 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Machine-Generated Rationales to Facilitate Social Meaning Detection in Conversations
Jun 27, 2024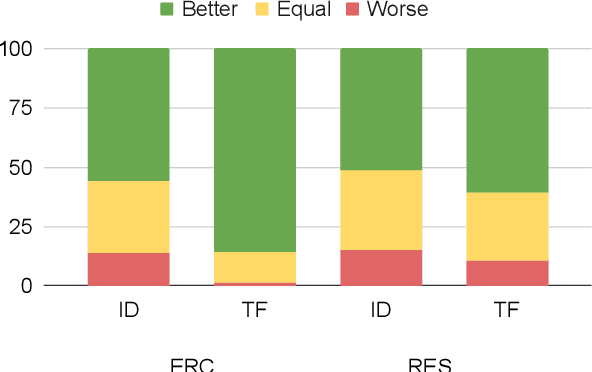
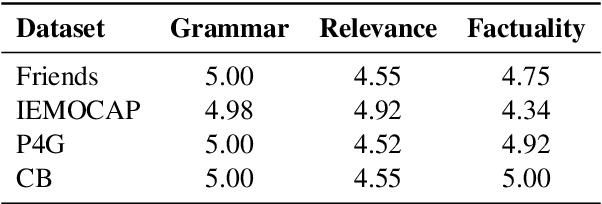
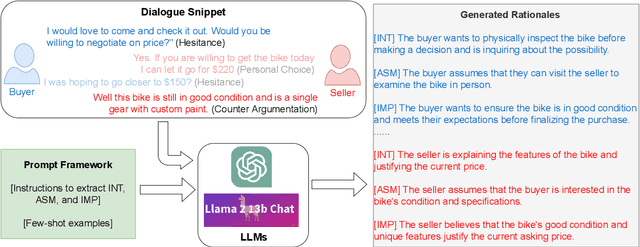

We present a generalizable classification approach that leverages Large Language Models (LLMs) to facilitate the detection of implicitly encoded social meaning in conversations. We design a multi-faceted prompt to extract a textual explanation of the reasoning that connects visible cues to underlying social meanings. These extracted explanations or rationales serve as augmentations to the conversational text to facilitate dialogue understanding and transfer. Our empirical results over 2,340 experimental settings demonstrate the significant positive impact of adding these rationales. Our findings hold true for in-domain classification, zero-shot, and few-shot domain transfer for two different social meaning detection tasks, each spanning two different corpora.
Keeping Up Appearances: Computational Modeling of Face Acts in Persuasion Oriented Discussions
Sep 24, 2020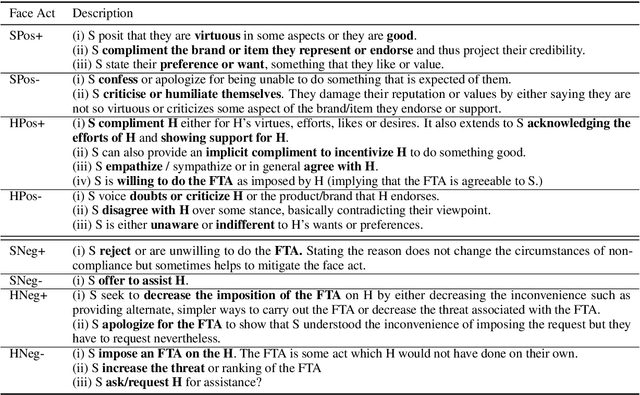
