 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Diffusion: Training Diffusion Policies on Cross-Embodiment Human Demonstrations
Nov 06, 2025Human videos can be recorded quickly and at scale, making them an appealing source of training data for robot learning. However, humans and robots differ fundamentally in embodiment, resulting in mismatched action execution. Direct kinematic retargeting of human hand motion can therefore produce actions that are physically infeasible for robots. Despite these low-level differences, human demonstrations provide valuable motion cues about how to manipulate and interact with objects. Our key idea is to exploit the forward diffusion process: as noise is added to actions, low-level execution differences fade while high-level task guidance is preserved. We present X-Diffusion, a principled framework for training diffusion policies that maximally leverages human data without learning dynamically infeasible motions. X-Diffusion first trains a classifier to predict whether a noisy action is executed by a human or robot. Then, a human action is incorporated into policy training only after adding sufficient noise such that the classifier cannot discern its embodiment. Actions consistent with robot execution supervise fine-grained denoising at low noise levels, while mismatched human actions provide only coarse guidance at higher noise levels. Our experiments show that naive co-training under execution mismatches degrades policy performance, while X-Diffusion consistently improves it. Across five manipulation tasks, X-Diffusion achieves a 16% higher average success rate than the best baseline. The project website is available at https://portal-cornell.github.io/X-Diffusion/.
X-Sim: Cross-Embodiment Learning via Real-to-Sim-to-Real
May 15, 2025Human videos offer a scalable way to train robot manipulation policies, but lack the action labels needed by standard imitation learning algorithms. Existing cross-embodiment approaches try to map human motion to robot actions, but often fail when the embodiments differ significantly. We propose X-Sim, a real-to-sim-to-real framework that uses object motion as a dense and transferable signal for learning robot policies. X-Sim starts by reconstructing a photorealistic simulation from an RGBD human video and tracking object trajectories to define object-centric rewards. These rewards are used to train a reinforcement learning (RL) policy in simulation. The learned policy is then distilled into an image-conditioned diffusion policy using synthetic rollouts rendered with varied viewpoints and lighting. To transfer to the real world, X-Sim introduces an online domain adaptation technique that aligns real and simulated observations during deployment. Importantly, X-Sim does not require any robot teleoperation data. We evaluate it across 5 manipulation tasks in 2 environments and show that it: (1) improves task progress by 30% on average over hand-tracking and sim-to-real baselines, (2) matches behavior cloning with 10x less data collection time, and (3) generalizes to new camera viewpoints and test-time changes. Code and videos are available at https://portal-cornell.github.io/X-Sim/.
Query-Efficient Planning with Language Models
Dec 09, 2024Planning in complex environments requires an agent to efficiently query a world model to find a feasible sequence of actions from start to goal. Recent work has shown that Large Language Models (LLMs), with their rich prior knowledge and reasoning capabilities, can potentially help with planning by searching over promising states and adapting to feedback from the world. In this paper, we propose and study two fundamentally competing frameworks that leverage LLMs for query-efficient planning. The first uses LLMs as a heuristic within a search-based planner to select promising nodes to expand and propose promising actions. The second uses LLMs as a generative planner to propose an entire sequence of actions from start to goal, query a world model, and adapt based on feedback. We show that while both approaches improve upon comparable baselines, using an LLM as a generative planner results in significantly fewer interactions. Our key finding is that the LLM as a planner can more rapidly adapt its planning strategies based on immediate feedback than LLM as a heuristic. We present evaluations and ablations on Robotouille and PDDL planning benchmarks and discuss connections to existing theory on query-efficient planning algorithms. Code is available at https://github.com/portal-cornell/llms-for-planning
One-Shot Imitation under Mismatched Execution
Sep 10, 2024Human demonstrations as prompts are a powerful way to program robots to do long-horizon manipulation tasks. However, directly translating such demonstrations into robot-executable actions poses significant challenges due to execution mismatches, such as different movement styles and physical capabilities. Existing methods either rely on robot-demonstrator paired data, which is infeasible to scale, or overly rely on frame-level visual similarities, which fail to hold. To address these challenges, we propose RHyME, a novel framework that automatically establishes task execution correspondences between the robot and the demonstrator by using optimal transport costs. Given long-horizon robot demonstrations, RHyME synthesizes semantically equivalent human demonstrations by retrieving and composing similar short-horizon human clips, facilitating effective policy training without the need for paired data. We show that RHyME outperforms a range of baselines across various cross-embodiment datasets on all degrees of mismatches. Through detailed analysis, we uncover insights for learning and leveraging cross-embodiment visual representations.
