 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Ranking and Generation in Query Auto-Completion via Retrieval-Augmented Generation and Multi-Objective Alignment
Feb 03, 2026Query Auto-Completion (QAC) suggests query completions as users type, helping them articulate intent and reach results more efficiently. Existing approaches face fundamental challenges: traditional retrieve-and-rank pipelines have limited long-tail coverage and require extensive feature engineering, while recent generative methods suffer from hallucination and safety risks. We present a unified framework that reformulates QAC as end-to-end list generation through Retrieval-Augmented Generation (RAG) and multi-objective Direct Preference Optimization (DPO). Our approach combines three key innovations: (1) reformulating QAC as end-to-end list generation with multi-objective optimization; (2) defining and deploying a suite of rule-based, model-based, and LLM-as-judge verifiers for QAC, and using them in a comprehensive methodology that combines RAG, multi-objective DPO, and iterative critique-revision for high-quality synthetic data; (3) a hybrid serving architecture enabling efficient production deployment under strict latency constraints. Evaluation on a large-scale commercial search platform demonstrates substantial improvements: offline metrics show gains across all dimensions, human evaluation yields +0.40 to +0.69 preference scores, and a controlled online experiment achieves 5.44\% reduction in keystrokes and 3.46\% increase in suggestion adoption, validating that unified generation with RAG and multi-objective alignment provides an effective solution for production QAC. This work represents a paradigm shift to end-to-end generation powered by large language models, RAG, and multi-objective alignment, establishing a production-validated framework that can benefit the broader search and recommendation industry.
RepoST: Scalable Repository-Level Coding Environment Construction with Sandbox Testing
Mar 10, 2025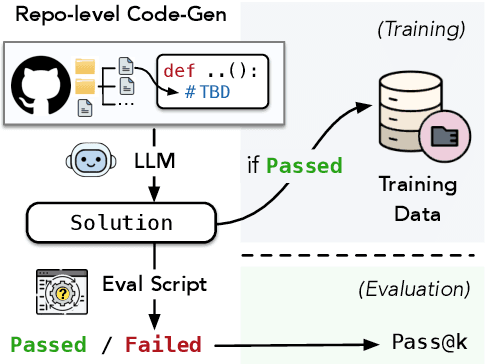
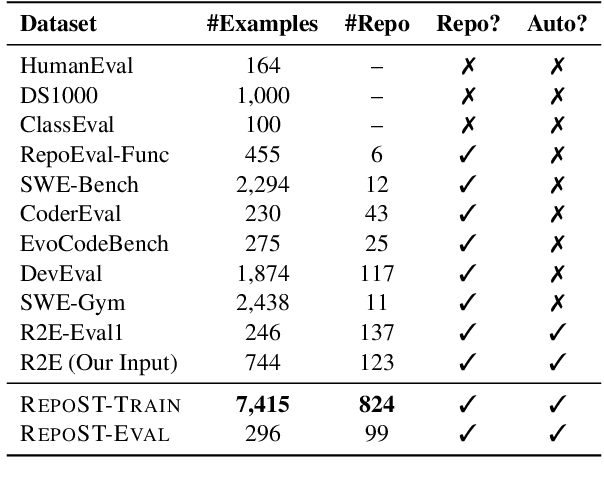
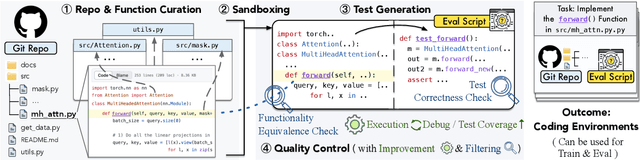
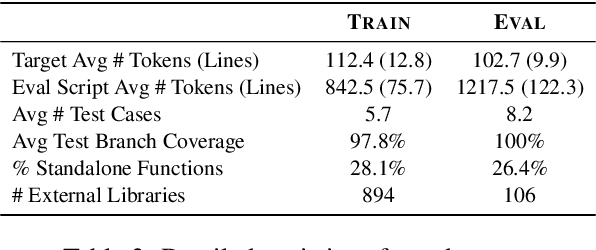
We present RepoST, a scalable method to construct environments that provide execution feedback for repository-level code generation for both training and evaluation. Unlike existing works that aim to build entire repositories for execution, which is challenging for both human and LLMs, we provide execution feedback with sandbox testing, which isolates a given target function and its dependencies to a separate script for testing. Sandbox testing reduces the complexity of external dependencies and enables constructing environments at a large scale. We use our method to construct RepoST-Train, a large-scale train set with 7,415 functions from 832 repositories. Training with the execution feedback provided by RepoST-Train leads to a performance gain of 5.5% Pass@1 on HumanEval and 3.5% Pass@1 on RepoEval. We also build an evaluation dataset, RepoST-Eval, and benchmark 12 code generation models.
Leveraging Machine-Generated Rationales to Facilitate Social Meaning Detection in Conversations
Jun 27, 2024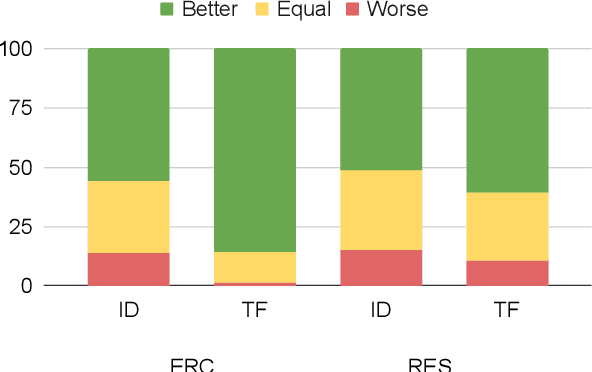
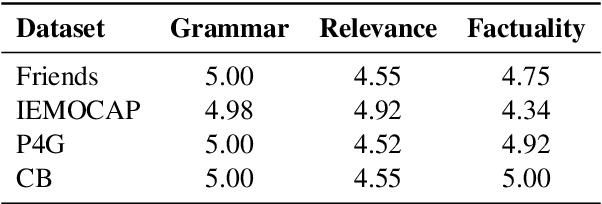

