 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchema Augmentation for Zero-Shot Domain Adaptation in Dialogue State Tracking
Oct 31, 2024
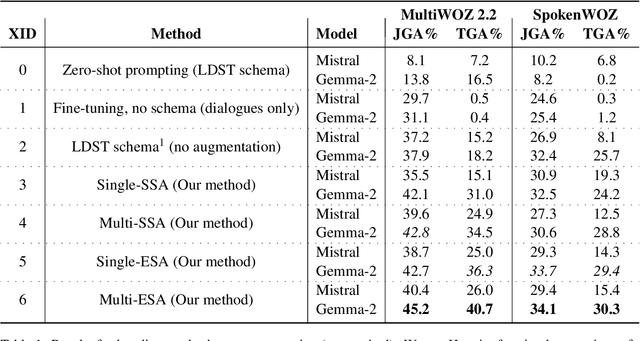
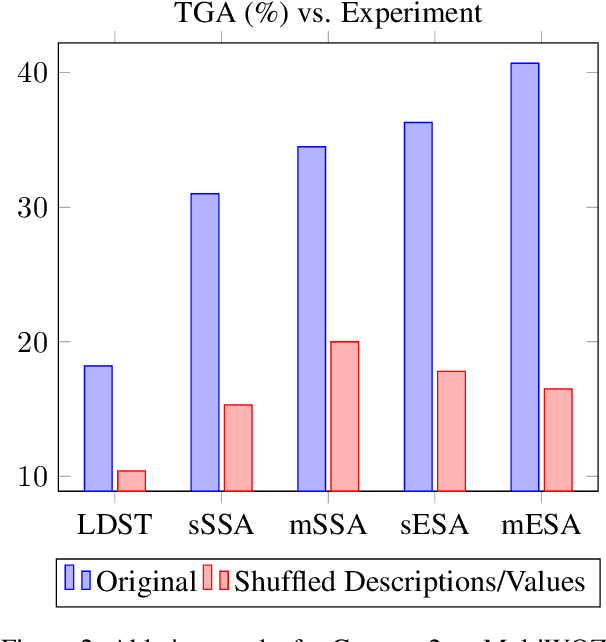
Zero-shot domain adaptation for dialogue state tracking (DST) remains a challenging problem in task-oriented dialogue (TOD) systems, where models must generalize to target domains unseen at training time. Current large language model approaches for zero-shot domain adaptation rely on prompting to introduce knowledge pertaining to the target domains. However, their efficacy strongly depends on prompt engineering, as well as the zero-shot ability of the underlying language model. In this work, we devise a novel data augmentation approach, Schema Augmentation, that improves the zero-shot domain adaptation of language models through fine-tuning. Schema Augmentation is a simple but effective technique that enhances generalization by introducing variations of slot names within the schema provided in the prompt. Experiments on MultiWOZ and SpokenWOZ showed that the proposed approach resulted in a substantial improvement over the baseline, in some experiments achieving over a twofold accuracy gain over unseen domains while maintaining equal or superior performance over all domains.
Speech vs. Transcript: Does It Matter for Human Annotators in Speech Summarization?
