 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemote Sensing Image Super-resolution and Object Detection: Benchmark and State of the Art
Nov 05, 2021
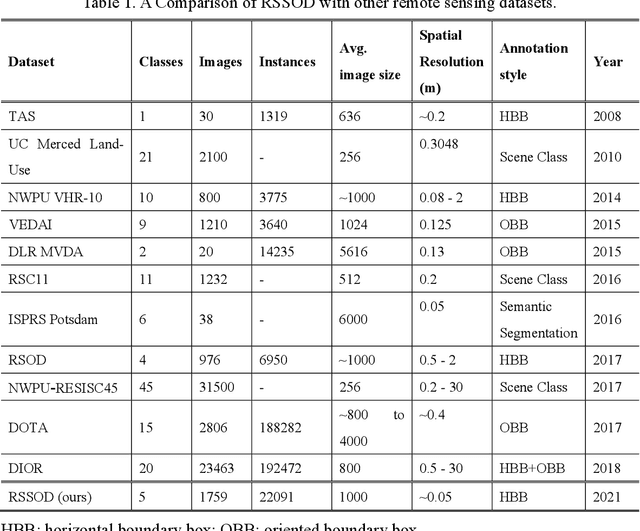
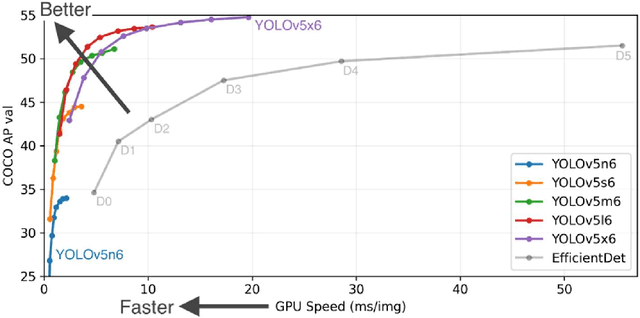
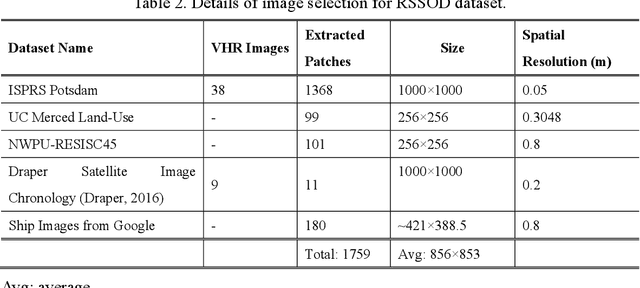
For the past two decades, there have been significant efforts to develop methods for object detection in Remote Sensing (RS) images. In most cases, the datasets for small object detection in remote sensing images are inadequate. Many researchers used scene classification datasets for object detection, which has its limitations; for example, the large-sized objects outnumber the small objects in object categories. Thus, they lack diversity; this further affects the detection performance of small object detectors in RS images. This paper reviews current datasets and object detection methods (deep learning-based) for remote sensing images. We also propose a large-scale, publicly available benchmark Remote Sensing Super-resolution Object Detection (RSSOD) dataset. The RSSOD dataset consists of 1,759 hand-annotated images with 22,091 instances of very high resolution (VHR) images with a spatial resolution of ~0.05 m. There are five classes with varying frequencies of labels per class. The image patches are extracted from satellite images, including real image distortions such as tangential scale distortion and skew distortion. We also propose a novel Multi-class Cyclic super-resolution Generative adversarial network with Residual feature aggregation (MCGR) and auxiliary YOLOv5 detector to benchmark image super-resolution-based object detection and compare with the existing state-of-the-art methods based on image super-resolution (SR). The proposed MCGR achieved state-of-the-art performance for image SR with an improvement of 1.2dB PSNR compared to the current state-of-the-art NLSN method. MCGR achieved best object detection mAPs of 0.758, 0.881, 0.841, and 0.983, respectively, for five-class, four-class, two-class, and single classes, respectively surpassing the performance of the state-of-the-art object detectors YOLOv5, EfficientDet, Faster RCNN, SSD, and RetinaNet.
