 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End ML System for Personalized Conversational Voice Models in Walmart E-Commerce
Nov 02, 2020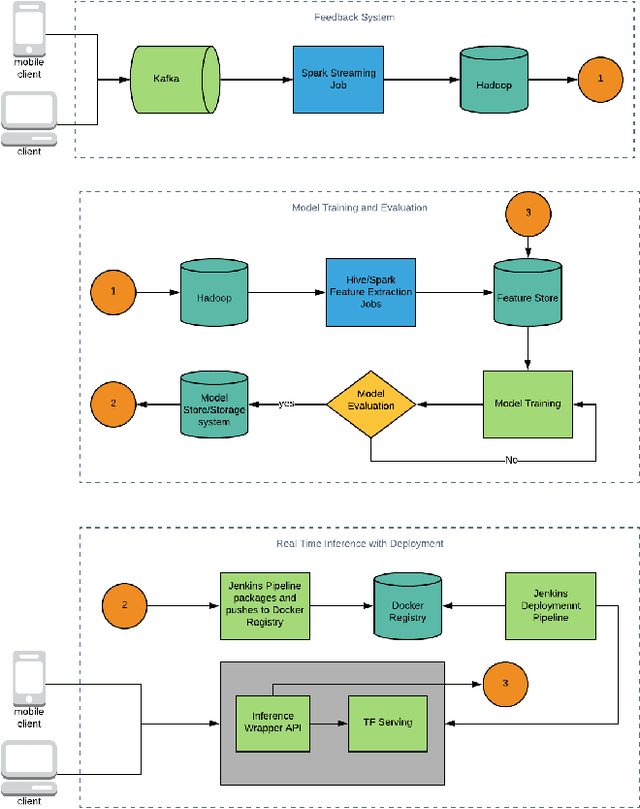
Searching for and making decisions about products is becoming increasingly easier in the e-commerce space, thanks to the evolution of recommender systems. Personalization and recommender systems have gone hand-in-hand to help customers fulfill their shopping needs and improve their experiences in the process. With the growing adoption of conversational platforms for shopping, it has become important to build personalized models at scale to handle the large influx of data and perform inference in real-time. In this work, we present an end-to-end machine learning system for personalized conversational voice commerce. We include components for implicit feedback to the model, model training, evaluation on update, and a real-time inference engine. Our system personalizes voice shopping for Walmart Grocery customers and is currently available via Google Assistant, Siri and Google Home devices.
Transition-Based Dependency Parsing using Perceptron Learner
Jan 28, 2020
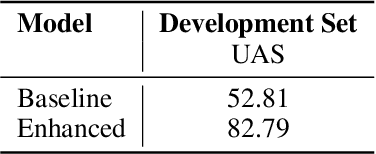
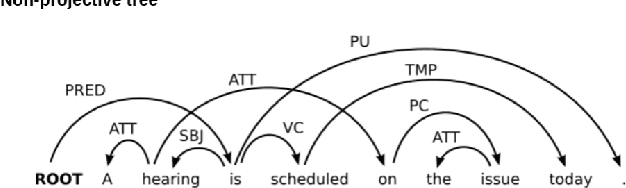
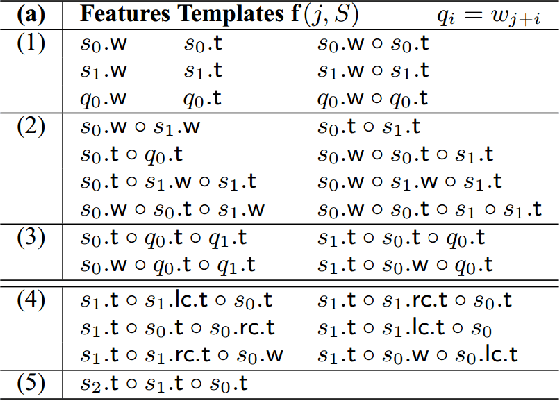
Syntactic parsing using dependency structures has become a standard technique in natural language processing with many different parsing models, in particular data-driven models that can be trained on syntactically annotated corpora. In this paper, we tackle transition-based dependency parsing using a Perceptron Learner. Our proposed model, which adds more relevant features to the Perceptron Learner, outperforms a baseline arc-standard parser. We beat the UAS of the MALT and LSTM parsers. We also give possible ways to address parsing of non-projective trees.