Aug 12, 2024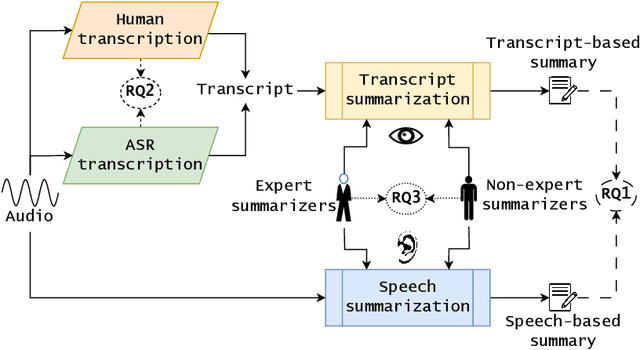
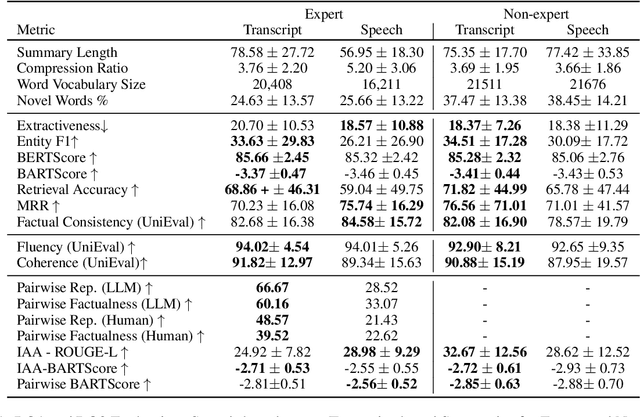

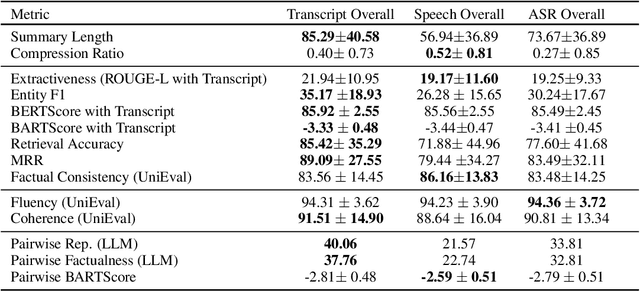
Reference summaries for abstractive speech summarization require human annotation, which can be performed by listening to an audio recording or by reading textual transcripts of the recording. In this paper, we examine whether summaries based on annotators listening to the recordings differ from those based on annotators reading transcripts. Using existing intrinsic evaluation based on human evaluation, automatic metrics, LLM-based evaluation, and a retrieval-based reference-free method. We find that summaries are indeed different based on the source modality, and that speech-based summaries are more factually consistent and information-selective than transcript-based summaries. Meanwhile, transcript-based summaries are impacted by recognition errors in the source, and expert-written summaries are more informative and reliable. We make all the collected data and analysis code public(https://github.com/cmu-mlsp/interview_humanssum) to facilitate the reproduction of our work and advance research in this area.
On the Evaluation of Speech Foundation Models for Spoken Language Understanding
Jun 14, 2024The Spoken Language Understanding Evaluation (SLUE) suite of benchmark tasks was recently introduced to address the need for open resources and benchmarking of complex spoken language understanding (SLU) tasks, including both classification and sequence generation tasks, on natural speech. The benchmark has demonstrated preliminary success in using pre-trained speech foundation models (SFM) for these SLU tasks. However, the community still lacks a fine-grained understanding of the comparative utility of different SFMs. Inspired by this, we ask: which SFMs offer the most benefits for these complex SLU tasks, and what is the most effective approach for incorporating these SFMs? To answer this, we perform an extensive evaluation of multiple supervised and self-supervised SFMs using several evaluation protocols: (i) frozen SFMs with a lightweight prediction head, (ii) frozen SFMs with a complex prediction head, and (iii) fine-tuned SFMs with a lightweight prediction head. Although the supervised SFMs are pre-trained on much more speech recognition data (with labels), they do not always outperform self-supervised SFMs; the latter tend to perform at least as well as, and sometimes better than, supervised SFMs, especially on the sequence generation tasks in SLUE. While there is no universally optimal way of incorporating SFMs, the complex prediction head gives the best performance for most tasks, although it increases the inference time. We also introduce an open-source toolkit and performance leaderboard, SLUE-PERB, for these tasks and modeling strategies.