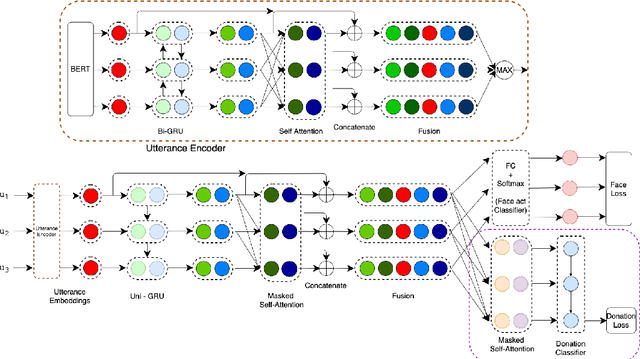
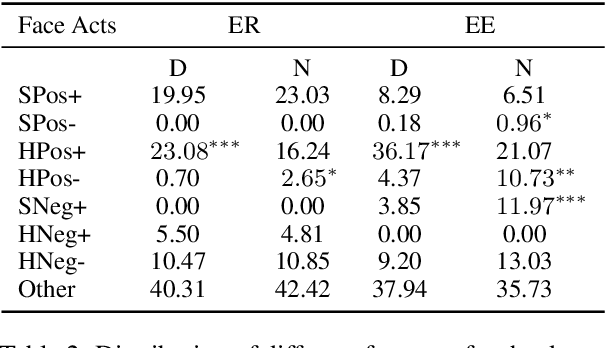
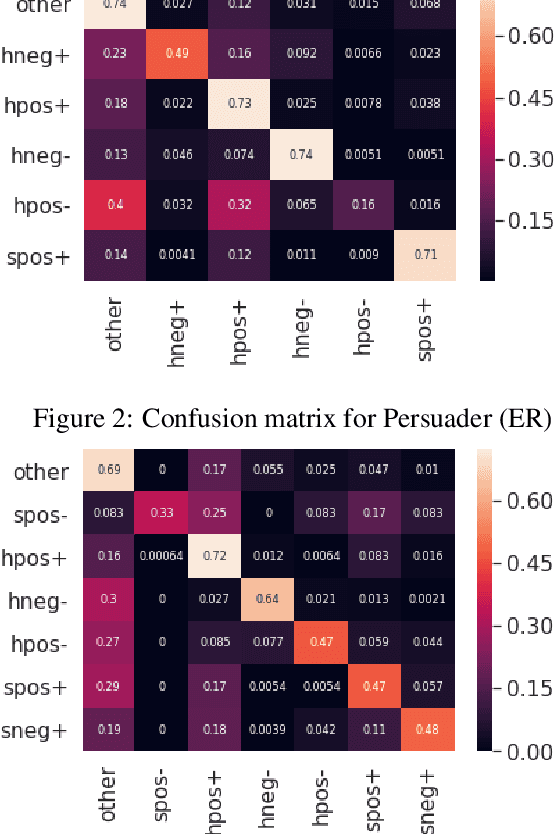
The notion of face refers to the public self-image of an individual that emerges both from the individual's own actions as well as from the interaction with others. Modeling face and understanding its state changes throughout a conversation is critical to the study of maintenance of basic human needs in and through interaction. Grounded in the politeness theory of Brown and Levinson (1978), we propose a generalized framework for modeling face acts in persuasion conversations, resulting in a reliable coding manual, an annotated corpus, and computational models. The framework reveals insights about differences in face act utilization between asymmetric roles in persuasion conversations. Using computational models, we are able to successfully identify face acts as well as predict a key conversational outcome (e.g. donation success). Finally, we model a latent representation of the conversational state to analyze the impact of predicted face acts on the probability of a positive conversational outcome and observe several correlations that corroborate previous findings.
