 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedGraph: A Research Library and Benchmark for Federated Graph Learning
Oct 08, 2024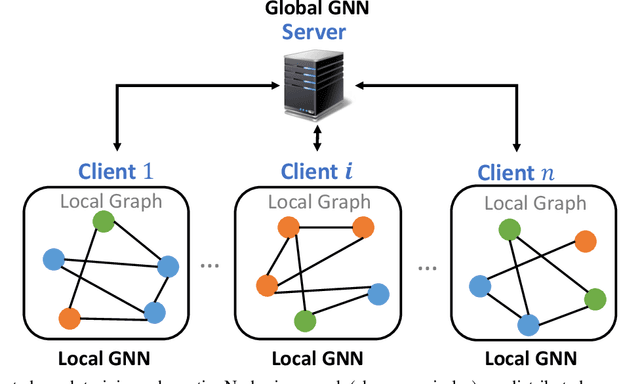
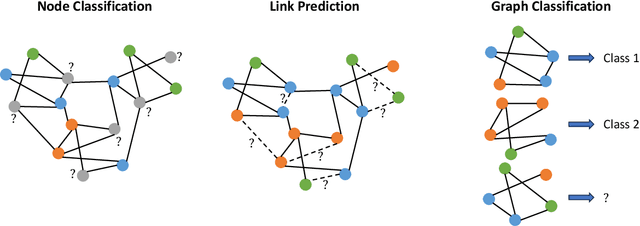
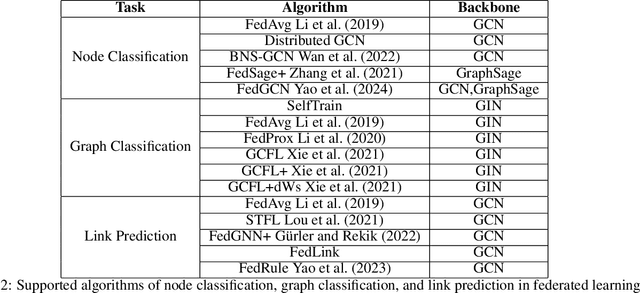
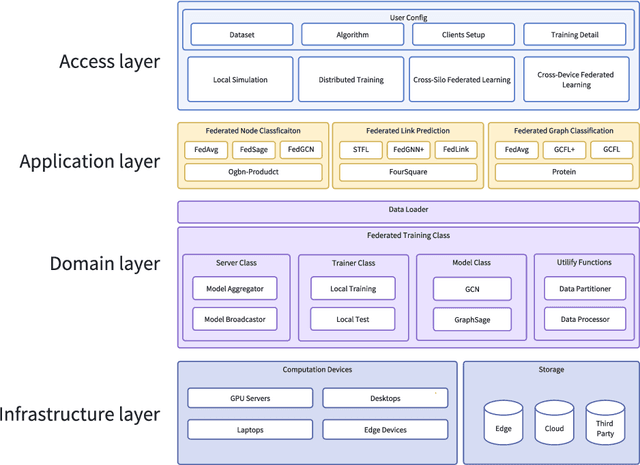
Federated graph learning is an emerging field with significant practical challenges. While many algorithms have been proposed to enhance model accuracy, their system performance, crucial for real-world deployment, is often overlooked. To address this gap, we present FedGraph, a research library designed for practical distributed deployment and benchmarking in federated graph learning. FedGraph supports a range of state-of-the-art methods and includes profiling tools for system performance evaluation, focusing on communication and computation costs during training. FedGraph can then facilitate the development of practical applications and guide the design of future algorithms.
