 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Unreasonable Effectiveness of Scaling Agents for Computer Use
Oct 02, 2025Computer-use agents (CUAs) hold promise for automating everyday digital tasks, but their unreliability and high variance hinder their application to long-horizon, complex tasks. We introduce Behavior Best-of-N (bBoN), a method that scales over agents by generating multiple rollouts and selecting among them using behavior narratives that describe the agents' rollouts. It enables both wide exploration and principled trajectory selection, substantially improving robustness and success rates. On OSWorld, our bBoN scaling method establishes a new state of the art (SoTA) at 69.9%, significantly outperforming prior methods and approaching human-level performance at 72%, with comprehensive ablations validating key design choices. We further demonstrate strong generalization results to different operating systems on WindowsAgentArena and AndroidWorld. Crucially, our results highlight the unreasonable effectiveness of scaling CUAs, when you do it right: effective scaling requires structured trajectory understanding and selection, and bBoN provides a practical framework to achieve this.
Skill-Aligned Fairness in Multi-Agent Learning for Collaboration in Healthcare
Aug 26, 2025Fairness in multi-agent reinforcement learning (MARL) is often framed as a workload balance problem, overlooking agent expertise and the structured coordination required in real-world domains. In healthcare, equitable task allocation requires workload balance or expertise alignment to prevent burnout and overuse of highly skilled agents. Workload balance refers to distributing an approximately equal number of subtasks or equalised effort across healthcare workers, regardless of their expertise. We make two contributions to address this problem. First, we propose FairSkillMARL, a framework that defines fairness as the dual objective of workload balance and skill-task alignment. Second, we introduce MARLHospital, a customizable healthcare-inspired environment for modeling team compositions and energy-constrained scheduling impacts on fairness, as no existing simulators are well-suited for this problem. We conducted experiments to compare FairSkillMARL in conjunction with four standard MARL methods, and against two state-of-the-art fairness metrics. Our results suggest that fairness based solely on equal workload might lead to task-skill mismatches and highlight the need for more robust metrics that capture skill-task misalignment. Our work provides tools and a foundation for studying fairness in heterogeneous multi-agent systems where aligning effort with expertise is critical.
Multi-Turn Code Generation Through Single-Step Rewards
Feb 27, 2025We address the problem of code generation from multi-turn execution feedback. Existing methods either generate code without feedback or use complex, hierarchical reinforcement learning to optimize multi-turn rewards. We propose a simple yet scalable approach, $\mu$Code, that solves multi-turn code generation using only single-step rewards. Our key insight is that code generation is a one-step recoverable MDP, where the correct code can be recovered from any intermediate code state in a single turn. $\mu$Code iteratively trains both a generator to provide code solutions conditioned on multi-turn execution feedback and a verifier to score the newly generated code. Experimental evaluations show that our approach achieves significant improvements over the state-of-the-art baselines. We provide analysis of the design choices of the reward models and policy, and show the efficacy of $\mu$Code at utilizing the execution feedback. Our code is available at https://github.com/portal-cornell/muCode.
Robotouille: An Asynchronous Planning Benchmark for LLM Agents
Feb 06, 2025Effective asynchronous planning, or the ability to efficiently reason and plan over states and actions that must happen in parallel or sequentially, is essential for agents that must account for time delays, reason over diverse long-horizon tasks, and collaborate with other agents. While large language model (LLM) agents show promise in high-level task planning, current benchmarks focus primarily on short-horizon tasks and do not evaluate such asynchronous planning capabilities. We introduce Robotouille, a challenging benchmark environment designed to test LLM agents' ability to handle long-horizon asynchronous scenarios. Our synchronous and asynchronous datasets capture increasingly complex planning challenges that go beyond existing benchmarks, requiring agents to manage overlapping tasks and interruptions. Our results show that ReAct (gpt4-o) achieves 47% on synchronous tasks but only 11% on asynchronous tasks, highlighting significant room for improvement. We further analyze failure modes, demonstrating the need for LLM agents to better incorporate long-horizon feedback and self-audit their reasoning during task execution. Code is available at https://github.com/portal-cornell/robotouille.
