 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlay2Perfect: What Matters in Dexterous Play Pretraining for Precise Assembly?
Jun 24, 2026Multi-fingered robots promise the speed and dexterity of human hands, yet challenging problems such as precise assembly have remained out of reach. These tasks are contact-rich, making data collection for imitation learning difficult, and sparse-reward, making direct exploration with reinforcement learning (RL) intractable. Consequently, prior work has made progress by structuring the problem with specialized grippers, tool attachments, and environment fixtures. In this work, we argue that before a robot can perfect precise assembly, it must first learn to play. We further ask the question: what factors in the process of learning to play matter for precise assembly? We propose Play2Perfect, an RL framework for task-agnostic pretraining through play on diverse objects and goals, which is then perfected on precise assembly. The goal of play is to acquire reusable manipulation priors, such as grasping, in-hand reorientation and pose reaching. Finetuning then adapts this general prior to assembly, focusing exploration on the final contact-rich, high-precision interactions needed for success. We systematically study key design choices in play pretraining, including object diversity, training objective, trajectory diversity, and goal precision. We show that our prior is 33x more sample-efficient than RL training from scratch, even when provided with dense, multi-stage rewards. We demonstrate zero-shot sim-to-real transfer, achieving 60% success on tight insertions with only 0.5 mm contact clearance, and over 50% success on long-horizon multi-part assembly and screwing.
CHORUS: Decentralized Multi-Embodiment Collaboration with One VLA Policy
Jun 10, 2026Multi-robot collaboration allows robots to efficiently take on a wide range of tasks, from moving a couch through a doorway to assembling structures on a construction site. However, achieving such coordination in mobile multi-robot settings remains challenging: centralized methods conditioned on the combined observations of a team scale poorly with team size, and decentralized methods that train one policy per robot often require explicit alignment procedures or information sharing at inference time to overcome partial observability. Our key insight is that the visuomotor priors of pretrained vision-language-action (VLA) models should enable reactive, decentralized collaboration from each robot's local observations alone, without these inference-time assumptions. We propose CHORUS, a framework that adapts a single VLA backbone to control diverse, multi-robot teams. At inference time, each robot runs an independent copy of CHORUS, conditioned only on its own observations and a robot-identifying prompt. In real-world experiments including mobile tape measurement, library book handovers, and laundry basket lifting, CHORUS achieves a 64% point improvement over decentralized, from-scratch models, improves reactivity to teammate behavior by 40% points, and outperforms centralized baselines. Together, these results show that a shared VLA backbone is capable of achieving decentralized multi-robot collaboration, without per-robot policies or inter-robot communication at inference.
Breaking Lock-In: Preserving Steerability under Low-Data VLA Post-Training
Apr 25, 2026Have you ever post-trained a generalist vision-language-action (VLA) policy on a small demonstration dataset, only to find that it stops responding to new instructions and is limited to behaviors observed during post-training? We identify this phenomenon as lock-in: after low-data, supervised fine-tuning (SFT), the policy becomes overly specialized to the post-training data and fails to generalize to novel instructions, manifesting as concept lock-in (fixation on training objects/attributes) and spatial lock-in (fixation on training spatial targets). Many existing remedies introduce additional supervision signals, such as those derived from foundation models or auxiliary objectives, or rely on augmented datasets to recover generalization. In this paper, we show that the policy's internal pre-trained knowledge is sufficient: DeLock mitigates lock-in by preserving visual grounding during post-training and applying test-time contrastive prompt guidance to steer the policy's denoising dynamics according to novel instructions. Across eight simulation and real-world evaluations, DeLock consistently outperforms strong baselines and matches or exceeds the performance of a state-of-the-art generalist policy post-trained with substantially more curated demonstrations.
Are Foundation Models the Route to Full-Stack Transfer in Robotics?
Feb 25, 2026In humans and robots alike, transfer learning occurs at different levels of abstraction, from high-level linguistic transfer to low-level transfer of motor skills. In this article, we provide an overview of the impact that foundation models and transformer networks have had on these different levels, bringing robots closer than ever to "full-stack transfer". Considering LLMs, VLMs and VLAs from a robotic transfer learning perspective allows us to highlight recurring concepts for transfer, beyond specific implementations. We also consider the challenges of data collection and transfer benchmarks for robotics in the age of foundation models. Are foundation models the route to full-stack transfer in robotics? Our expectation is that they will certainly stay on this route as a key technology.
