 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat and When to Learn: CURriculum Ranking Loss for Large-Scale Speaker Verification
Mar 25, 2026Speaker verification at large scale remains an open challenge as fixed-margin losses treat all samples equally regardless of quality. We hypothesize that mislabeled or degraded samples introduce noisy gradients that disrupt compact speaker manifolds. We propose Curry (CURriculum Ranking), an adaptive loss that estimates sample difficulty online via Sub-center ArcFace: confidence scores from dominant sub-center cosine similarity rank samples into easy, medium, and hard tiers using running batch statistics, without auxiliary annotations. Learnable weights guide the model from stable identity foundations through manifold refinement to boundary sharpening. To our knowledge, this is the largest-scale speaker verification system trained to date. Evaluated on VoxCeleb1-O, and SITW, Curry reduces EER by 86.8\% and 60.0\% over the Sub-center ArcFace baseline, establishing a new paradigm for robust speaker verification on imperfect large-scale data.
VerLM: Explaining Face Verification Using Natural Language
Jan 05, 2026Face verification systems have seen substantial advancements; however, they often lack transparency in their decision-making processes. In this paper, we introduce an innovative Vision-Language Model (VLM) for Face Verification, which not only accurately determines if two face images depict the same individual but also explicitly explains the rationale behind its decisions. Our model is uniquely trained using two complementary explanation styles: (1) concise explanations that summarize the key factors influencing its decision, and (2) comprehensive explanations detailing the specific differences observed between the images. We adapt and enhance a state-of-the-art modeling approach originally designed for audio-based differentiation to suit visual inputs effectively. This cross-modal transfer significantly improves our model's accuracy and interpretability. The proposed VLM integrates sophisticated feature extraction techniques with advanced reasoning capabilities, enabling clear articulation of its verification process. Our approach demonstrates superior performance, surpassing baseline methods and existing models. These findings highlight the immense potential of vision language models in face verification set up, contributing to more transparent, reliable, and explainable face verification systems.
OleSpeech-IV: A Large-Scale Multispeaker and Multilingual Conversational Speech Dataset with Diverse Topics
Sep 04, 2025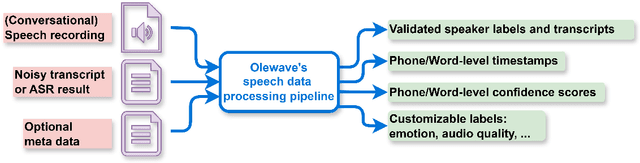
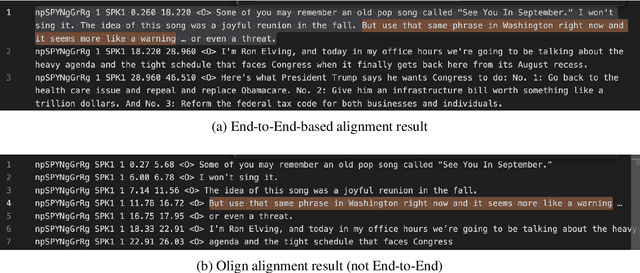
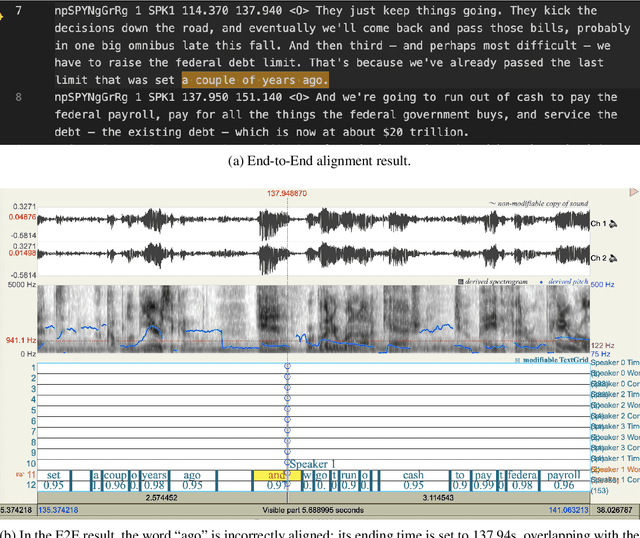
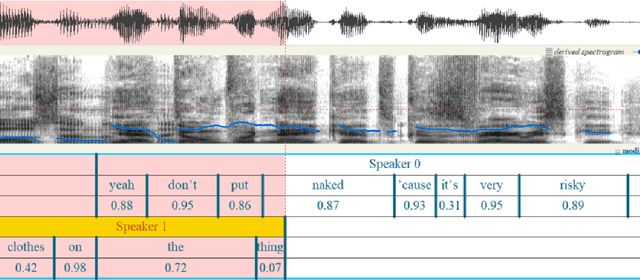
OleSpeech-IV dataset is a large-scale multispeaker and multilingual conversational speech dataset with diverse topics. The audio content comes from publicly-available English podcasts, talk shows, teleconferences, and other conversations. Speaker names, turns, and transcripts are human-sourced and refined by a proprietary pipeline, while additional information such as timestamps and confidence scores is derived from the pipeline. The IV denotes its position as Tier IV in the Olewave dataset series. In addition, we have open-sourced a subset, OleSpeech-IV-2025-EN-AR-100, for non-commercial research use.