AugSumm: towards generalizable speech summarization using synthetic labels from large language model
Jan 10, 2024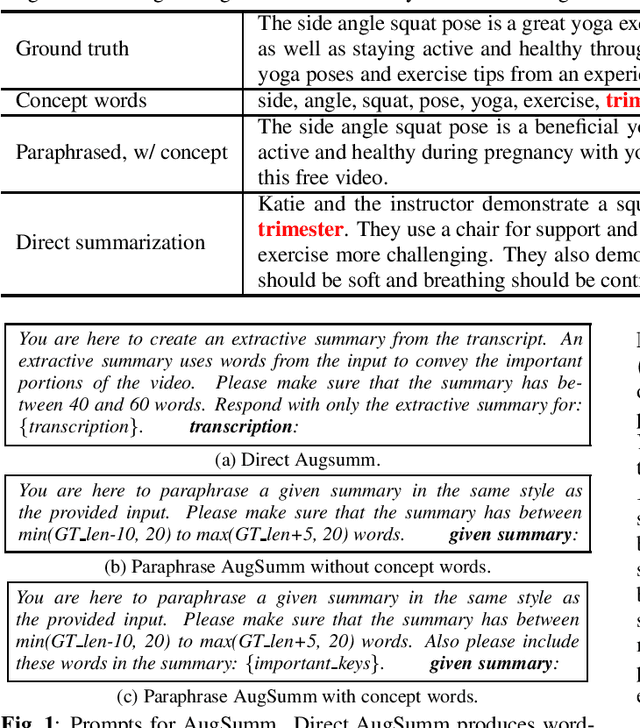


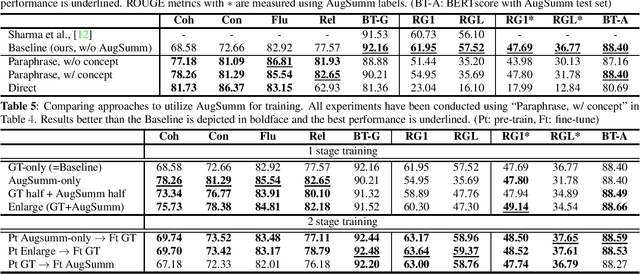
Abstractive speech summarization (SSUM) aims to generate human-like summaries from speech. Given variations in information captured and phrasing, recordings can be summarized in multiple ways. Therefore, it is more reasonable to consider a probabilistic distribution of all potential summaries rather than a single summary. However, conventional SSUM models are mostly trained and evaluated with a single ground-truth (GT) human-annotated deterministic summary for every recording. Generating multiple human references would be ideal to better represent the distribution statistically, but is impractical because annotation is expensive. We tackle this challenge by proposing AugSumm, a method to leverage large language models (LLMs) as a proxy for human annotators to generate augmented summaries for training and evaluation. First, we explore prompting strategies to generate synthetic summaries from ChatGPT. We validate the quality of synthetic summaries using multiple metrics including human evaluation, where we find that summaries generated using AugSumm are perceived as more valid to humans. Second, we develop methods to utilize synthetic summaries in training and evaluation. Experiments on How2 demonstrate that pre-training on synthetic summaries and fine-tuning on GT summaries improves ROUGE-L by 1 point on both GT and AugSumm-based test sets. AugSumm summaries are available at https://github.com/Jungjee/AugSumm.
UniverSLU: Universal Spoken Language Understanding for Diverse Classification and Sequence Generation Tasks with a Single Network
Oct 04, 2023
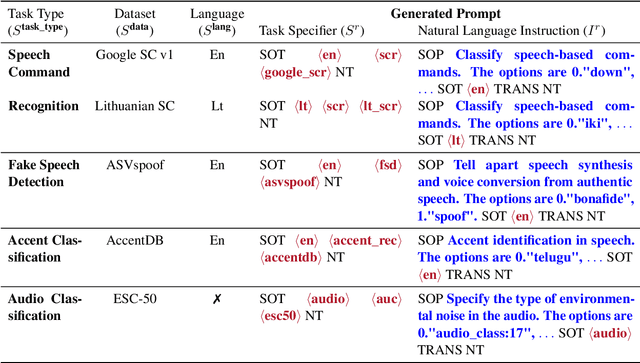
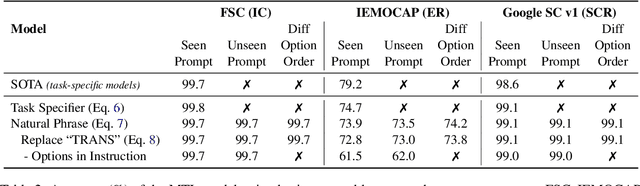
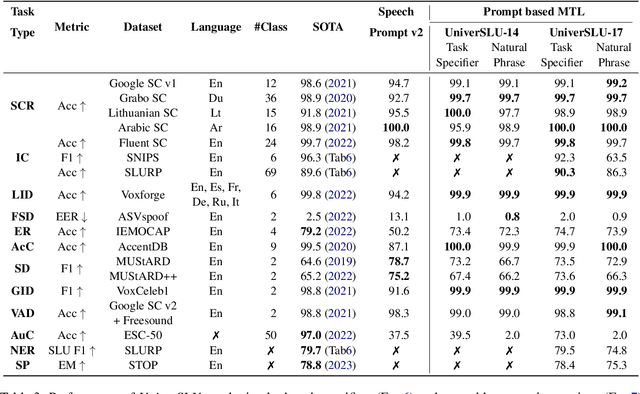
Recent studies have demonstrated promising outcomes by employing large language models with multi-tasking capabilities. They utilize prompts to guide the model's behavior and surpass performance of task-specific models. Motivated by this, we ask: can we build a single model that jointly perform various spoken language understanding (SLU) tasks? To address this, we utilize pre-trained automatic speech recognition (ASR) models and employ various task and dataset specifiers as discrete prompts. We demonstrate efficacy of our single multi-task learning (MTL) model "UniverSLU" for 12 different speech classification and sequence generation tasks across 17 datasets and 9 languages. Results show that UniverSLU achieves competitive performance and even surpasses task-specific models. We also conduct preliminary investigations into enabling human-interpretable natural phrases instead of task specifiers as discrete prompts and test the model's generalization capabilities to new paraphrases.