Modeling Product Search Relevance in e-Commerce
Jan 14, 2020
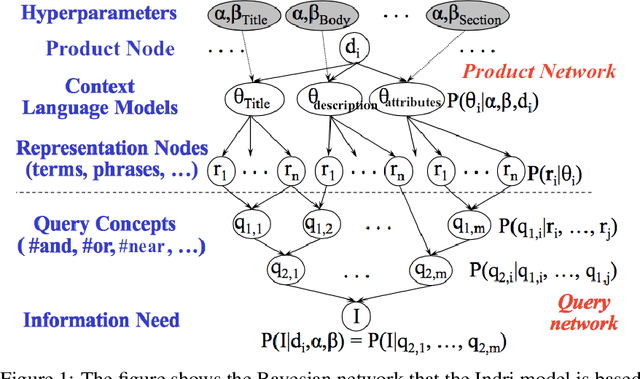

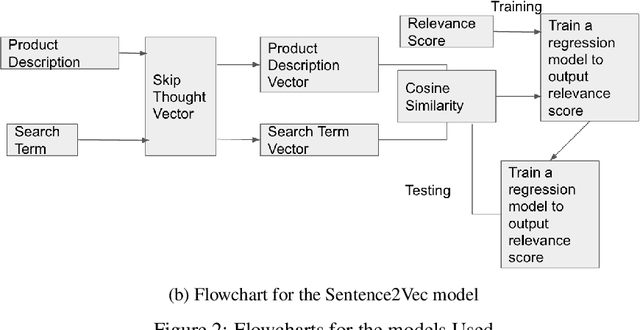
With the rapid growth of e-Commerce, online product search has emerged as a popular and effective paradigm for customers to find desired products and engage in online shopping. However, there is still a big gap between the products that customers really desire to purchase and relevance of products that are suggested in response to a query from the customer. In this paper, we propose a robust way of predicting relevance scores given a search query and a product, using techniques involving machine learning, natural language processing and information retrieval. We compare conventional information retrieval models such as BM25 and Indri with deep learning models such as word2vec, sentence2vec and paragraph2vec. We share some of our insights and findings from our experiments.
A Correspondence Analysis Framework for Author-Conference Recommendations
Jan 08, 2020
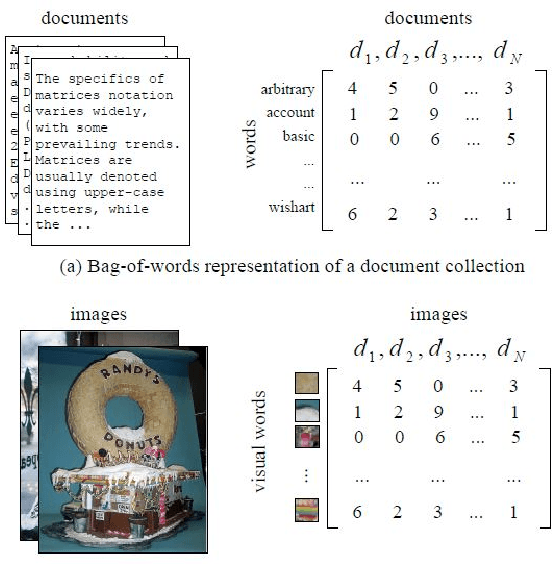
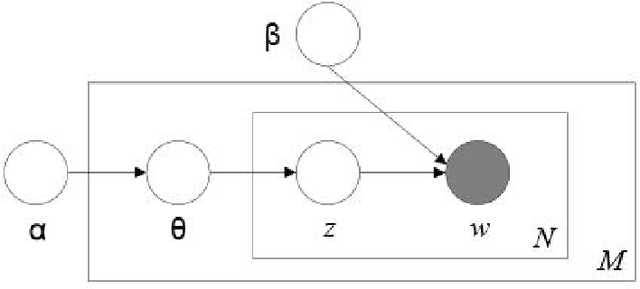
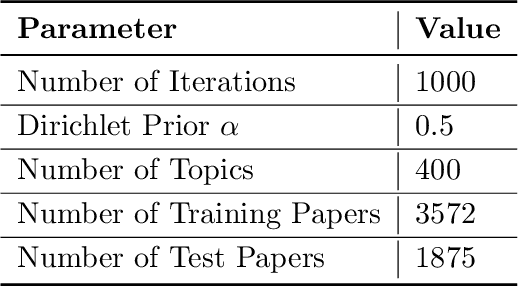
For many years, achievements and discoveries made by scientists are made aware through research papers published in appropriate journals or conferences. Often, established scientists and especially newbies are caught up in the dilemma of choosing an appropriate conference to get their work through. Every scientific conference and journal is inclined towards a particular field of research and there is a vast multitude of them for any particular field. Choosing an appropriate venue is vital as it helps in reaching out to the right audience and also to further one's chance of getting their paper published. In this work, we address the problem of recommending appropriate conferences to the authors to increase their chances of acceptance. We present three different approaches for the same involving the use of social network of the authors and the content of the paper in the settings of dimensionality reduction and topic modeling. In all these approaches, we apply Correspondence Analysis (CA) to derive appropriate relationships between the entities in question, such as conferences and papers. Our models show promising results when compared with existing methods such as content-based filtering, collaborative filtering and hybrid filtering.