We present a generalizable classification approach that leverages Large Language Models (LLMs) to facilitate the detection of implicitly encoded social meaning in conversations. We design a multi-faceted prompt to extract a textual explanation of the reasoning that connects visible cues to underlying social meanings. These extracted explanations or rationales serve as augmentations to the conversational text to facilitate dialogue understanding and transfer. Our empirical results over 2,340 experimental settings demonstrate the significant positive impact of adding these rationales. Our findings hold true for in-domain classification, zero-shot, and few-shot domain transfer for two different social meaning detection tasks, each spanning two different corpora.
CodeBenchGen: Creating Scalable Execution-based Code Generation Benchmarks
Mar 31, 2024



To facilitate evaluation of code generation systems across diverse scenarios, we present CodeBenchGen, a framework to create scalable execution-based benchmarks that only requires light guidance from humans. Specifically, we leverage a large language model (LLM) to convert an arbitrary piece of code into an evaluation example, including test cases for execution-based evaluation. We illustrate the usefulness of our framework by creating a dataset, Exec-CSN, which includes 1,931 examples involving 293 libraries revised from code in 367 GitHub repositories taken from the CodeSearchNet dataset. To demonstrate the complexity and solvability of examples in Exec-CSN, we present a human study demonstrating that 81.3% of the examples can be solved by humans and 61% are rated as ``requires effort to solve''. We conduct code generation experiments on open-source and proprietary models and analyze the performance of both humans and models. We will release the code of both the framework and the dataset upon acceptance.
RAFT: Rationale adaptor for few-shot abusive language detection
Nov 30, 2022

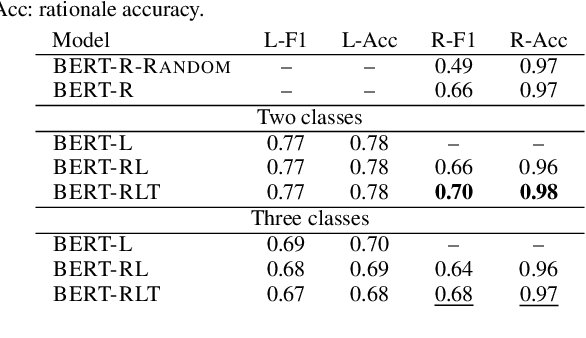

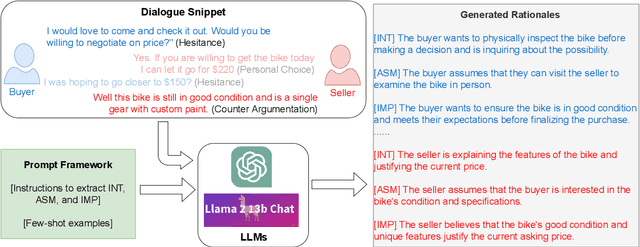
Abusive language is a concerning problem in online social media. Past research on detecting abusive language covers different platforms, languages, demographies, etc. However, models trained using these datasets do not perform well in cross-domain evaluation settings. To overcome this, a common strategy is to use a few samples from the target domain to train models to get better performance in that domain (cross-domain few-shot training). However, this might cause the models to overfit the artefacts of those samples. A compelling solution could be to guide the models toward rationales, i.e., spans of text that justify the text's label. This method has been found to improve model performance in the in-domain setting across various NLP tasks. In this paper, we propose RAFT (Rationale Adaptor for Few-shoT classification) for abusive language detection. We first build a multitask learning setup to jointly learn rationales, targets, and labels, and find a significant improvement of 6% macro F1 on the rationale detection task over training solely rationale classifiers. We introduce two rationale-integrated BERT-based architectures (the RAFT models) and evaluate our systems over five different abusive language datasets, finding that in the few-shot classification setting, RAFT-based models outperform baseline models by about 7% in macro F1 scores and perform competitively to models finetuned on other source domains. Furthermore, RAFT-based models outperform LIME/SHAP-based approaches in terms of plausibility and are close in performance in terms of faithfulness.
A Unified Framework for Pun Generation with Humor Principles
Oct 24, 2022