SimToolReal: An Object-Centric Policy for Zero-Shot Dexterous Tool Manipulation
Feb 18, 2026The ability to manipulate tools significantly expands the set of tasks a robot can perform. Yet, tool manipulation represents a challenging class of dexterity, requiring grasping thin objects, in-hand object rotations, and forceful interactions. Since collecting teleoperation data for these behaviors is challenging, sim-to-real reinforcement learning (RL) is a promising alternative. However, prior approaches typically require substantial engineering effort to model objects and tune reward functions for each task. In this work, we propose SimToolReal, taking a step towards generalizing sim-to-real RL policies for tool manipulation. Instead of focusing on a single object and task, we procedurally generate a large variety of tool-like object primitives in simulation and train a single RL policy with the universal goal of manipulating each object to random goal poses. This approach enables SimToolReal to perform general dexterous tool manipulation at test-time without any object or task-specific training. We demonstrate that SimToolReal outperforms prior retargeting and fixed-grasp methods by 37% while matching the performance of specialist RL policies trained on specific target objects and tasks. Finally, we show that SimToolReal generalizes across a diverse set of everyday tools, achieving strong zero-shot performance over 120 real-world rollouts spanning 24 tasks, 12 object instances, and 6 tool categories.
Gentle Object Retraction in Dense Clutter Using Multimodal Force Sensing and Imitation Learning
Aug 26, 2025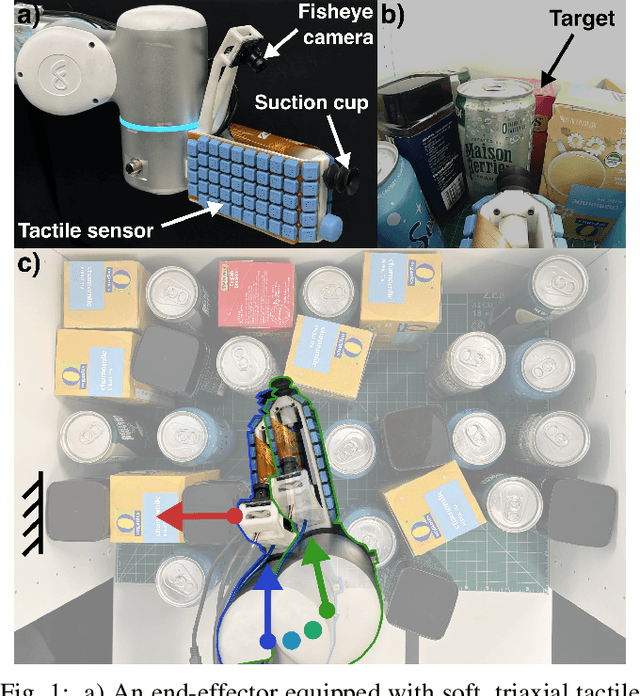
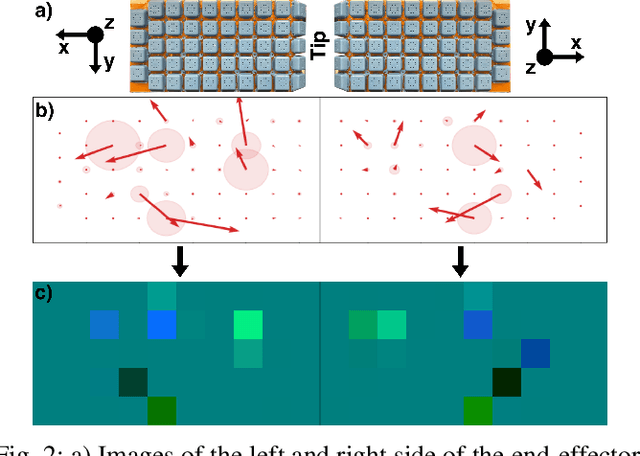
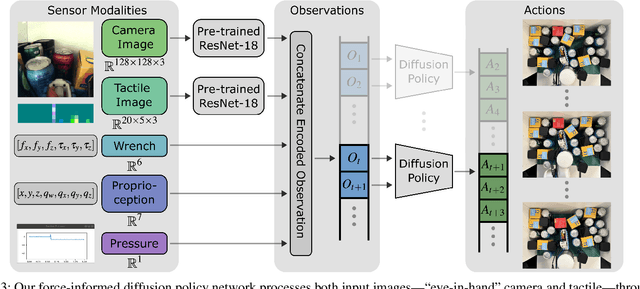
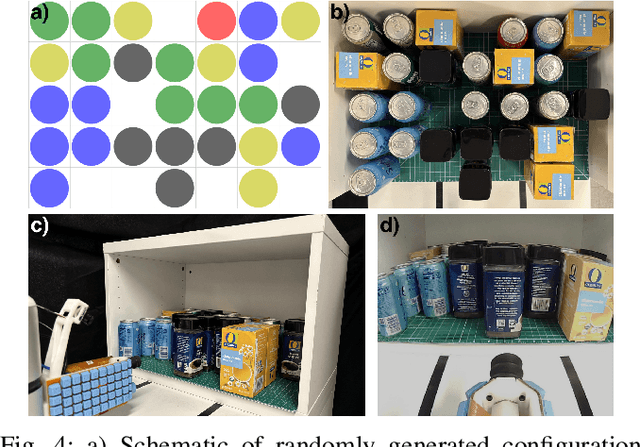
Dense collections of movable objects are common in everyday spaces -- from cabinets in a home to shelves in a warehouse. Safely retracting objects from such collections is difficult for robots, yet people do it easily, using non-prehensile tactile sensing on the sides and backs of their hands and arms. We investigate the role of such sensing for training robots to gently reach into constrained clutter and extract objects. The available sensing modalities are (1) "eye-in-hand" vision, (2) proprioception, (3) non-prehensile triaxial tactile sensing, (4) contact wrenches estimated from joint torques, and (5) a measure of successful object acquisition obtained by monitoring the vacuum line of a suction cup. We use imitation learning to train policies from a set of demonstrations on randomly generated scenes, then conduct an ablation study of wrench and tactile information. We evaluate each policy's performance across 40 unseen environment configurations. Policies employing any force sensing show fewer excessive force failures, an increased overall success rate, and faster completion times. The best performance is achieved using both tactile and wrench information, producing an 80% improvement above the baseline without force information.
Masquerade: Learning from In-the-wild Human Videos using Data-Editing
Aug 13, 2025