Simultaneous Identification of Tweet Purpose and Position
Dec 24, 2019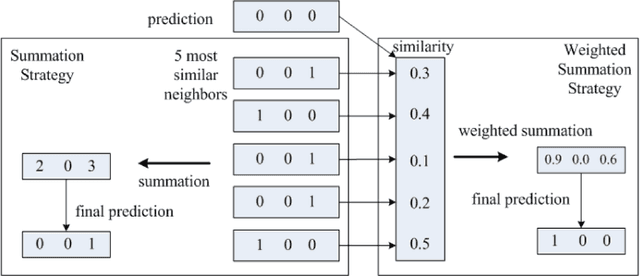


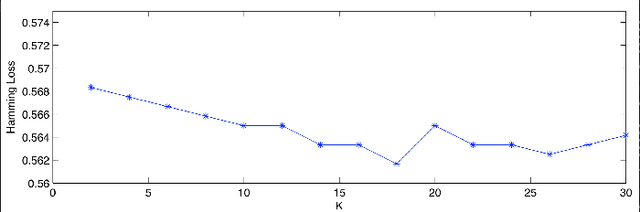
Tweet classification has attracted considerable attention recently. Most of the existing work on tweet classification focuses on topic classification, which classifies tweets into several predefined categories, and sentiment classification, which classifies tweets into positive, negative and neutral. Since tweets are different from conventional text in that they generally are of limited length and contain informal, irregular or new words, so it is difficult to determine user intention to publish a tweet and user attitude towards certain topic. In this paper, we aim to simultaneously classify tweet purpose, i.e., the intention for user to publish a tweet, and position, i.e., supporting, opposing or being neutral to a given topic. By transforming this problem to a multi-label classification problem, a multi-label classification method with post-processing is proposed. Experiments on real-world data sets demonstrate the effectiveness of this method and the results outperform the individual classification methods.
A Machine Learning Framework for Authorship Identification From Texts
Dec 21, 2019
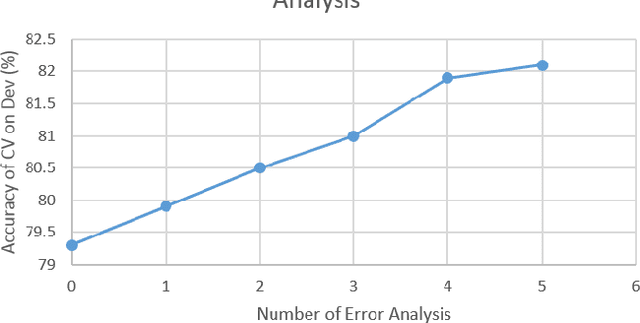
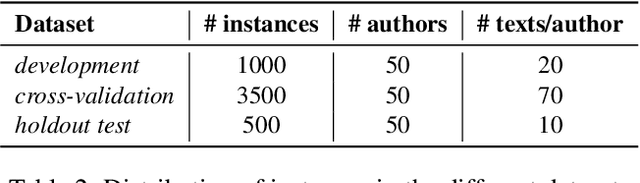
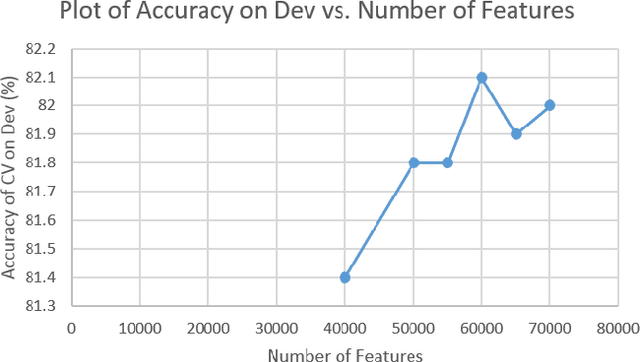
Authorship identification is a process in which the author of a text is identified. Most known literary texts can easily be attributed to a certain author because they are, for example, signed. Yet sometimes we find unfinished pieces of work or a whole bunch of manuscripts with a wide variety of possible authors. In order to assess the importance of such a manuscript, it is vital to know who wrote it. In this work, we aim to develop a machine learning framework to effectively determine authorship. We formulate the task as a single-label multi-class text categorization problem and propose a supervised machine learning framework incorporating stylometric features. This task is highly interdisciplinary in that it takes advantage of machine learning, information retrieval, and natural language processing. We present an approach and a model which learns the differences in writing style between $50$ different authors and is able to predict the author of a new text with high accuracy. The accuracy is seen to increase significantly after introducing certain linguistic stylometric features along with text features.
