 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Sim2Real Gap in User Simulation for Agentic Tasks
Mar 11, 2026As NLP evaluation shifts from static benchmarks to multi-turn interactive settings, LLM-based simulators have become widely used as user proxies, serving two roles: generating user turns and providing evaluation signals. Yet, these simulations are frequently assumed to be faithful to real human behaviors, often without rigorous verification. We formalize the Sim2Real gap in user simulation and present the first study running the full $τ$-bench protocol with real humans (451 participants, 165 tasks), benchmarking 31 LLM simulators across proprietary, open-source, and specialized families using the User-Sim Index (USI), a metric we introduce to quantify how well LLM simulators resemble real user interactive behaviors and feedback. Behaviorally, LLM simulators are excessively cooperative, stylistically uniform, and lack realistic frustration or ambiguity, creating an "easy mode" that inflates agent success rates above the human baseline. In evaluations, real humans provide nuanced judgments across eight quality dimensions while simulated users produce uniformly more positive feedback; rule-based rewards are failing to capture rich feedback signals generated by human users. Overall, higher general model capability does not necessarily yield more faithful user simulation. These findings highlight the importance of human validation when using LLM-based user simulators in the agent development cycle and motivate improved models for user simulation.
Hybrid-Gym: Training Coding Agents to Generalize Across Tasks
Feb 18, 2026When assessing the quality of coding agents, predominant benchmarks focus on solving single issues on GitHub, such as SWE-Bench. In contrast, in real use, these agents solve more various and complex tasks that involve other skills such as exploring codebases, testing software, and designing architecture. In this paper, we first characterize some transferable skills that are shared across diverse tasks by decomposing trajectories into fine-grained components, and derive a set of principles for designing auxiliary training tasks to teach language models these skills. Guided by these principles, we propose a training environment, Hybrid-Gym, consisting of a set of scalable synthetic tasks, such as function localization and dependency search. Experiments show that agents trained on our synthetic tasks effectively generalize to diverse real-world tasks that are not present in training, improving a base model by 25.4% absolute gain on SWE-Bench Verified, 7.9% on SWT-Bench Verified, and 5.1% on Commit-0 Lite. Hybrid-Gym also complements datasets built for the downstream tasks (e.g., improving SWE-Play by 4.9% on SWT-Bench Verified). Code available at: https://github.com/yiqingxyq/Hybrid-Gym.