MOSAIC: A Modular System for Assistive and Interactive Cooking
Feb 29, 2024We present MOSAIC, a modular architecture for home robots to perform complex collaborative tasks, such as cooking with everyday users. MOSAIC tightly collaborates with humans, interacts with users using natural language, coordinates multiple robots, and manages an open vocabulary of everyday objects. At its core, MOSAIC employs modularity: it leverages multiple large-scale pre-trained models for general tasks like language and image recognition, while using streamlined modules designed for task-specific control. We extensively evaluate MOSAIC on 60 end-to-end trials where two robots collaborate with a human user to cook a combination of 6 recipes. We also extensively test individual modules with 180 episodes of visuomotor picking, 60 episodes of human motion forecasting, and 46 online user evaluations of the task planner. We show that MOSAIC is able to efficiently collaborate with humans by running the overall system end-to-end with a real human user, completing 68.3% (41/60) collaborative cooking trials of 6 different recipes with a subtask completion rate of 91.6%. Finally, we discuss the limitations of the current system and exciting open challenges in this domain. The project's website is at https://portal-cornell.github.io/MOSAIC/
InteRACT: Transformer Models for Human Intent Prediction Conditioned on Robot Actions
Nov 21, 2023In collaborative human-robot manipulation, a robot must predict human intents and adapt its actions accordingly to smoothly execute tasks. However, the human's intent in turn depends on actions the robot takes, creating a chicken-or-egg problem. Prior methods ignore such inter-dependency and instead train marginal intent prediction models independent of robot actions. This is because training conditional models is hard given a lack of paired human-robot interaction datasets. Can we instead leverage large-scale human-human interaction data that is more easily accessible? Our key insight is to exploit a correspondence between human and robot actions that enables transfer learning from human-human to human-robot data. We propose a novel architecture, InteRACT, that pre-trains a conditional intent prediction model on large human-human datasets and fine-tunes on a small human-robot dataset. We evaluate on a set of real-world collaborative human-robot manipulation tasks and show that our conditional model improves over various marginal baselines. We also introduce new techniques to tele-operate a 7-DoF robot arm and collect a diverse range of human-robot collaborative manipulation data, which we open-source.
ManiCast: Collaborative Manipulation with Cost-Aware Human Forecasting
Oct 20, 2023



Seamless human-robot manipulation in close proximity relies on accurate forecasts of human motion. While there has been significant progress in learning forecast models at scale, when applied to manipulation tasks, these models accrue high errors at critical transition points leading to degradation in downstream planning performance. Our key insight is that instead of predicting the most likely human motion, it is sufficient to produce forecasts that capture how future human motion would affect the cost of a robot's plan. We present ManiCast, a novel framework that learns cost-aware human forecasts and feeds them to a model predictive control planner to execute collaborative manipulation tasks. Our framework enables fluid, real-time interactions between a human and a 7-DoF robot arm across a number of real-world tasks such as reactive stirring, object handovers, and collaborative table setting. We evaluate both the motion forecasts and the end-to-end forecaster-planner system against a range of learned and heuristic baselines while additionally contributing new datasets. We release our code and datasets at https://portal-cornell.github.io/manicast/.
A Game-Theoretic Framework for Joint Forecasting and Planning
Aug 11, 2023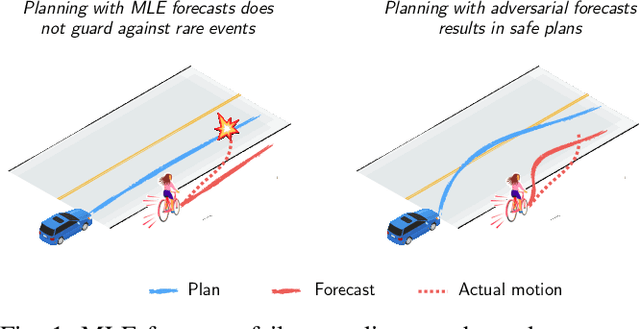
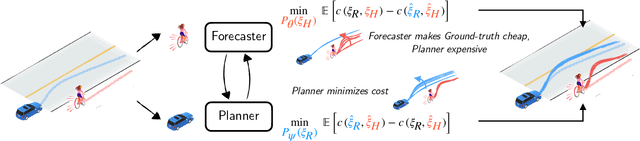
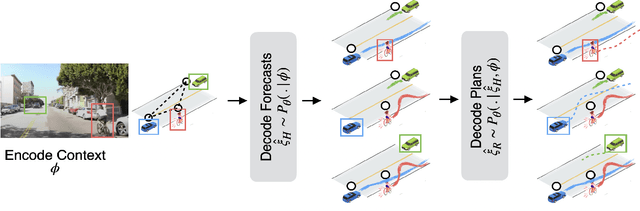

Planning safe robot motions in the presence of humans requires reliable forecasts of future human motion. However, simply predicting the most likely motion from prior interactions does not guarantee safety. Such forecasts fail to model the long tail of possible events, which are rarely observed in limited datasets. On the other hand, planning for worst-case motions leads to overtly conservative behavior and a ``frozen robot''. Instead, we aim to learn forecasts that predict counterfactuals that humans guard against. We propose a novel game-theoretic framework for joint planning and forecasting with the payoff being the performance of the planner against the demonstrator, and present practical algorithms to train models in an end-to-end fashion. We demonstrate that our proposed algorithm results in safer plans in a crowd navigation simulator and real-world datasets of pedestrian motion. We release our code at https://github.com/portal-cornell/Game-Theoretic-Forecasting-Planning.
