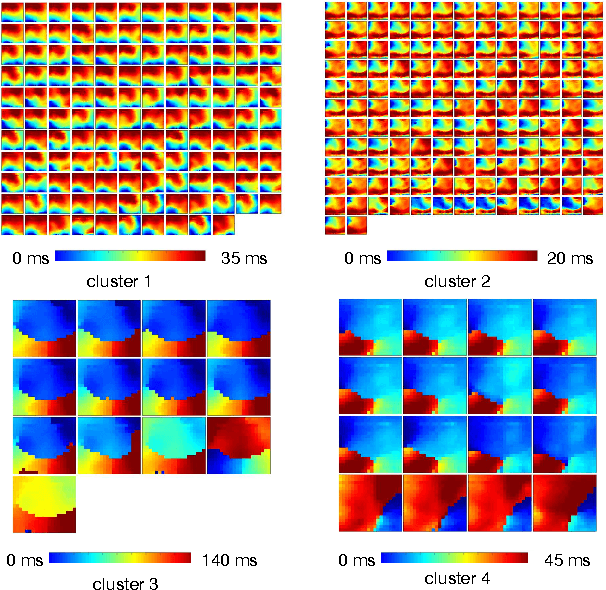
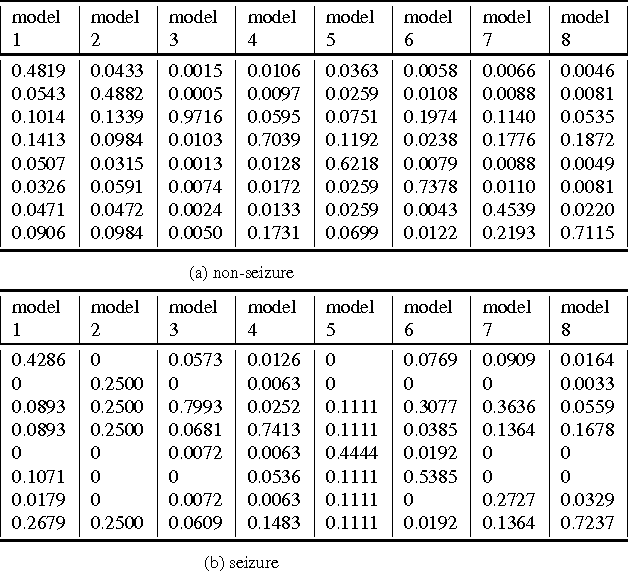
Being able to predict the neural signal in the near future from the current and previous observations has the potential to enable real-time responsive brain stimulation to suppress seizures. We have investigated how to use an auto-encoder model consisting of LSTM cells for such prediction. Recog- nizing that there exist multiple activity pattern clusters, we have further explored to train an ensemble of LSTM mod- els so that each model can specialize in modeling certain neural activities, without explicitly clustering the training data. We train the ensemble using an ensemble-awareness loss, which jointly solves the model assignment problem and the error minimization problem. During training, for each training sequence, only the model that has the lowest recon- struction and prediction error is updated. Intrinsically such a loss function enables each LTSM model to be adapted to a subset of the training sequences that share similar dynamic behavior. We demonstrate this can be trained in an end- to-end manner and achieve significant accuracy in neural activity prediction.