An Empirical Study on Strong-Weak Model Collaboration for Repo-level Code Generation
May 26, 2025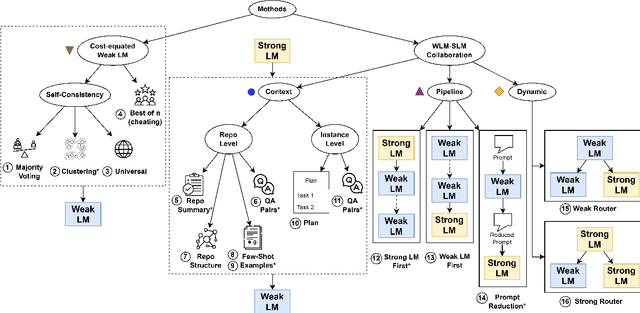
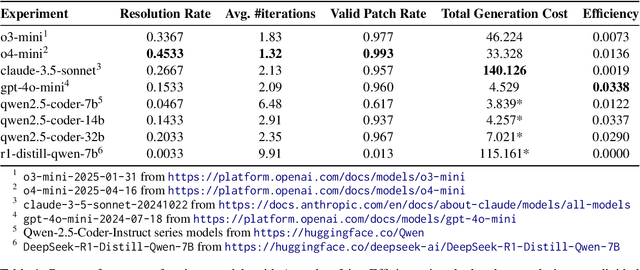
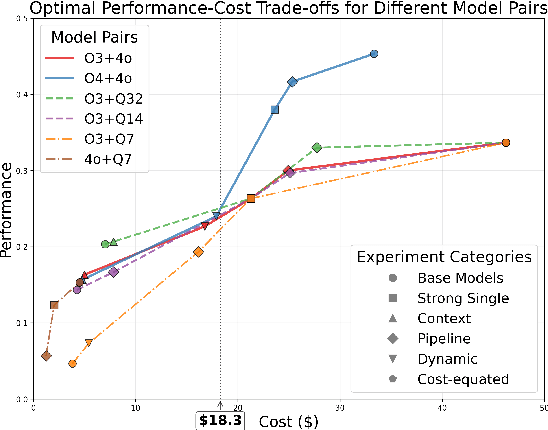
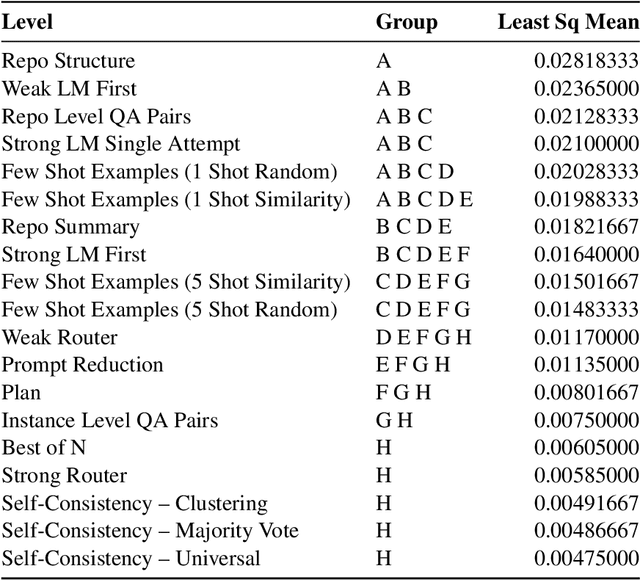
We study cost-efficient collaboration between strong and weak language models for repository-level code generation, where the weak model handles simpler tasks at lower cost, and the most challenging tasks are delegated to the strong model. While many works propose architectures for this task, few analyze performance relative to cost. We evaluate a broad spectrum of collaboration strategies: context-based, pipeline-based, and dynamic, on GitHub issue resolution. Our most effective collaborative strategy achieves equivalent performance to the strong model while reducing the cost by 40%. Based on our findings, we offer actionable guidelines for choosing collaboration strategies under varying budget and performance constraints. Our results show that strong-weak collaboration substantially boosts the weak model's performance at a fraction of the cost, pipeline and context-based methods being most efficient. We release the code for our work at https://github.com/shubhamrgandhi/codegen-strong-weak-collab.
RepoST: Scalable Repository-Level Coding Environment Construction with Sandbox Testing
Mar 10, 2025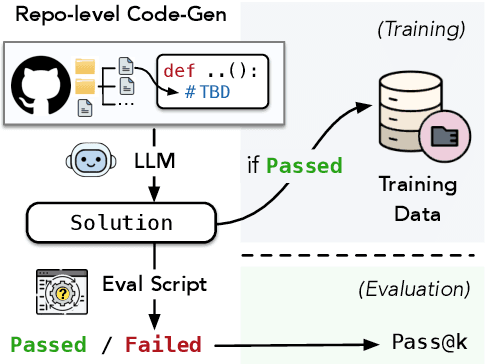
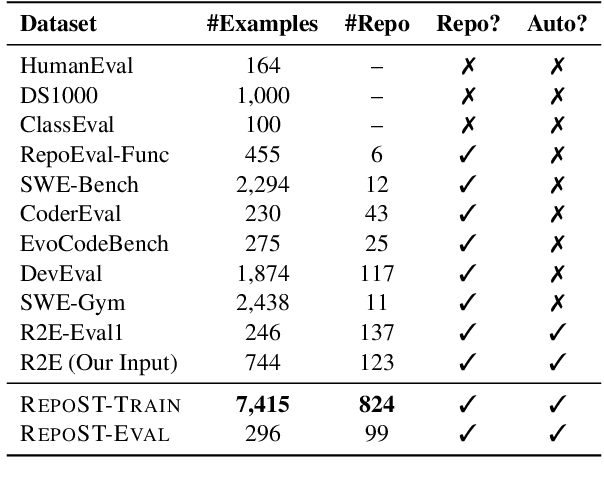
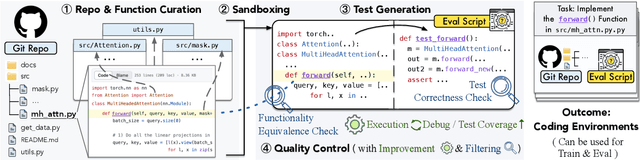
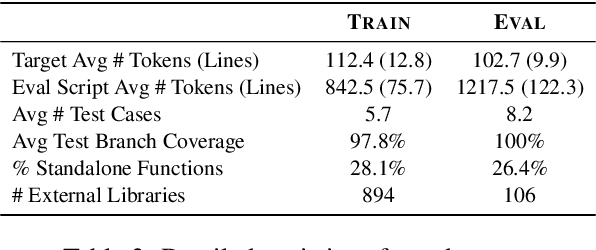
We present RepoST, a scalable method to construct environments that provide execution feedback for repository-level code generation for both training and evaluation. Unlike existing works that aim to build entire repositories for execution, which is challenging for both human and LLMs, we provide execution feedback with sandbox testing, which isolates a given target function and its dependencies to a separate script for testing. Sandbox testing reduces the complexity of external dependencies and enables constructing environments at a large scale. We use our method to construct RepoST-Train, a large-scale train set with 7,415 functions from 832 repositories. Training with the execution feedback provided by RepoST-Train leads to a performance gain of 5.5% Pass@1 on HumanEval and 3.5% Pass@1 on RepoEval. We also build an evaluation dataset, RepoST-Eval, and benchmark 12 code generation models.
TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
Dec 18, 2024We interact with computers on an everyday basis, be it in everyday life or work, and many aspects of work can be done entirely with access to a computer and the Internet. At the same time, thanks to improvements in large language models (LLMs), there has also been a rapid development in AI agents that interact with and affect change in their surrounding environments. But how performant are AI agents at helping to accelerate or even autonomously perform work-related tasks? The answer to this question has important implications for both industry looking to adopt AI into their workflows, and for economic policy to understand the effects that adoption of AI may have on the labor market. To measure the progress of these LLM agents' performance on performing real-world professional tasks, in this paper, we introduce TheAgentCompany, an extensible benchmark for evaluating AI agents that interact with the world in similar ways to those of a digital worker: by browsing the Web, writing code, running programs, and communicating with other coworkers. We build a self-contained environment with internal web sites and data that mimics a small software company environment, and create a variety of tasks that may be performed by workers in such a company. We test baseline agents powered by both closed API-based and open-weights language models (LMs), and find that with the most competitive agent, 24% of the tasks can be completed autonomously. This paints a nuanced picture on task automation with LM agents -- in a setting simulating a real workplace, a good portion of simpler tasks could be solved autonomously, but more difficult long-horizon tasks are still beyond the reach of current systems.
Improving Model Factuality with Fine-grained Critique-based Evaluator
Oct 24, 2024Factuality evaluation aims to detect factual errors produced by language models (LMs) and hence guide the development of more factual models. Towards this goal, we train a factuality evaluator, FenCE, that provides LM generators with claim-level factuality feedback. We conduct data augmentation on a combination of public judgment datasets to train FenCE to (1) generate textual critiques along with scores and (2) make claim-level judgment based on diverse source documents obtained by various tools. We then present a framework that leverages FenCE to improve the factuality of LM generators by constructing training data. Specifically, we generate a set of candidate responses, leverage FenCE to revise and score each response without introducing lesser-known facts, and train the generator by preferring highly scored revised responses. Experiments show that our data augmentation methods improve the evaluator's accuracy by 2.9% on LLM-AggreFact. With FenCE, we improve Llama3-8B-chat's factuality rate by 14.45% on FActScore, outperforming state-of-the-art factuality finetuning methods by 6.96%.
CodeRAG-Bench: Can Retrieval Augment Code Generation?
Jun 20, 2024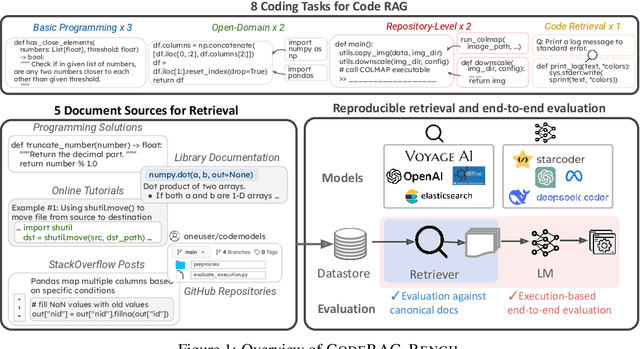
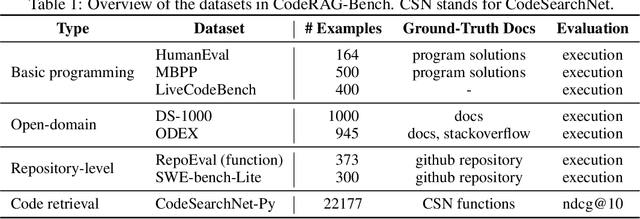
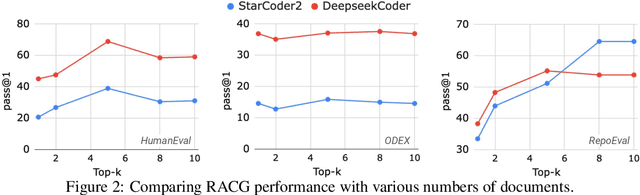
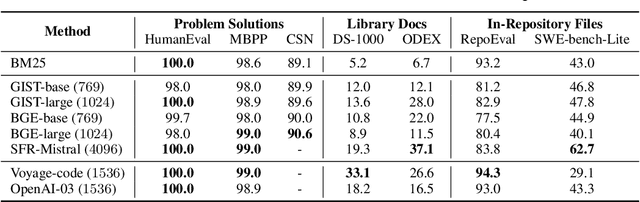
While language models (LMs) have proven remarkably adept at generating code, many programs are challenging for LMs to generate using their parametric knowledge alone. Providing external contexts such as library documentation can facilitate generating accurate and functional code. Despite the success of retrieval-augmented generation (RAG) in various text-oriented tasks, its potential for improving code generation remains under-explored. In this work, we conduct a systematic, large-scale analysis by asking: in what scenarios can retrieval benefit code generation models? and what challenges remain? We first curate a comprehensive evaluation benchmark, CodeRAG-Bench, encompassing three categories of code generation tasks, including basic programming, open-domain, and repository-level problems. We aggregate documents from five sources for models to retrieve contexts: competition solutions, online tutorials, library documentation, StackOverflow posts, and GitHub repositories. We examine top-performing models on CodeRAG-Bench by providing contexts retrieved from one or multiple sources. While notable gains are made in final code generation by retrieving high-quality contexts across various settings, our analysis reveals room for improvement -- current retrievers still struggle to fetch useful contexts especially with limited lexical overlap, and generators fail to improve with limited context lengths or abilities to integrate additional contexts. We hope CodeRAG-Bench serves as an effective testbed to encourage further development of advanced code-oriented RAG methods.