A Heterogeneous Graphical Model to Understand User-Level Sentiments in Social Media
Dec 17, 2019
Social Media has seen a tremendous growth in the last decade and is continuing to grow at a rapid pace. With such adoption, it is increasingly becoming a rich source of data for opinion mining and sentiment analysis. The detection and analysis of sentiment in social media is thus a valuable topic and attracts a lot of research efforts. Most of the earlier efforts focus on supervised learning approaches to solve this problem, which require expensive human annotations and therefore limits their practical use. In our work, we propose a semi-supervised approach to predict user-level sentiments for specific topics. We define and utilize a heterogeneous graph built from the social networks of the users with the knowledge that connected users in social networks typically share similar sentiments. Compared with the previous works, we have several novelties: (1) we incorporate the influences/authoritativeness of the users into the model, 2) we include comment-based and like-based user-user links to the graph, 3) we superimpose multiple heterogeneous graphs into one thereby allowing multiple types of links to exist between two users.
An Unsupervised Domain-Independent Framework for Automated Detection of Persuasion Tactics in Text
Dec 13, 2019
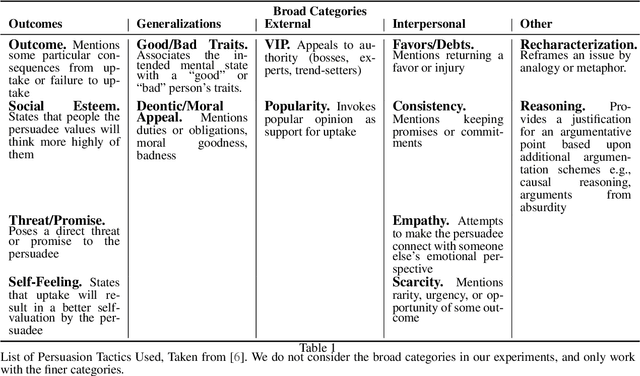


With the increasing growth of social media, people have started relying heavily on the information shared therein to form opinions and make decisions. While such a reliance is motivation for a variety of parties to promote information, it also makes people vulnerable to exploitation by slander, misinformation, terroristic and predatorial advances. In this work, we aim to understand and detect such attempts at persuasion. Existing works on detecting persuasion in text make use of lexical features for detecting persuasive tactics, without taking advantage of the possible structures inherent in the tactics used. We formulate the task as a multi-class classification problem and propose an unsupervised, domain-independent machine learning framework for detecting the type of persuasion used in text, which exploits the inherent sentence structure present in the different persuasion tactics. Our work shows promising results as compared to existing work.
