 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIVET: Robust Idempotent Voice Attribute Editing
Jun 17, 2026Voice attribute editing models modify characteristics such as age and gender while preserving speaker identity. In large-scale speech datasets, however, attribute annotations are often noisy or inconsistent, which can cause conditional generative models to produce unstable edits. In this work, we show that idempotency provides an effective mechanism for improving robustness to noisy labels. An idempotent operator is one for which repeated application does not change the result, i.e., f(f(x)) = f(x). Enforcing this property acts as an implicit regularizer that reduces sensitivity to mislabeled examples. We introduce RIVET, a training framework that incorporates an idempotency objective to improve robustness to label noise. We evaluate RIVET under controlled label noise and on the GLOBE dataset with naturally noisy annotations. RIVET improves editing success and better preserves speaker identity than standard training, showing that idempotency improves robustness in voice editing models.
Tessellated Linear Model for Age Prediction from Voice
Jan 16, 2025



Voice biometric tasks, such as age estimation require modeling the often complex relationship between voice features and the biometric variable. While deep learning models can handle such complexity, they typically require large amounts of accurately labeled data to perform well. Such data are often scarce for biometric tasks such as voice-based age prediction. On the other hand, simpler models like linear regression can work with smaller datasets but often fail to generalize to the underlying non-linear patterns present in the data. In this paper we propose the Tessellated Linear Model (TLM), a piecewise linear approach that combines the simplicity of linear models with the capacity of non-linear functions. TLM tessellates the feature space into convex regions and fits a linear model within each region. We optimize the tessellation and the linear models using a hierarchical greedy partitioning. We evaluated TLM on the TIMIT dataset on the task of age prediction from voice, where it outperformed state-of-the-art deep learning models.
PAM: Prompting Audio-Language Models for Audio Quality Assessment
Feb 01, 2024



While audio quality is a key performance metric for various audio processing tasks, including generative modeling, its objective measurement remains a challenge. Audio-Language Models (ALMs) are pre-trained on audio-text pairs that may contain information about audio quality, the presence of artifacts, or noise. Given an audio input and a text prompt related to quality, an ALM can be used to calculate a similarity score between the two. Here, we exploit this capability and introduce PAM, a no-reference metric for assessing audio quality for different audio processing tasks. Contrary to other "reference-free" metrics, PAM does not require computing embeddings on a reference dataset nor training a task-specific model on a costly set of human listening scores. We extensively evaluate the reliability of PAM against established metrics and human listening scores on four tasks: text-to-audio (TTA), text-to-music generation (TTM), text-to-speech (TTS), and deep noise suppression (DNS). We perform multiple ablation studies with controlled distortions, in-the-wild setups, and prompt choices. Our evaluation shows that PAM correlates well with existing metrics and human listening scores. These results demonstrate the potential of ALMs for computing a general-purpose audio quality metric.
LoFT: Local Proxy Fine-tuning For Improving Transferability Of Adversarial Attacks Against Large Language Model
Oct 02, 2023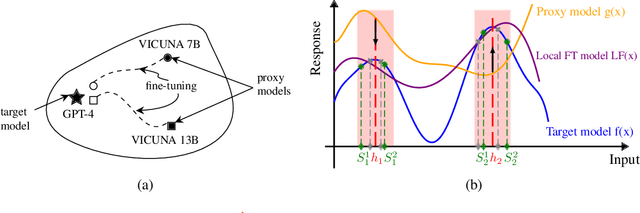

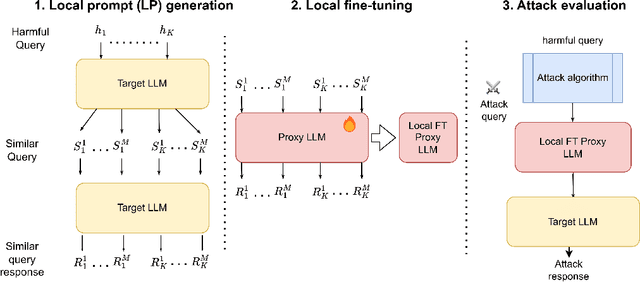

It has been shown that Large Language Model (LLM) alignments can be circumvented by appending specially crafted attack suffixes with harmful queries to elicit harmful responses. To conduct attacks against private target models whose characterization is unknown, public models can be used as proxies to fashion the attack, with successful attacks being transferred from public proxies to private target models. The success rate of attack depends on how closely the proxy model approximates the private model. We hypothesize that for attacks to be transferrable, it is sufficient if the proxy can approximate the target model in the neighborhood of the harmful query. Therefore, in this paper, we propose \emph{Local Fine-Tuning (LoFT)}, \textit{i.e.}, fine-tuning proxy models on similar queries that lie in the lexico-semantic neighborhood of harmful queries to decrease the divergence between the proxy and target models. First, we demonstrate three approaches to prompt private target models to obtain similar queries given harmful queries. Next, we obtain data for local fine-tuning by eliciting responses from target models for the generated similar queries. Then, we optimize attack suffixes to generate attack prompts and evaluate the impact of our local fine-tuning on the attack's success rate. Experiments show that local fine-tuning of proxy models improves attack transferability and increases attack success rate by $39\%$, $7\%$, and $0.5\%$ (absolute) on target models ChatGPT, GPT-4, and Claude respectively.
Evaluating Speech Synthesis by Training Recognizers on Synthetic Speech
Oct 01, 2023Modern speech synthesis systems have improved significantly, with synthetic speech being indistinguishable from real speech. However, efficient and holistic evaluation of synthetic speech still remains a significant challenge. Human evaluation using Mean Opinion Score (MOS) is ideal, but inefficient due to high costs. Therefore, researchers have developed auxiliary automatic metrics like Word Error Rate (WER) to measure intelligibility. Prior works focus on evaluating synthetic speech based on pre-trained speech recognition models, however, this can be limiting since this approach primarily measures speech intelligibility. In this paper, we propose an evaluation technique involving the training of an ASR model on synthetic speech and assessing its performance on real speech. Our main assumption is that by training the ASR model on the synthetic speech, the WER on real speech reflects the similarity between distributions, a broader assessment of synthetic speech quality beyond intelligibility. Our proposed metric demonstrates a strong correlation with both MOS naturalness and MOS intelligibility when compared to SpeechLMScore and MOSNet on three recent Text-to-Speech (TTS) systems: MQTTS, StyleTTS, and YourTTS.