 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Object Interactions with Behavior Primitives: An Application in Stowing Tasks
Sep 28, 2023Stowing, the task of placing objects in cluttered shelves or bins, is a common task in warehouse and manufacturing operations. However, this task is still predominantly carried out by human workers as stowing is challenging to automate due to the complex multi-object interactions and long-horizon nature of the task. Previous works typically involve extensive data collection and costly human labeling of semantic priors across diverse object categories. This paper presents a method to learn a generalizable robot stowing policy from predictive model of object interactions and a single demonstration with behavior primitives. We propose a novel framework that utilizes Graph Neural Networks to predict object interactions within the parameter space of behavioral primitives. We further employ primitive-augmented trajectory optimization to search the parameters of a predefined library of heterogeneous behavioral primitives to instantiate the control action. Our framework enables robots to proficiently execute long-horizon stowing tasks with a few keyframes (3-4) from a single demonstration. Despite being solely trained in a simulation, our framework demonstrates remarkable generalization capabilities. It efficiently adapts to a broad spectrum of real-world conditions, including various shelf widths, fluctuating quantities of objects, and objects with diverse attributes such as sizes and shapes.
Learning Task Skills and Goals Simultaneously from Physical Interaction
Sep 08, 2023
In real-world human-robot systems, it is essential for a robot to comprehend human objectives and respond accordingly while performing an extended series of motor actions. Although human objective alignment has recently emerged as a promising paradigm in the realm of physical human-robot interaction, its application is typically confined to generating simple motions due to inherent theoretical limitations. In this work, our goal is to develop a general formulation to learn manipulation functional modules and long-term task goals simultaneously from physical human-robot interaction. We show the feasibility of our framework in enabling robots to align their behaviors with the long-term task objectives inferred from human interactions.
Towards Safe Multi-Level Human-Robot Interaction in Industrial Tasks
Aug 06, 2023
Multiple levels of safety measures are required by multiple interaction modes which collaborative robots need to perform industrial tasks with human co-workers. We develop three independent modules to account for safety in different types of human-robot interaction: vision-based safety monitoring pauses robot when human is present in a shared space; contact-based safety monitoring pauses robot when unexpected contact happens between human and robot; hierarchical intention tracking keeps robot in a safe distance from human when human and robot work independently, and switches robot to compliant mode when human intends to guide robot. We discuss the prospect of future research in development and integration of multi-level safety modules. We focus on how to provide safety guarantees for collaborative robot solutions with human behavior modeling.
User-Friendly Safety Monitoring System for Manufacturing Cobots
Jul 04, 2023

Collaborative robots are being increasingly utilized in industrial production lines due to their efficiency and accuracy. However, the close proximity between humans and robots can pose safety risks due to the robot's high-speed movements and powerful forces. To address this, we developed a vision-based safety monitoring system that creates a 3D reconstruction of the collaborative scene. Our system records the human-robot interaction data in real-time and reproduce their virtual replicas in a simulator for offline analysis. The objective is to provide workers with a user-friendly visualization tool for reviewing performance and diagnosing failures, thereby enhancing safety in manufacturing settings.
Remote Sensing Image Super-resolution and Object Detection: Benchmark and State of the Art
Nov 05, 2021
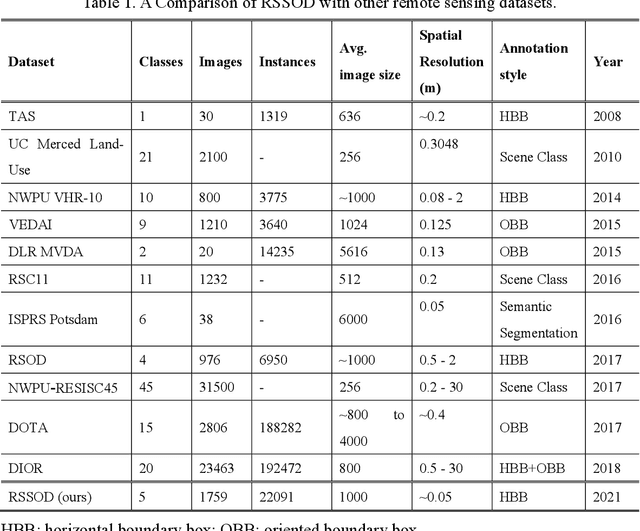
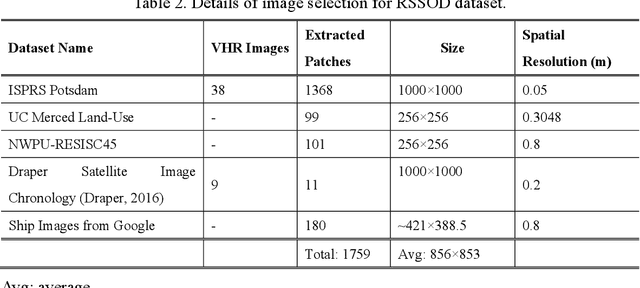
For the past two decades, there have been significant efforts to develop methods for object detection in Remote Sensing (RS) images. In most cases, the datasets for small object detection in remote sensing images are inadequate. Many researchers used scene classification datasets for object detection, which has its limitations; for example, the large-sized objects outnumber the small objects in object categories. Thus, they lack diversity; this further affects the detection performance of small object detectors in RS images. This paper reviews current datasets and object detection methods (deep learning-based) for remote sensing images. We also propose a large-scale, publicly available benchmark Remote Sensing Super-resolution Object Detection (RSSOD) dataset. The RSSOD dataset consists of 1,759 hand-annotated images with 22,091 instances of very high resolution (VHR) images with a spatial resolution of ~0.05 m. There are five classes with varying frequencies of labels per class. The image patches are extracted from satellite images, including real image distortions such as tangential scale distortion and skew distortion. We also propose a novel Multi-class Cyclic super-resolution Generative adversarial network with Residual feature aggregation (MCGR) and auxiliary YOLOv5 detector to benchmark image super-resolution-based object detection and compare with the existing state-of-the-art methods based on image super-resolution (SR). The proposed MCGR achieved state-of-the-art performance for image SR with an improvement of 1.2dB PSNR compared to the current state-of-the-art NLSN method. MCGR achieved best object detection mAPs of 0.758, 0.881, 0.841, and 0.983, respectively, for five-class, four-class, two-class, and single classes, respectively surpassing the performance of the state-of-the-art object detectors YOLOv5, EfficientDet, Faster RCNN, SSD, and RetinaNet.