MOSAIC: A Modular System for Assistive and Interactive Cooking
Feb 29, 2024We present MOSAIC, a modular architecture for home robots to perform complex collaborative tasks, such as cooking with everyday users. MOSAIC tightly collaborates with humans, interacts with users using natural language, coordinates multiple robots, and manages an open vocabulary of everyday objects. At its core, MOSAIC employs modularity: it leverages multiple large-scale pre-trained models for general tasks like language and image recognition, while using streamlined modules designed for task-specific control. We extensively evaluate MOSAIC on 60 end-to-end trials where two robots collaborate with a human user to cook a combination of 6 recipes. We also extensively test individual modules with 180 episodes of visuomotor picking, 60 episodes of human motion forecasting, and 46 online user evaluations of the task planner. We show that MOSAIC is able to efficiently collaborate with humans by running the overall system end-to-end with a real human user, completing 68.3% (41/60) collaborative cooking trials of 6 different recipes with a subtask completion rate of 91.6%. Finally, we discuss the limitations of the current system and exciting open challenges in this domain. The project's website is at https://portal-cornell.github.io/MOSAIC/
Polarized Self-Attention: Towards High-quality Pixel-wise Regression
Jul 08, 2021

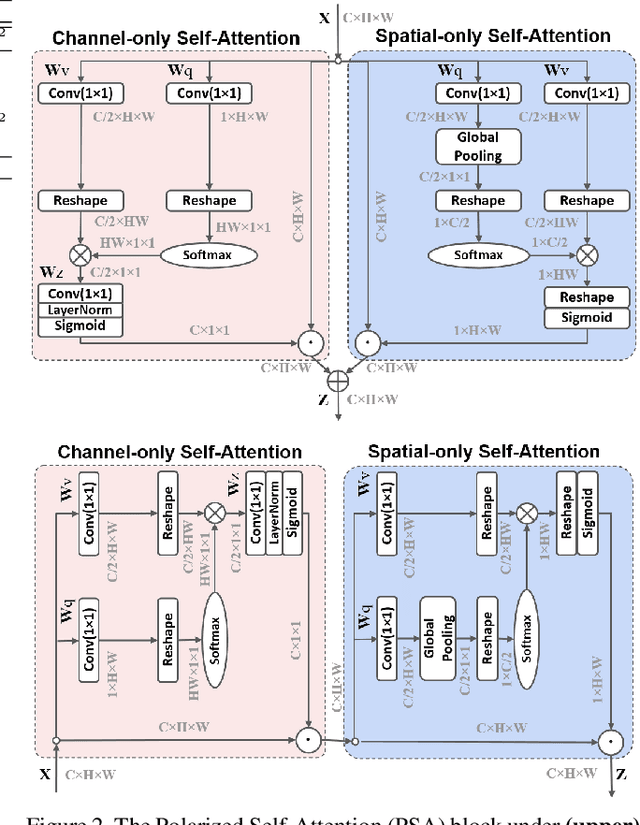

Pixel-wise regression is probably the most common problem in fine-grained computer vision tasks, such as estimating keypoint heatmaps and segmentation masks. These regression problems are very challenging particularly because they require, at low computation overheads, modeling long-range dependencies on high-resolution inputs/outputs to estimate the highly nonlinear pixel-wise semantics. While attention mechanisms in Deep Convolutional Neural Networks(DCNNs) has become popular for boosting long-range dependencies, element-specific attention, such as Nonlocal blocks, is highly complex and noise-sensitive to learn, and most of simplified attention hybrids try to reach the best compromise among multiple types of tasks. In this paper, we present the Polarized Self-Attention(PSA) block that incorporates two critical designs towards high-quality pixel-wise regression: (1) Polarized filtering: keeping high internal resolution in both channel and spatial attention computation while completely collapsing input tensors along their counterpart dimensions. (2) Enhancement: composing non-linearity that directly fits the output distribution of typical fine-grained regression, such as the 2D Gaussian distribution (keypoint heatmaps), or the 2D Binormial distribution (binary segmentation masks). PSA appears to have exhausted the representation capacity within its channel-only and spatial-only branches, such that there is only marginal metric differences between its sequential and parallel layouts. Experimental results show that PSA boosts standard baselines by $2-4$ points, and boosts state-of-the-arts by $1-2$ points on 2D pose estimation and semantic segmentation benchmarks.