Deciphering GunType Hierarchy through Acoustic Analysis of Gunshot Recordings
Jun 25, 2025The escalating rates of gun-related violence and mass shootings represent a significant threat to public safety. Timely and accurate information for law enforcement agencies is crucial in mitigating these incidents. Current commercial gunshot detection systems, while effective, often come with prohibitive costs. This research explores a cost-effective alternative by leveraging acoustic analysis of gunshot recordings, potentially obtainable from ubiquitous devices like cell phones, to not only detect gunshots but also classify the type of firearm used. This paper details a study on deciphering gun type hierarchies using a curated dataset of 3459 recordings. We investigate the fundamental acoustic characteristics of gunshots, including muzzle blasts and shockwaves, which vary based on firearm type, ammunition, and shooting direction. We propose and evaluate machine learning frameworks, including Support Vector Machines (SVMs) as a baseline and a more advanced Convolutional Neural Network (CNN) architecture for joint gunshot detection and gun type classification. Results indicate that our deep learning approach achieves a mean average precision (mAP) of 0.58 on clean labeled data, outperforming the SVM baseline (mAP 0.39). Challenges related to data quality, environmental noise, and the generalization capabilities when using noisy web-sourced data (mAP 0.35) are also discussed. The long-term vision is to develop a highly accurate, real-time system deployable on common recording devices, significantly reducing detection costs and providing critical intelligence to first responders.
CoLMbo: Speaker Language Model for Descriptive Profiling
Jun 11, 2025Speaker recognition systems are often limited to classification tasks and struggle to generate detailed speaker characteristics or provide context-rich descriptions. These models primarily extract embeddings for speaker identification but fail to capture demographic attributes such as dialect, gender, and age in a structured manner. This paper introduces CoLMbo, a Speaker Language Model (SLM) that addresses these limitations by integrating a speaker encoder with prompt-based conditioning. This allows for the creation of detailed captions based on speaker embeddings. CoLMbo utilizes user-defined prompts to adapt dynamically to new speaker characteristics and provides customized descriptions, including regional dialect variations and age-related traits. This innovative approach not only enhances traditional speaker profiling but also excels in zero-shot scenarios across diverse datasets, marking a significant advancement in the field of speaker recognition.
CAARMA: Class Augmentation with Adversarial Mixup Regularization
Mar 20, 2025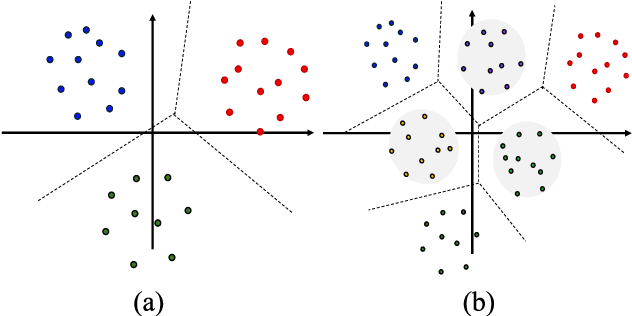
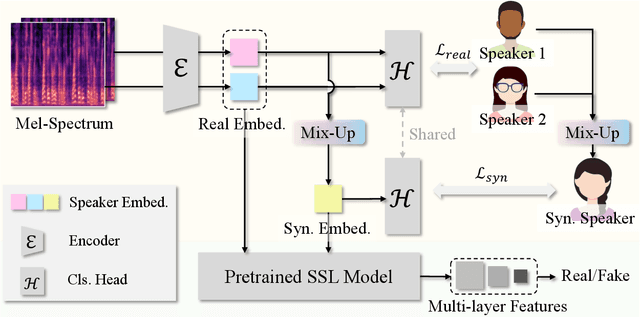
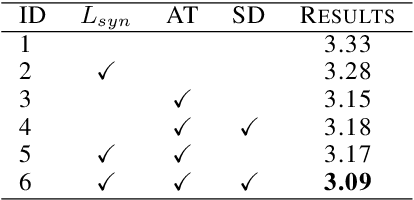
Speaker verification is a typical zero-shot learning task, where inference of unseen classes is performed by comparing embeddings of test instances to known examples. The models performing inference must hence naturally generate embeddings that cluster same-class instances compactly, while maintaining separation across classes. In order to learn to do so, they are typically trained on a large number of classes (speakers), often using specialized losses. However real-world speaker datasets often lack the class diversity needed to effectively learn this in a generalizable manner. We introduce CAARMA, a class augmentation framework that addresses this problem by generating synthetic classes through data mixing in the embedding space, expanding the number of training classes. To ensure the authenticity of the synthetic classes we adopt a novel adversarial refinement mechanism that minimizes categorical distinctions between synthetic and real classes. We evaluate CAARMA on multiple speaker verification tasks, as well as other representative zero-shot comparison-based speech analysis tasks and obtain consistent improvements: our framework demonstrates a significant improvement of 8\% over all baseline models. Code for CAARMA will be released.