Reproducing Whisper-Style Training Using an Open-Source Toolkit and Publicly Available Data
Oct 02, 2023Pre-training speech models on large volumes of data has achieved remarkable success. OpenAI Whisper is a multilingual multitask model trained on 680k hours of supervised speech data. It generalizes well to various speech recognition and translation benchmarks even in a zero-shot setup. However, the full pipeline for developing such models (from data collection to training) is not publicly accessible, which makes it difficult for researchers to further improve its performance and address training-related issues such as efficiency, robustness, fairness, and bias. This work presents an Open Whisper-style Speech Model (OWSM), which reproduces Whisper-style training using an open-source toolkit and publicly available data. OWSM even supports more translation directions and can be more efficient to train. We will publicly release all scripts used for data preparation, training, inference, and scoring as well as pre-trained models and training logs to promote open science.
LoFT: Local Proxy Fine-tuning For Improving Transferability Of Adversarial Attacks Against Large Language Model
Oct 02, 2023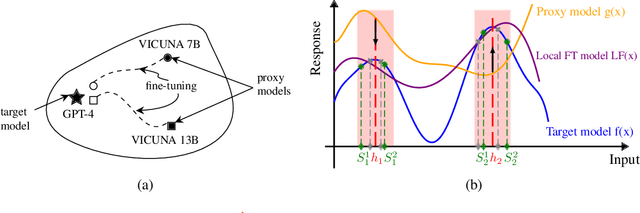

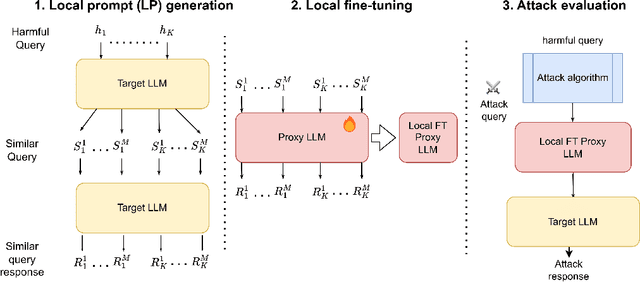

It has been shown that Large Language Model (LLM) alignments can be circumvented by appending specially crafted attack suffixes with harmful queries to elicit harmful responses. To conduct attacks against private target models whose characterization is unknown, public models can be used as proxies to fashion the attack, with successful attacks being transferred from public proxies to private target models. The success rate of attack depends on how closely the proxy model approximates the private model. We hypothesize that for attacks to be transferrable, it is sufficient if the proxy can approximate the target model in the neighborhood of the harmful query. Therefore, in this paper, we propose \emph{Local Fine-Tuning (LoFT)}, \textit{i.e.}, fine-tuning proxy models on similar queries that lie in the lexico-semantic neighborhood of harmful queries to decrease the divergence between the proxy and target models. First, we demonstrate three approaches to prompt private target models to obtain similar queries given harmful queries. Next, we obtain data for local fine-tuning by eliciting responses from target models for the generated similar queries. Then, we optimize attack suffixes to generate attack prompts and evaluate the impact of our local fine-tuning on the attack's success rate. Experiments show that local fine-tuning of proxy models improves attack transferability and increases attack success rate by $39\%$, $7\%$, and $0.5\%$ (absolute) on target models ChatGPT, GPT-4, and Claude respectively.