Robot manipulation research still suffers from significant data scarcity: even the largest robot datasets are orders of magnitude smaller and less diverse than those that fueled recent breakthroughs in language and vision. We introduce Masquerade, a method that edits in-the-wild egocentric human videos to bridge the visual embodiment gap between humans and robots and then learns a robot policy with these edited videos. Our pipeline turns each human video into robotized demonstrations by (i) estimating 3-D hand poses, (ii) inpainting the human arms, and (iii) overlaying a rendered bimanual robot that tracks the recovered end-effector trajectories. Pre-training a visual encoder to predict future 2-D robot keypoints on 675K frames of these edited clips, and continuing that auxiliary loss while fine-tuning a diffusion policy head on only 50 robot demonstrations per task, yields policies that generalize significantly better than prior work. On three long-horizon, bimanual kitchen tasks evaluated in three unseen scenes each, Masquerade outperforms baselines by 5-6x. Ablations show that both the robot overlay and co-training are indispensable, and performance scales logarithmically with the amount of edited human video. These results demonstrate that explicitly closing the visual embodiment gap unlocks a vast, readily available source of data from human videos that can be used to improve robot policies.
Constraint-Preserving Data Generation for Visuomotor Policy Learning
Aug 05, 2025



Large-scale demonstration data has powered key breakthroughs in robot manipulation, but collecting that data remains costly and time-consuming. We present Constraint-Preserving Data Generation (CP-Gen), a method that uses a single expert trajectory to generate robot demonstrations containing novel object geometries and poses. These generated demonstrations are used to train closed-loop visuomotor policies that transfer zero-shot to the real world and generalize across variations in object geometries and poses. Similar to prior work using pose variations for data generation, CP-Gen first decomposes expert demonstrations into free-space motions and robot skills. But unlike those works, we achieve geometry-aware data generation by formulating robot skills as keypoint-trajectory constraints: keypoints on the robot or grasped object must track a reference trajectory defined relative to a task-relevant object. To generate a new demonstration, CP-Gen samples pose and geometry transforms for each task-relevant object, then applies these transforms to the object and its associated keypoints or keypoint trajectories. We optimize robot joint configurations so that the keypoints on the robot or grasped object track the transformed keypoint trajectory, and then motion plan a collision-free path to the first optimized joint configuration. Experiments on 16 simulation tasks and four real-world tasks, featuring multi-stage, non-prehensile and tight-tolerance manipulation, show that policies trained using CP-Gen achieve an average success rate of 77%, outperforming the best baseline that achieves an average of 50%.