A New Benchmark for Few-Shot Class-Incremental Learning: Redefining the Upper Bound
Mar 13, 2025



Class-incremental learning (CIL) aims to continuously adapt to emerging classes while retaining knowledge of previously learned ones. Few-shot class-incremental learning (FSCIL) presents an even greater challenge which requires the model to learn incremental classes with only a limited number of samples. In conventional CIL, joint training is widely considered the upper bound, serving as both a benchmark and a methodological guide. However, we find that joint training fails to be a meaningful upper bound in FSCIL due to the inherent difficulty of inter-task class separation (ICS) caused by severe class imbalance. In this work, we introduce a new joint training benchmark tailored for FSCIL by integrating imbalance-aware techniques, effectively bridging the performance gap between base and incremental classes. Furthermore, we point out inconsistencies in the experimental setup and evaluation of existing FSCIL methods. To ensure fair comparisons between different FSCIL approaches and joint training, we standardize training conditions and propose a unified evaluation protocol that simultaneously considers the validation set and computational complexity. By establishing a reliable upper bound and a standardized evaluation framework for FSCIL, our work provides a clear benchmark and a practical foundation for future research.
Mellow: a small audio language model for reasoning
Mar 11, 2025
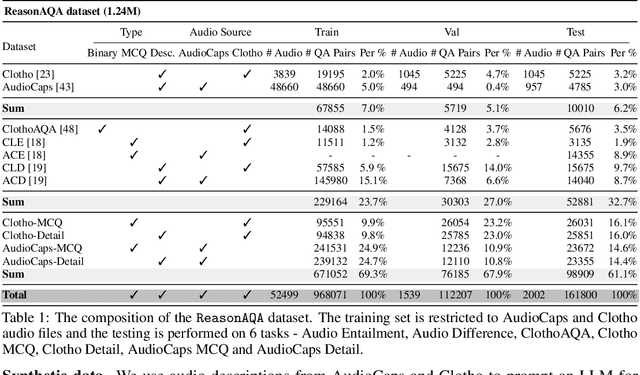
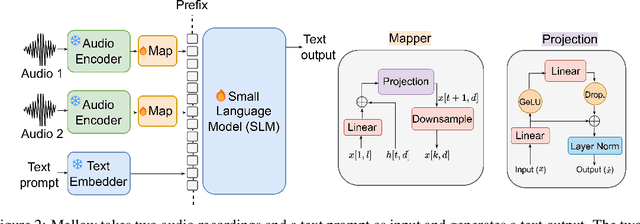
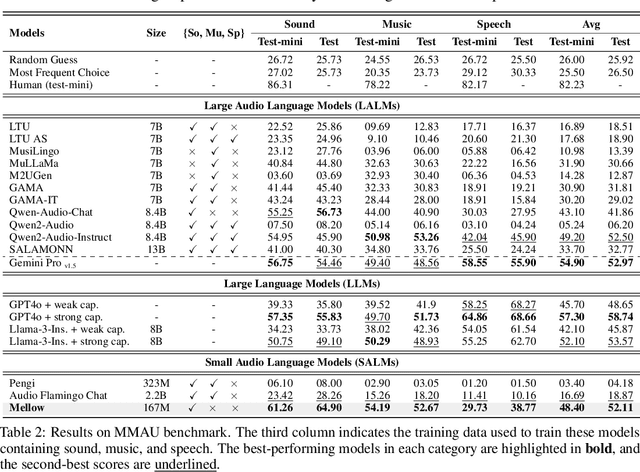
Multimodal Audio-Language Models (ALMs) can understand and reason over both audio and text. Typically, reasoning performance correlates with model size, with the best results achieved by models exceeding 8 billion parameters. However, no prior work has explored enabling small audio-language models to perform reasoning tasks, despite the potential applications for edge devices. To address this gap, we introduce Mellow, a small Audio-Language Model specifically designed for reasoning. Mellow achieves state-of-the-art performance among existing small audio-language models and surpasses several larger models in reasoning capabilities. For instance, Mellow scores 52.11 on MMAU, comparable to SoTA Qwen2 Audio (which scores 52.5) while using 50 times fewer parameters and being trained on 60 times less data (audio hrs). To train Mellow, we introduce ReasonAQA, a dataset designed to enhance audio-grounded reasoning in models. It consists of a mixture of existing datasets (30% of the data) and synthetically generated data (70%). The synthetic dataset is derived from audio captioning datasets, where Large Language Models (LLMs) generate detailed and multiple-choice questions focusing on audio events, objects, acoustic scenes, signal properties, semantics, and listener emotions. To evaluate Mellow's reasoning ability, we benchmark it on a diverse set of tasks, assessing on both in-distribution and out-of-distribution data, including audio understanding, deductive reasoning, and comparative reasoning. Finally, we conduct extensive ablation studies to explore the impact of projection layer choices, synthetic data generation methods, and language model pretraining on reasoning performance. Our training dataset, findings, and baseline pave the way for developing small ALMs capable of reasoning.