A Comprehensive Review of Deep Learning-based Single Image Super-resolution
Feb 18, 2021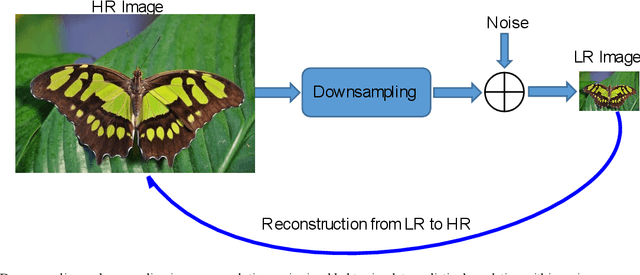
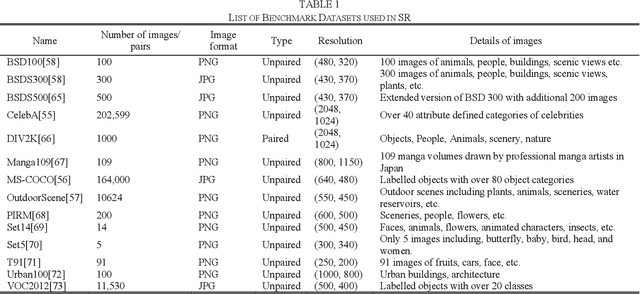
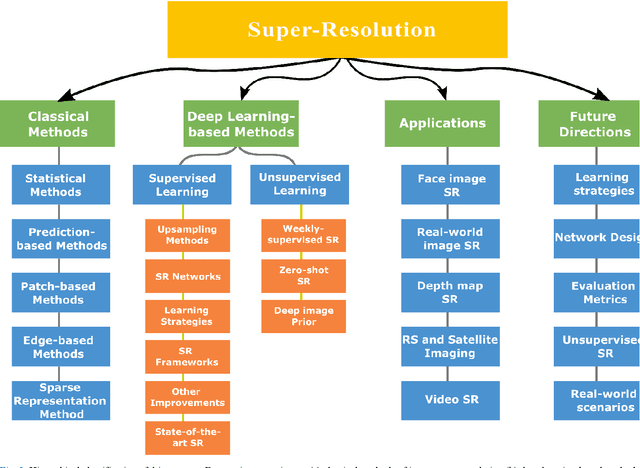
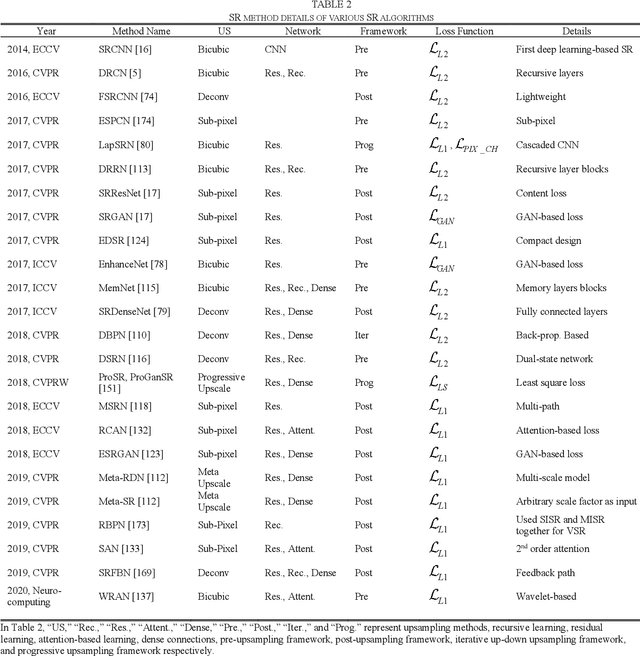
Image super-resolution (SR) is one of the vital image processing methods that improve the resolution of an image in the field of computer vision. In the last two decades, significant progress has been made in the field of super-resolution, especially utilizing deep learning methods. This survey is an effort to provide a detailed survey of recent progress in the field of super-resolution in the perspective of deep learning while also informing about the initial classical methods used for achieving super-resolution. The survey classifies the image SR methods into four categories, i.e., classical methods, supervised learning-based methods, unsupervised learning-based methods, and domain-specific SR methods. We also introduce the problem of SR to provide intuition about image quality metrics, available reference datasets, and SR challenges. Deep learning-based approaches of SR are evaluated using a reference dataset. Finally, this survey is concluded with future directions and trends in the field of SR and open problems in SR to be addressed by the researchers.