RAFT: Rationale adaptor for few-shot abusive language detection
Nov 30, 2022

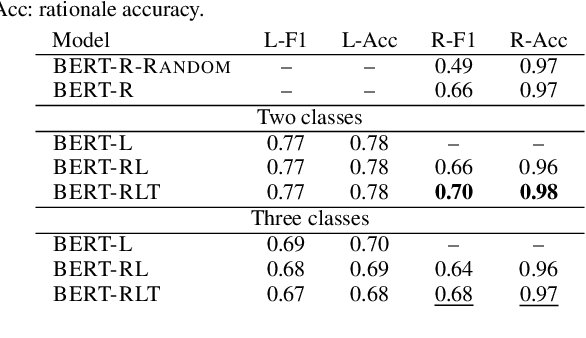

Abusive language is a concerning problem in online social media. Past research on detecting abusive language covers different platforms, languages, demographies, etc. However, models trained using these datasets do not perform well in cross-domain evaluation settings. To overcome this, a common strategy is to use a few samples from the target domain to train models to get better performance in that domain (cross-domain few-shot training). However, this might cause the models to overfit the artefacts of those samples. A compelling solution could be to guide the models toward rationales, i.e., spans of text that justify the text's label. This method has been found to improve model performance in the in-domain setting across various NLP tasks. In this paper, we propose RAFT (Rationale Adaptor for Few-shoT classification) for abusive language detection. We first build a multitask learning setup to jointly learn rationales, targets, and labels, and find a significant improvement of 6% macro F1 on the rationale detection task over training solely rationale classifiers. We introduce two rationale-integrated BERT-based architectures (the RAFT models) and evaluate our systems over five different abusive language datasets, finding that in the few-shot classification setting, RAFT-based models outperform baseline models by about 7% in macro F1 scores and perform competitively to models finetuned on other source domains. Furthermore, RAFT-based models outperform LIME/SHAP-based approaches in terms of plausibility and are close in performance in terms of faithfulness.
indicnlp@kgp at DravidianLangTech-EACL2021: Offensive Language Identification in Dravidian Languages
Feb 14, 2021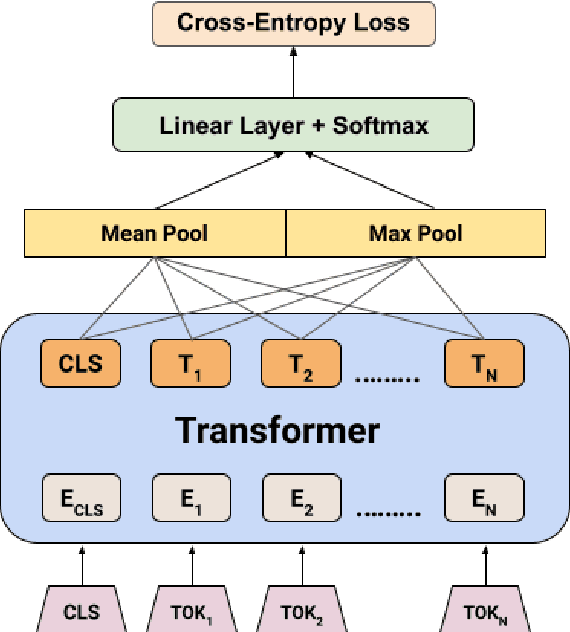
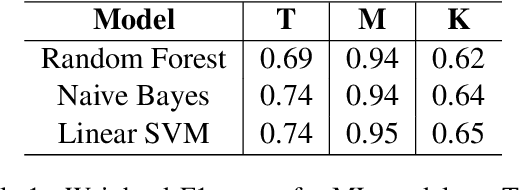
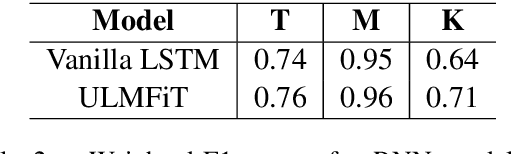
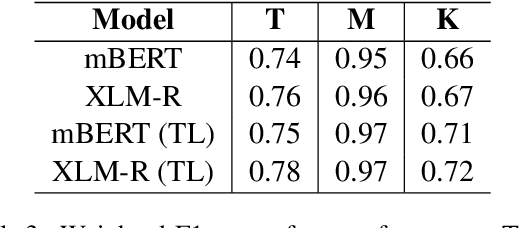
The paper presents the submission of the team indicnlp@kgp to the EACL 2021 shared task "Offensive Language Identification in Dravidian Languages." The task aimed to classify different offensive content types in 3 code-mixed Dravidian language datasets. The work leverages existing state of the art approaches in text classification by incorporating additional data and transfer learning on pre-trained models. Our final submission is an ensemble of an AWD-LSTM based model along with 2 different transformer model architectures based on BERT and RoBERTa. We achieved weighted-average F1 scores of 0.97, 0.77, and 0.72 in the Malayalam-English, Tamil-English, and Kannada-English datasets ranking 1st, 2nd, and 3rd on the respective tasks.