Lost in Transcription, Found in Distribution Shift: Demystifying Hallucination in Speech Foundation Models
Feb 18, 2025

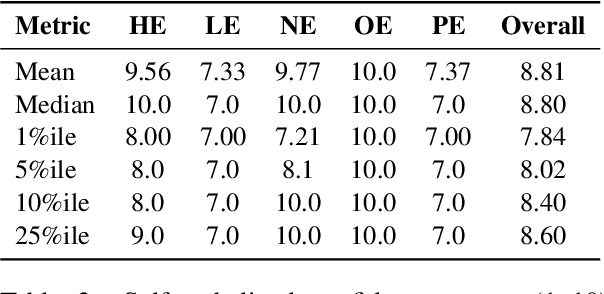
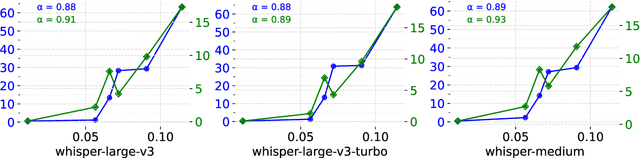
Speech foundation models trained at a massive scale, both in terms of model and data size, result in robust systems capable of performing multiple speech tasks, including automatic speech recognition (ASR). These models transcend language and domain barriers, yet effectively measuring their performance remains a challenge. Traditional metrics like word error rate (WER) and character error rate (CER) are commonly used to evaluate ASR performance but often fail to reflect transcription quality in critical contexts, particularly when detecting fabricated outputs. This phenomenon, known as hallucination, is especially concerning in high-stakes domains such as healthcare, legal, and aviation, where errors can have severe consequences. In our work, we address this gap by investigating hallucination in ASR models. We examine how factors such as distribution shifts, model size, and model architecture influence the hallucination error rate (HER), a metric we introduce to quantify hallucinations. Our analysis of 20 ASR models reveals \numinsights~key insights: (1) High WERs can mask low hallucination rates, while low WERs may conceal dangerous hallucinations. (2) Synthetic noise, both adversarial and common perturbations like white noise, pitch shift, and time stretching, increase HER. (3) Distribution shift correlates strongly with HER ($\alpha = 0.91$). Our findings highlight the importance of incorporating HER alongside traditional metrics like WER to better assess ASR model performance, particularly in high-stakes domains.
On the Robust Approximation of ASR Metrics
Feb 18, 2025



Recent advances in speech foundation models are largely driven by scaling both model size and data, enabling them to perform a wide range of tasks, including speech recognition. Traditionally, ASR models are evaluated using metrics like Word Error Rate (WER) and Character Error Rate (CER), which depend on ground truth labels. As a result of limited labeled data from diverse domains and testing conditions, the true generalization capabilities of these models beyond standard benchmarks remain unclear. Moreover, labeling data is both costly and time-consuming. To address this, we propose a novel label-free approach for approximating ASR performance metrics, eliminating the need for ground truth labels. Our method utilizes multimodal embeddings in a unified space for speech and transcription representations, combined with a high-quality proxy model to compute proxy metrics. These features are used to train a regression model to predict key ASR metrics like Word Error Rate (WER) and Character Error Rate (CER). We experiment with over 40 models across 14 datasets representing both standard and in-the-wild testing conditions. Our results show that we approximate the metrics within a single-digit absolute difference across all experimental configurations, outperforming the most recent baseline by more than 50\%.