Evaluating Speech Synthesis by Training Recognizers on Synthetic Speech
Oct 01, 2023Modern speech synthesis systems have improved significantly, with synthetic speech being indistinguishable from real speech. However, efficient and holistic evaluation of synthetic speech still remains a significant challenge. Human evaluation using Mean Opinion Score (MOS) is ideal, but inefficient due to high costs. Therefore, researchers have developed auxiliary automatic metrics like Word Error Rate (WER) to measure intelligibility. Prior works focus on evaluating synthetic speech based on pre-trained speech recognition models, however, this can be limiting since this approach primarily measures speech intelligibility. In this paper, we propose an evaluation technique involving the training of an ASR model on synthetic speech and assessing its performance on real speech. Our main assumption is that by training the ASR model on the synthetic speech, the WER on real speech reflects the similarity between distributions, a broader assessment of synthetic speech quality beyond intelligibility. Our proposed metric demonstrates a strong correlation with both MOS naturalness and MOS intelligibility when compared to SpeechLMScore and MOSNet on three recent Text-to-Speech (TTS) systems: MQTTS, StyleTTS, and YourTTS.
Exploring Speech Recognition, Translation, and Understanding with Discrete Speech Units: A Comparative Study
Sep 27, 2023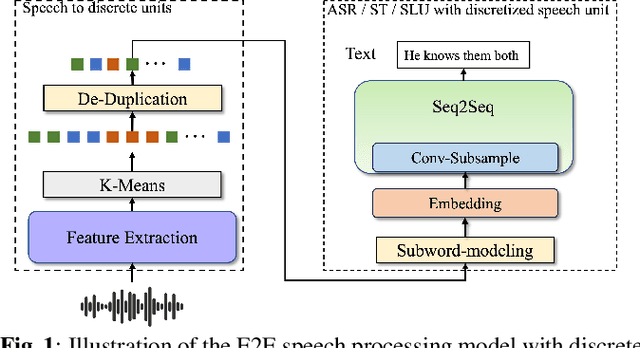
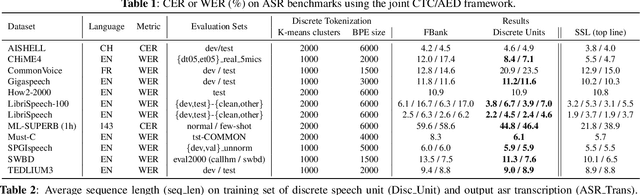
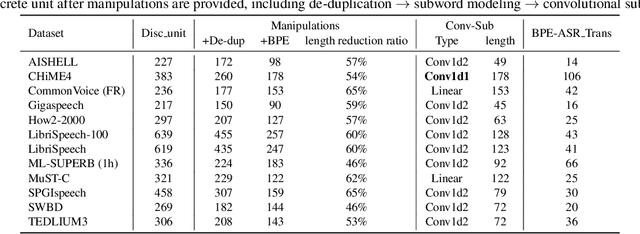
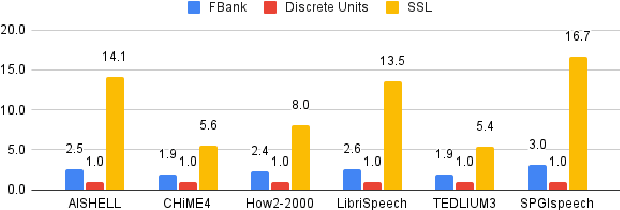
Speech signals, typically sampled at rates in the tens of thousands per second, contain redundancies, evoking inefficiencies in sequence modeling. High-dimensional speech features such as spectrograms are often used as the input for the subsequent model. However, they can still be redundant. Recent investigations proposed the use of discrete speech units derived from self-supervised learning representations, which significantly compresses the size of speech data. Applying various methods, such as de-duplication and subword modeling, can further compress the speech sequence length. Hence, training time is significantly reduced while retaining notable performance. In this study, we undertake a comprehensive and systematic exploration into the application of discrete units within end-to-end speech processing models. Experiments on 12 automatic speech recognition, 3 speech translation, and 1 spoken language understanding corpora demonstrate that discrete units achieve reasonably good results in almost all the settings. We intend to release our configurations and trained models to foster future research efforts.