A Machine Learning Framework for Authorship Identification From Texts
Dec 21, 2019
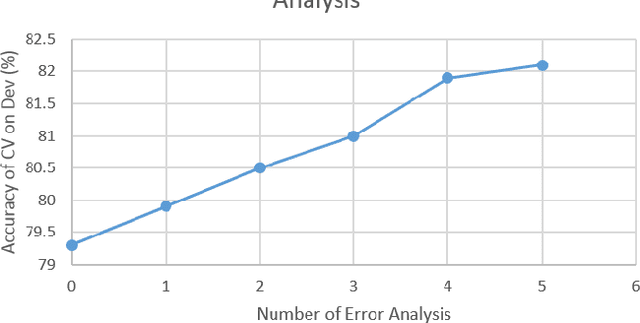
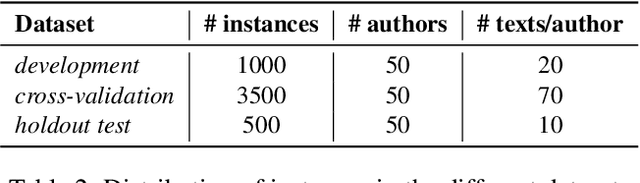
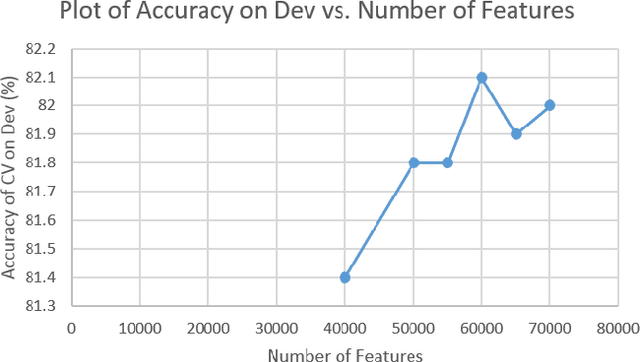
Authorship identification is a process in which the author of a text is identified. Most known literary texts can easily be attributed to a certain author because they are, for example, signed. Yet sometimes we find unfinished pieces of work or a whole bunch of manuscripts with a wide variety of possible authors. In order to assess the importance of such a manuscript, it is vital to know who wrote it. In this work, we aim to develop a machine learning framework to effectively determine authorship. We formulate the task as a single-label multi-class text categorization problem and propose a supervised machine learning framework incorporating stylometric features. This task is highly interdisciplinary in that it takes advantage of machine learning, information retrieval, and natural language processing. We present an approach and a model which learns the differences in writing style between $50$ different authors and is able to predict the author of a new text with high accuracy. The accuracy is seen to increase significantly after introducing certain linguistic stylometric features along with text features.
Linguistic Markers of Influence in Informal Interactions
Jul 14, 2017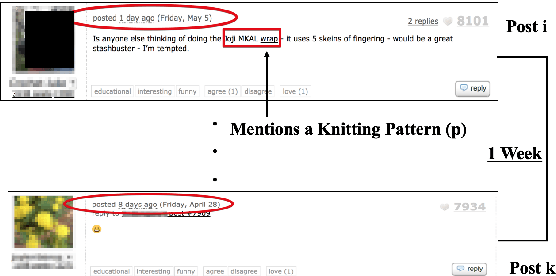
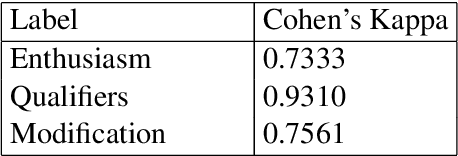
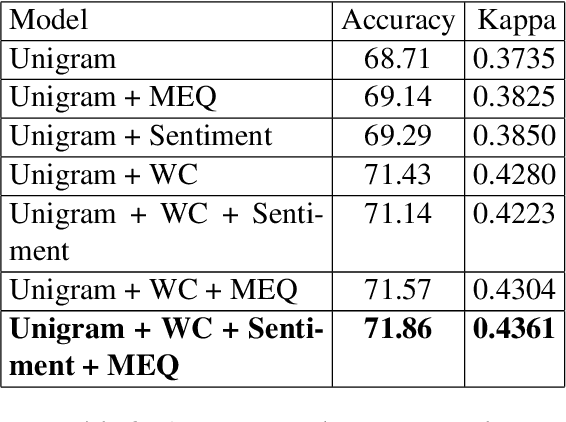
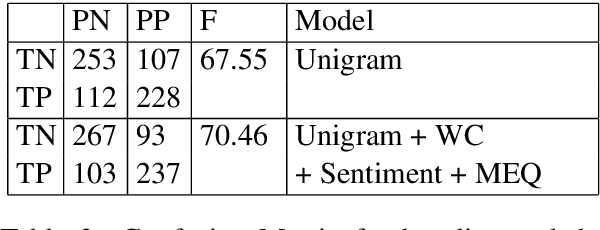
There has been a long standing interest in understanding `Social Influence' both in Social Sciences and in Computational Linguistics. In this paper, we present a novel approach to study and measure interpersonal influence in daily interactions. Motivated by the basic principles of influence, we attempt to identify indicative linguistic features of the posts in an online knitting community. We present the scheme used to operationalize and label the posts with indicator features. Experiments with the identified features show an improvement in the classification accuracy of influence by 3.15%. Our results illustrate the important correlation between the characteristics of the language and its potential to influence others.