Query-Efficient Planning with Language Models
Dec 09, 2024Planning in complex environments requires an agent to efficiently query a world model to find a feasible sequence of actions from start to goal. Recent work has shown that Large Language Models (LLMs), with their rich prior knowledge and reasoning capabilities, can potentially help with planning by searching over promising states and adapting to feedback from the world. In this paper, we propose and study two fundamentally competing frameworks that leverage LLMs for query-efficient planning. The first uses LLMs as a heuristic within a search-based planner to select promising nodes to expand and propose promising actions. The second uses LLMs as a generative planner to propose an entire sequence of actions from start to goal, query a world model, and adapt based on feedback. We show that while both approaches improve upon comparable baselines, using an LLM as a generative planner results in significantly fewer interactions. Our key finding is that the LLM as a planner can more rapidly adapt its planning strategies based on immediate feedback than LLM as a heuristic. We present evaluations and ablations on Robotouille and PDDL planning benchmarks and discuss connections to existing theory on query-efficient planning algorithms. Code is available at https://github.com/portal-cornell/llms-for-planning
APRICOT: Active Preference Learning and Constraint-Aware Task Planning with LLMs
Oct 25, 2024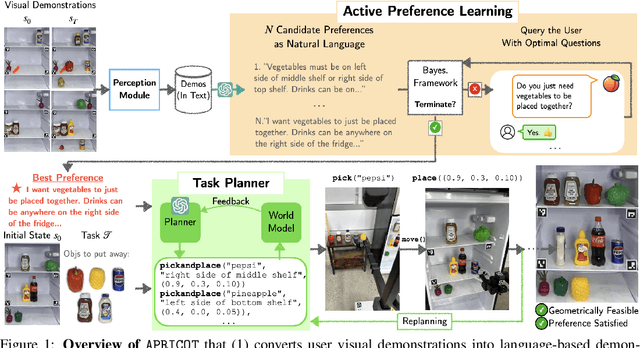



Home robots performing personalized tasks must adeptly balance user preferences with environmental affordances. We focus on organization tasks within constrained spaces, such as arranging items into a refrigerator, where preferences for placement collide with physical limitations. The robot must infer user preferences based on a small set of demonstrations, which is easier for users to provide than extensively defining all their requirements. While recent works use Large Language Models (LLMs) to learn preferences from user demonstrations, they encounter two fundamental challenges. First, there is inherent ambiguity in interpreting user actions, as multiple preferences can often explain a single observed behavior. Second, not all user preferences are practically feasible due to geometric constraints in the environment. To address these challenges, we introduce APRICOT, a novel approach that merges LLM-based Bayesian active preference learning with constraint-aware task planning. APRICOT refines its generated preferences by actively querying the user and dynamically adapts its plan to respect environmental constraints. We evaluate APRICOT on a dataset of diverse organization tasks and demonstrate its effectiveness in real-world scenarios, showing significant improvements in both preference satisfaction and plan feasibility. The project website is at https://portal-cornell.github.io/apricot/
MOSAIC: A Modular System for Assistive and Interactive Cooking
Feb 29, 2024We present MOSAIC, a modular architecture for home robots to perform complex collaborative tasks, such as cooking with everyday users. MOSAIC tightly collaborates with humans, interacts with users using natural language, coordinates multiple robots, and manages an open vocabulary of everyday objects. At its core, MOSAIC employs modularity: it leverages multiple large-scale pre-trained models for general tasks like language and image recognition, while using streamlined modules designed for task-specific control. We extensively evaluate MOSAIC on 60 end-to-end trials where two robots collaborate with a human user to cook a combination of 6 recipes. We also extensively test individual modules with 180 episodes of visuomotor picking, 60 episodes of human motion forecasting, and 46 online user evaluations of the task planner. We show that MOSAIC is able to efficiently collaborate with humans by running the overall system end-to-end with a real human user, completing 68.3% (41/60) collaborative cooking trials of 6 different recipes with a subtask completion rate of 91.6%. Finally, we discuss the limitations of the current system and exciting open challenges in this domain. The project's website is at https://portal-cornell.github.io/MOSAIC/
Demo2Code: From Summarizing Demonstrations to Synthesizing Code via Extended Chain-of-Thought
Jun 08, 2023Language instructions and demonstrations are two natural ways for users to teach robots personalized tasks. Recent progress in Large Language Models (LLMs) has shown impressive performance in translating language instructions into code for robotic tasks. However, translating demonstrations into task code continues to be a challenge due to the length and complexity of both demonstrations and code, making learning a direct mapping intractable. This paper presents Demo2Code, a novel framework that generates robot task code from demonstrations via an extended chain-of-thought and defines a common latent specification to connect the two. Our framework employs a robust two-stage process: (1) a recursive summarization technique that condenses demonstrations into concise specifications, and (2) a code synthesis approach that expands each function recursively from the generated specifications. We conduct extensive evaluation on various robot task benchmarks, including a novel game benchmark Robotouille, designed to simulate diverse cooking tasks in a kitchen environment. The project's website is available at https://portal-cornell.github.io/demo2code-webpage