Dynamic-SUPERB: Towards A Dynamic, Collaborative, and Comprehensive Instruction-Tuning Benchmark for Speech
Sep 18, 2023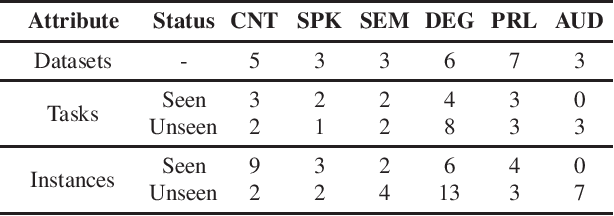
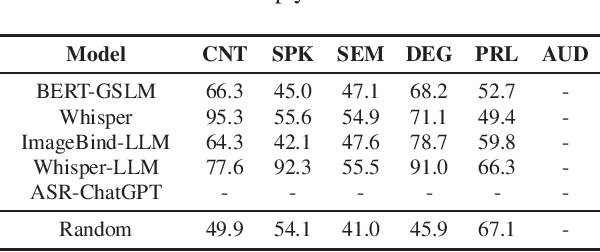
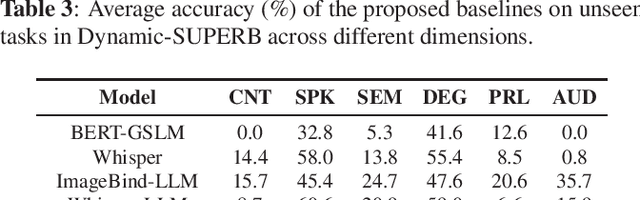
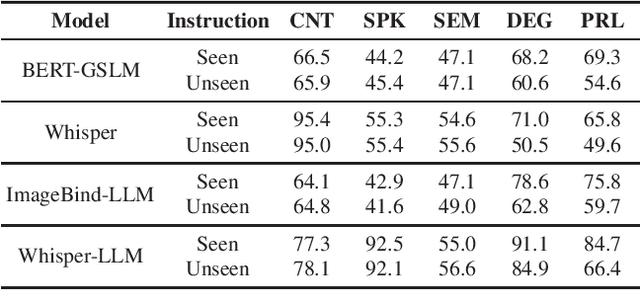
Text language models have shown remarkable zero-shot capability in generalizing to unseen tasks when provided with well-formulated instructions. However, existing studies in speech processing primarily focus on limited or specific tasks. Moreover, the lack of standardized benchmarks hinders a fair comparison across different approaches. Thus, we present Dynamic-SUPERB, a benchmark designed for building universal speech models capable of leveraging instruction tuning to perform multiple tasks in a zero-shot fashion. To achieve comprehensive coverage of diverse speech tasks and harness instruction tuning, we invite the community to collaborate and contribute, facilitating the dynamic growth of the benchmark. To initiate, Dynamic-SUPERB features 55 evaluation instances by combining 33 tasks and 22 datasets. This spans a broad spectrum of dimensions, providing a comprehensive platform for evaluation. Additionally, we propose several approaches to establish benchmark baselines. These include the utilization of speech models, text language models, and the multimodal encoder. Evaluation results indicate that while these baselines perform reasonably on seen tasks, they struggle with unseen ones. We also conducted an ablation study to assess the robustness and seek improvements in the performance. We release all materials to the public and welcome researchers to collaborate on the project, advancing technologies in the field together.