Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeindicnlp@kgp at DravidianLangTech-EACL2021: Offensive Language Identification in Dravidian Languages
Paper and Code
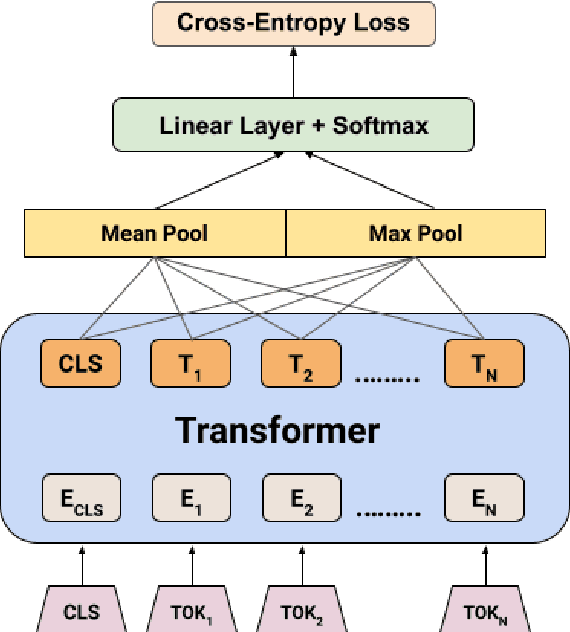
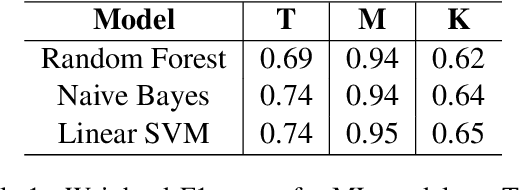
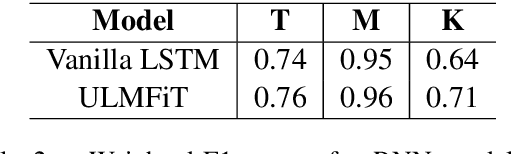
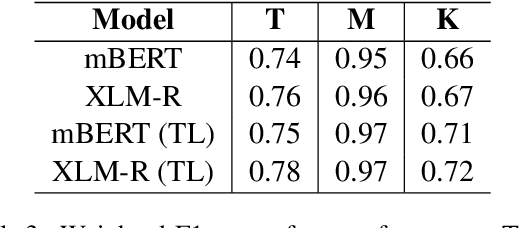
The paper presents the submission of the team indicnlp@kgp to the EACL 2021 shared task "Offensive Language Identification in Dravidian Languages." The task aimed to classify different offensive content types in 3 code-mixed Dravidian language datasets. The work leverages existing state of the art approaches in text classification by incorporating additional data and transfer learning on pre-trained models. Our final submission is an ensemble of an AWD-LSTM based model along with 2 different transformer model architectures based on BERT and RoBERTa. We achieved weighted-average F1 scores of 0.97, 0.77, and 0.72 in the Malayalam-English, Tamil-English, and Kannada-English datasets ranking 1st, 2nd, and 3rd on the respective tasks.
View paper on