We propose a unified framework to generate both homophonic and homographic puns to resolve the split-up in existing works. Specifically, we incorporate three linguistic attributes of puns to the language models: ambiguity, distinctiveness, and surprise. Our framework consists of three parts: 1) a context words/phrases selector to promote the aforementioned attributes, 2) a generation model trained on non-pun sentences to incorporate the context words/phrases into the generation output, and 3) a label predictor that learns the structure of puns which is used to steer the generation model at inference time. Evaluation results on both pun types demonstrate the efficacy of our model over strong baselines.
CABACE: Injecting Character Sequence Information and Domain Knowledge for Enhanced Acronym and Long-Form Extraction
Dec 25, 2021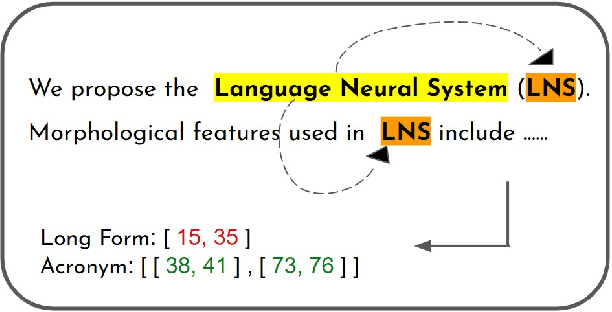
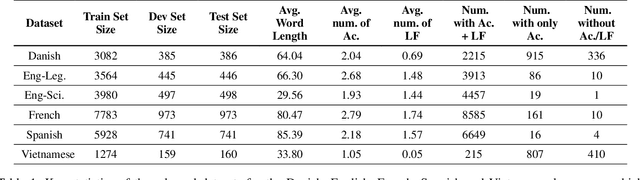
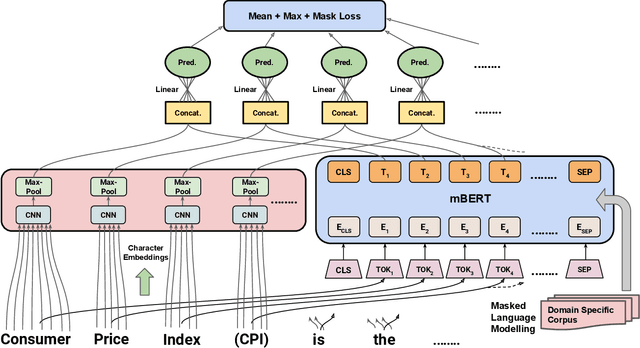
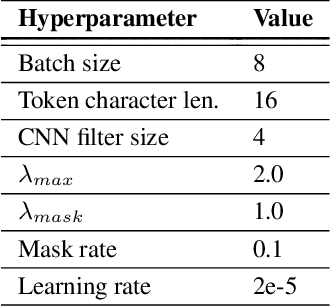
Acronyms and long-forms are commonly found in research documents, more so in documents from scientific and legal domains. Many acronyms used in such documents are domain-specific and are very rarely found in normal text corpora. Owing to this, transformer-based NLP models often detect OOV (Out of Vocabulary) for acronym tokens, especially for non-English languages, and their performance suffers while linking acronyms to their long forms during extraction. Moreover, pretrained transformer models like BERT are not specialized to handle scientific and legal documents. With these points being the overarching motivation behind this work, we propose a novel framework CABACE: Character-Aware BERT for ACronym Extraction, which takes into account character sequences in text and is adapted to scientific and legal domains by masked language modelling. We further use an objective with an augmented loss function, adding the max loss and mask loss terms to the standard cross-entropy loss for training CABACE. We further leverage pseudo labelling and adversarial data generation to improve the generalizability of the framework. Experimental results prove the superiority of the proposed framework in comparison to various baselines. Additionally, we show that the proposed framework is better suited than baseline models for zero-shot generalization to non-English languages, thus reinforcing the effectiveness of our approach. Our team BacKGProp secured the highest scores on the French dataset, second-highest on Danish and Vietnamese, and third-highest in the English-Legal dataset on the global leaderboard for the acronym extraction (AE) shared task at SDU AAAI-22.