Scaffolding Dexterous Manipulation with Vision-Language Models
Jun 24, 2025
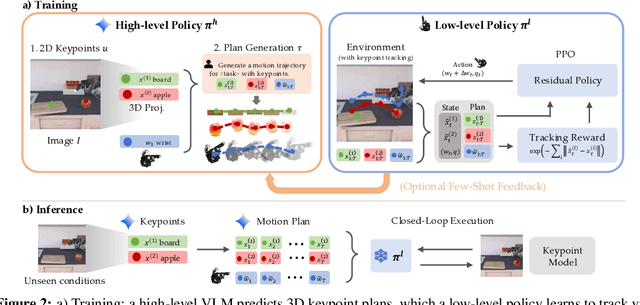
Dexterous robotic hands are essential for performing complex manipulation tasks, yet remain difficult to train due to the challenges of demonstration collection and high-dimensional control. While reinforcement learning (RL) can alleviate the data bottleneck by generating experience in simulation, it typically relies on carefully designed, task-specific reward functions, which hinder scalability and generalization. Thus, contemporary works in dexterous manipulation have often bootstrapped from reference trajectories. These trajectories specify target hand poses that guide the exploration of RL policies and object poses that enable dense, task-agnostic rewards. However, sourcing suitable trajectories - particularly for dexterous hands - remains a significant challenge. Yet, the precise details in explicit reference trajectories are often unnecessary, as RL ultimately refines the motion. Our key insight is that modern vision-language models (VLMs) already encode the commonsense spatial and semantic knowledge needed to specify tasks and guide exploration effectively. Given a task description (e.g., "open the cabinet") and a visual scene, our method uses an off-the-shelf VLM to first identify task-relevant keypoints (e.g., handles, buttons) and then synthesize 3D trajectories for hand motion and object motion. Subsequently, we train a low-level residual RL policy in simulation to track these coarse trajectories or "scaffolds" with high fidelity. Across a number of simulated tasks involving articulated objects and semantic understanding, we demonstrate that our method is able to learn robust dexterous manipulation policies. Moreover, we showcase that our method transfers to real-world robotic hands without any human demonstrations or handcrafted rewards.
CUPID: Curating Data your Robot Loves with Influence Functions
Jun 23, 2025
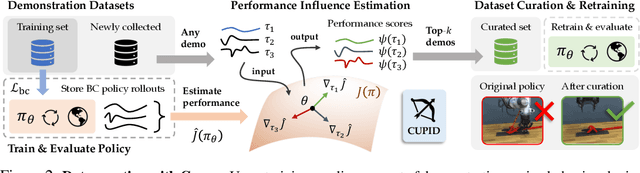
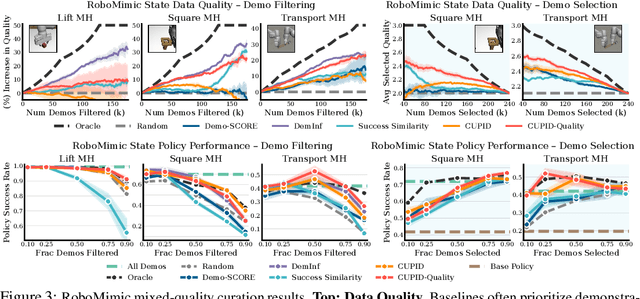
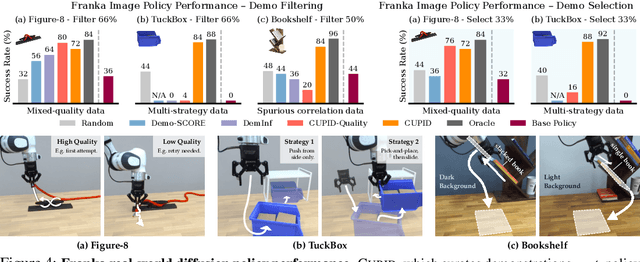
In robot imitation learning, policy performance is tightly coupled with the quality and composition of the demonstration data. Yet, developing a precise understanding of how individual demonstrations contribute to downstream outcomes - such as closed-loop task success or failure - remains a persistent challenge. We propose CUPID, a robot data curation method based on a novel influence function-theoretic formulation for imitation learning policies. Given a set of evaluation rollouts, CUPID estimates the influence of each training demonstration on the policy's expected return. This enables ranking and selection of demonstrations according to their impact on the policy's closed-loop performance. We use CUPID to curate data by 1) filtering out training demonstrations that harm policy performance and 2) subselecting newly collected trajectories that will most improve the policy. Extensive simulated and hardware experiments show that our approach consistently identifies which data drives test-time performance. For example, training with less than 33% of curated data can yield state-of-the-art diffusion policies on the simulated RoboMimic benchmark, with similar gains observed in hardware. Furthermore, hardware experiments show that our method can identify robust strategies under distribution shift, isolate spurious correlations, and even enhance the post-training of generalist robot policies. Additional materials are made available at: https://cupid-curation.github.io.