 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent-based Video Indexing and Retrieval Using Corr-LDA
Feb 27, 2016
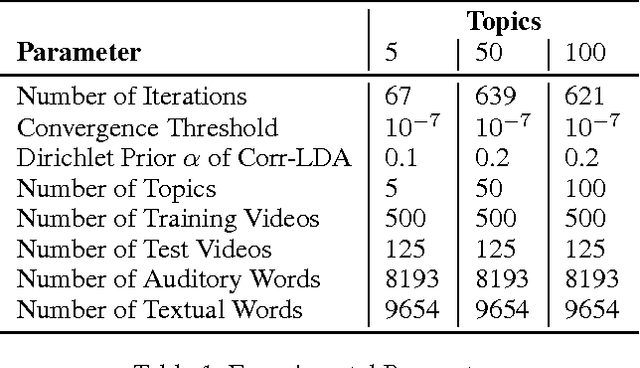
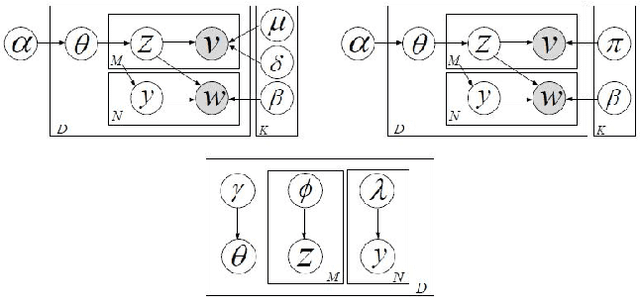

Existing video indexing and retrieval methods on popular web-based multimedia sharing websites are based on user-provided sparse tagging. This paper proposes a very specific way of searching for video clips, based on the content of the video. We present our work on Content-based Video Indexing and Retrieval using the Correspondence-Latent Dirichlet Allocation (corr-LDA) probabilistic framework. This is a model that provides for auto-annotation of videos in a database with textual descriptors, and brings the added benefit of utilizing the semantic relations between the content of the video and text. We use the concept-level matching provided by corr-LDA to build correspondences between text and multimedia, with the objective of retrieving content with increased accuracy. In our experiments, we employ only the audio components of the individual recordings and compare our results with an SVM-based approach.