Event Outcome Prediction using Sentiment Analysis and Crowd Wisdom in Microblog Feeds
Dec 11, 2019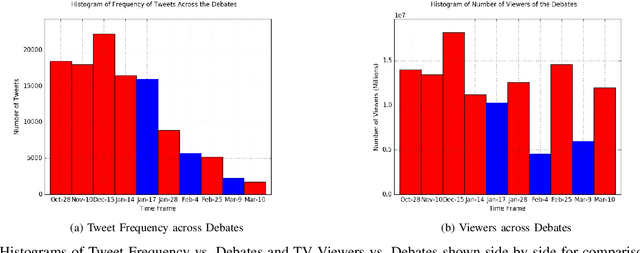
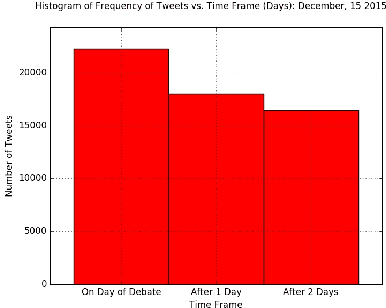
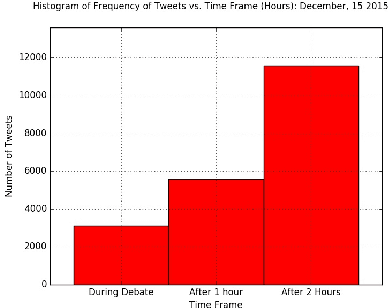
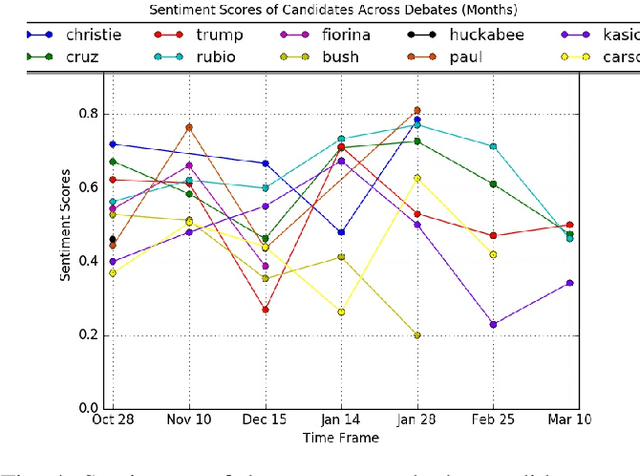
Sentiment Analysis of microblog feeds has attracted considerable interest in recent times. Most of the current work focuses on tweet sentiment classification. But not much work has been done to explore how reliable the opinions of the mass (crowd wisdom) in social network microblogs such as twitter are in predicting outcomes of certain events such as election debates. In this work, we investigate whether crowd wisdom is useful in predicting such outcomes and whether their opinions are influenced by the experts in the field. We work in the domain of multi-label classification to perform sentiment classification of tweets and obtain the opinion of the crowd. This learnt sentiment is then used to predict outcomes of events such as: US Presidential Debate winners, Grammy Award winners, Super Bowl Winners. We find that in most of the cases, the wisdom of the crowd does indeed match with that of the experts, and in cases where they don't (particularly in the case of debates), we see that the crowd's opinion is actually influenced by that of the experts.
Content-based Video Indexing and Retrieval Using Corr-LDA
Feb 27, 2016
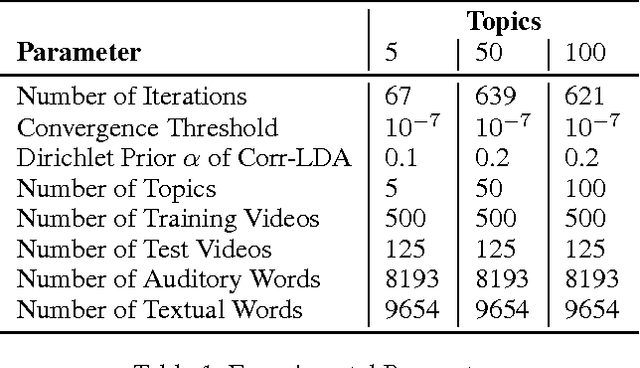
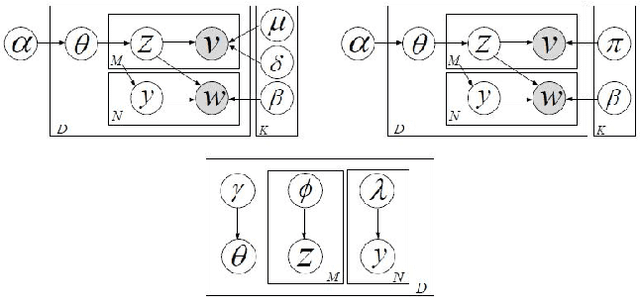

Existing video indexing and retrieval methods on popular web-based multimedia sharing websites are based on user-provided sparse tagging. This paper proposes a very specific way of searching for video clips, based on the content of the video. We present our work on Content-based Video Indexing and Retrieval using the Correspondence-Latent Dirichlet Allocation (corr-LDA) probabilistic framework. This is a model that provides for auto-annotation of videos in a database with textual descriptors, and brings the added benefit of utilizing the semantic relations between the content of the video and text. We use the concept-level matching provided by corr-LDA to build correspondences between text and multimedia, with the objective of retrieving content with increased accuracy. In our experiments, we employ only the audio components of the individual recordings and compare our results with an SVM-based approach.