Perspective Texture Synthesis Based on Improved Energy Optimization
Jun 21, 2020
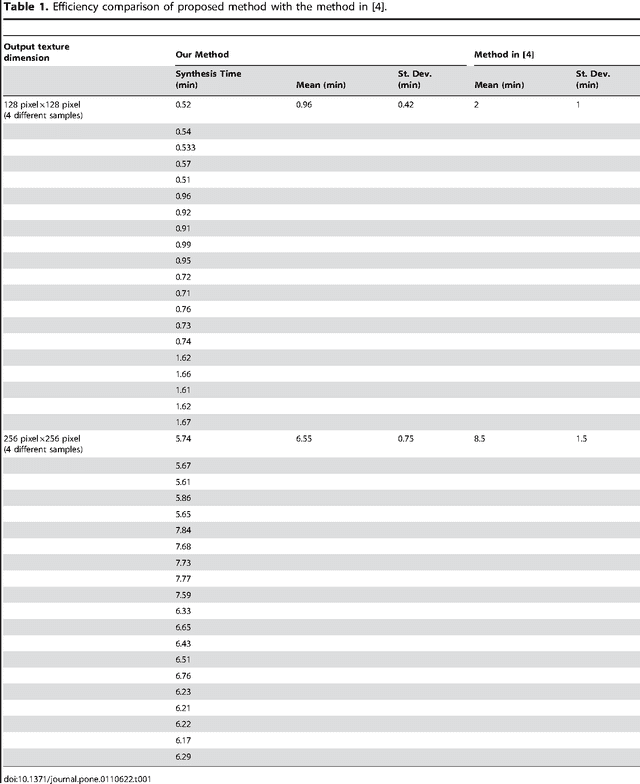
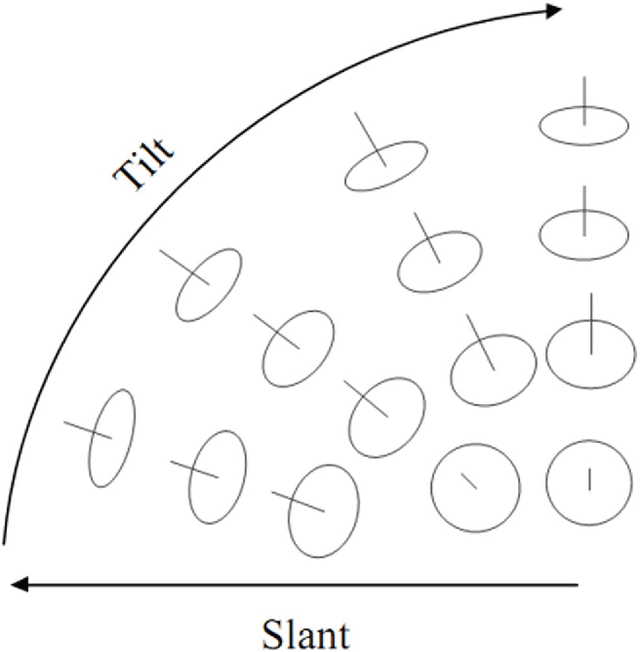
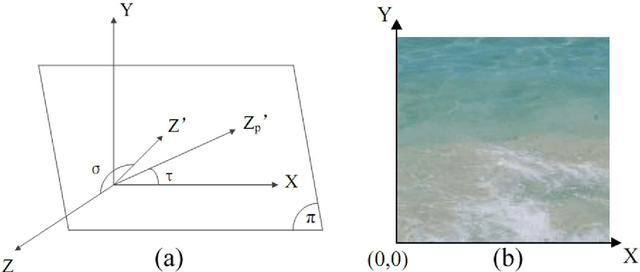
Perspective texture synthesis has great significance in many fields like video editing, scene capturing etc., due to its ability to read and control global feature information. In this paper, we present a novel example-based, specifically energy optimization-based algorithm, to synthesize perspective textures. Energy optimization technique is a pixel-based approach, so it is time-consuming. We improve it from two aspects with the purpose of achieving faster synthesis and high quality. Firstly, we change this pixel-based technique by replacing the pixel computation with a little patch. Secondly, we present a novel technique to accelerate searching nearest neighborhoods in energy optimization. Using k- means clustering technique to build a search tree to accelerate the search. Hence, we make use of principal component analysis (PCA) technique to reduce dimensions of input vectors. The high quality results prove that our approach is feasible. Besides, our proposed algorithm needs shorter time relative to other similar methods.