CodeBenchGen: Creating Scalable Execution-based Code Generation Benchmarks
Mar 31, 2024



To facilitate evaluation of code generation systems across diverse scenarios, we present CodeBenchGen, a framework to create scalable execution-based benchmarks that only requires light guidance from humans. Specifically, we leverage a large language model (LLM) to convert an arbitrary piece of code into an evaluation example, including test cases for execution-based evaluation. We illustrate the usefulness of our framework by creating a dataset, Exec-CSN, which includes 1,931 examples involving 293 libraries revised from code in 367 GitHub repositories taken from the CodeSearchNet dataset. To demonstrate the complexity and solvability of examples in Exec-CSN, we present a human study demonstrating that 81.3% of the examples can be solved by humans and 61% are rated as ``requires effort to solve''. We conduct code generation experiments on open-source and proprietary models and analyze the performance of both humans and models. We will release the code of both the framework and the dataset upon acceptance.
Attribute Structuring Improves LLM-Based Evaluation of Clinical Text Summaries
Mar 01, 2024



Summarizing clinical text is crucial in health decision-support and clinical research. Large language models (LLMs) have shown the potential to generate accurate clinical text summaries, but still struggle with issues regarding grounding and evaluation, especially in safety-critical domains such as health. Holistically evaluating text summaries is challenging because they may contain unsubstantiated information. Here, we explore a general mitigation framework using Attribute Structuring (AS), which structures the summary evaluation process. It decomposes the evaluation process into a grounded procedure that uses an LLM for relatively simple structuring and scoring tasks, rather than the full task of holistic summary evaluation. Experiments show that AS consistently improves the correspondence between human annotations and automated metrics in clinical text summarization. Additionally, AS yields interpretations in the form of a short text span corresponding to each output, which enables efficient human auditing, paving the way towards trustworthy evaluation of clinical information in resource-constrained scenarios. We release our code, prompts, and an open-source benchmark at https://github.com/microsoft/attribute-structuring.
Enhancing Medical Text Evaluation with GPT-4
Nov 16, 2023In the evaluation of medical text generation, it is essential to scrutinize each piece of information and ensure the utmost accuracy of the evaluation. Existing evaluation metrics either focus on coarse-level evaluation that assigns one score for the whole generated output or rely on evaluation models trained on general domain, resulting in inaccuracies when adapted to the medical domain. To address these issues, we propose a set of factuality-centric evaluation aspects and design corresponding GPT-4-based metrics for medical text generation. We systematically compare these metrics with existing ones on clinical note generation and medical report summarization tasks, revealing low inter-metric correlation. A comprehensive human evaluation confirms that the proposed GPT-4-based metrics exhibit substantially higher agreement with human judgments than existing evaluation metrics. Our study contributes to the understanding of medical text generation evaluation and offers a more reliable alternative to existing metrics.