* Published in PLOS One
Font Acknowledgment and Character Extraction of Digital and Scanned Images
May 17, 2013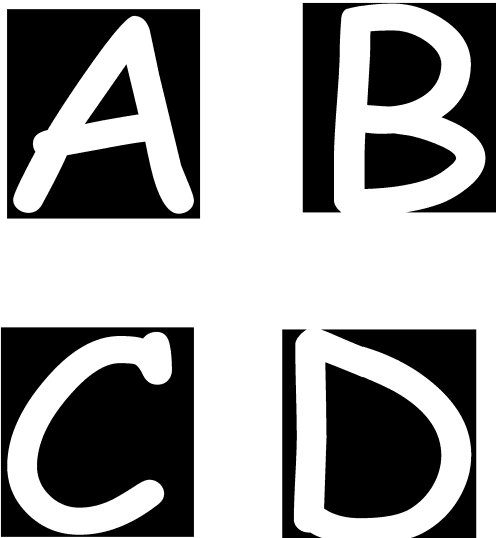
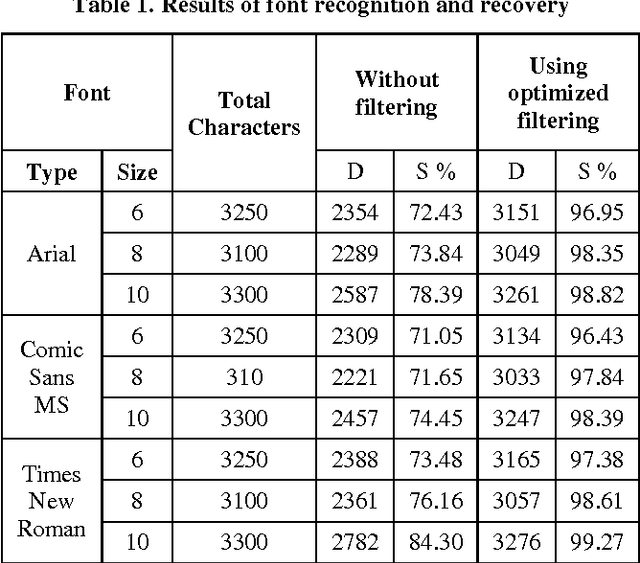


The font recognition and character extraction is of immense importance as these are many scenarios where data are in such a form, which cannot be processed like in image form or as a hard copy. So the procedure developed in this paper is basically related to identifying the font (Times New Roman, Arial and Comic Sans MS) and afterwards recovering the text using simple correlation based method where the binary templates are correlated to the input image text characters. All of this extraction is done in the presence of a little noise as images may have noisy patterns due to photocopying. The significance of this method exists in extraction of data from various monitoring (Surveillance) camera footages or even more. The method is developed on Matlab\c{opyright} which takes input image and recovers text and font information from it in a text file.
* 5 pages, 5 figures, 1 table, Published with International Journal of Computer Applications (IJCA)