 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Neural Codecs Generalize? A Controlled Study Across Unseen Languages and Non-Speech Tasks
Jan 18, 2026This paper investigates three crucial yet underexplored aspects of the generalization capabilities of neural audio codecs (NACs): (i) whether NACs can generalize to unseen languages during pre-training, (ii) whether speech-only pre-trained NACs can effectively generalize to non-speech applications such as environmental sounds, music, and animal vocalizations, and (iii) whether incorporating non-speech data during pre-training can improve performance on both speech and non-speech tasks. Existing studies typically rely on off-the-shelf NACs for comparison, which limits insight due to variations in implementation. In this work, we train NACs from scratch using strictly controlled configurations and carefully curated pre-training data to enable fair comparisons. We conduct a comprehensive evaluation of NAC performance on both signal reconstruction quality and downstream applications using 11 metrics. Our results show that NACs can generalize to unseen languages during pre-training, speech-only pre-trained NACs exhibit degraded performance on non-speech tasks, and incorporating non-speech data during pre-training improves performance on non-speech tasks while maintaining comparable performance on speech tasks.
The ML-SUPERB 2.0 Challenge: Towards Inclusive ASR Benchmarking for All Language Varieties
Sep 08, 2025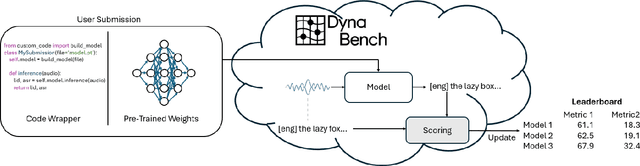
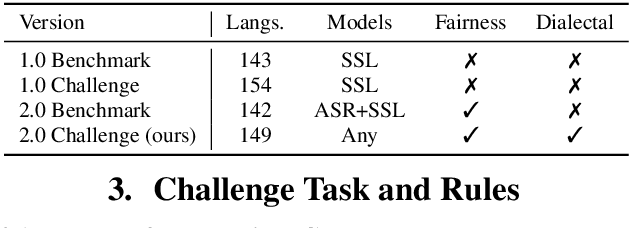
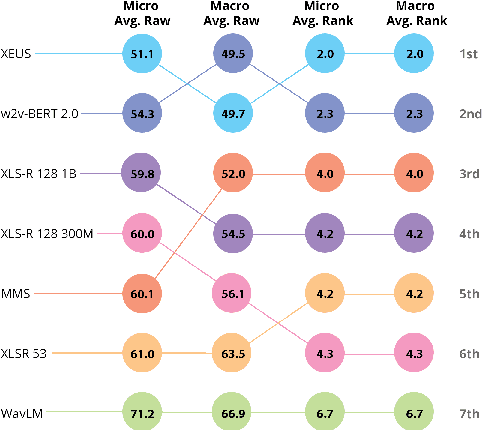
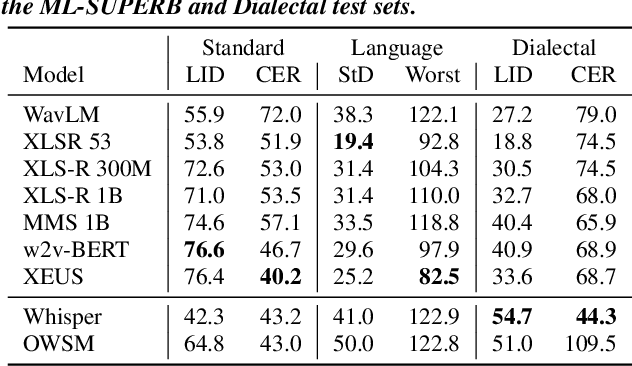
Recent improvements in multilingual ASR have not been equally distributed across languages and language varieties. To advance state-of-the-art (SOTA) ASR models, we present the Interspeech 2025 ML-SUPERB 2.0 Challenge. We construct a new test suite that consists of data from 200+ languages, accents, and dialects to evaluate SOTA multilingual speech models. The challenge also introduces an online evaluation server based on DynaBench, allowing for flexibility in model design and architecture for participants. The challenge received 5 submissions from 3 teams, all of which outperformed our baselines. The best-performing submission achieved an absolute improvement in LID accuracy of 23% and a reduction in CER of 18% when compared to the best baseline on a general multilingual test set. On accented and dialectal data, the best submission obtained 30.2% lower CER and 15.7% higher LID accuracy, showing the importance of community challenges in making speech technologies more inclusive.
How to Learn a New Language? An Efficient Solution for Self-Supervised Learning Models Unseen Languages Adaption in Low-Resource Scenario
Nov 27, 2024



The utilization of speech Self-Supervised Learning (SSL) models achieves impressive performance on Automatic Speech Recognition (ASR). However, in low-resource language ASR, they encounter the domain mismatch problem between pre-trained and low-resource languages. Typical solutions like fine-tuning the SSL model suffer from high computation costs while using frozen SSL models as feature extractors comes with poor performance. To handle these issues, we extend a conventional efficient fine-tuning scheme based on the adapter. We add an extra intermediate adaptation to warm up the adapter and downstream model initialization. Remarkably, we update only 1-5% of the total model parameters to achieve the adaptation. Experimental results on the ML-SUPERB dataset show that our solution outperforms conventional efficient fine-tuning. It achieves up to a 28% relative improvement in the Character/Phoneme error rate when adapting to unseen languages.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
ML-SUPERB 2.0: Benchmarking Multilingual Speech Models Across Modeling Constraints, Languages, and Datasets
Jun 12, 2024



ML-SUPERB evaluates self-supervised learning (SSL) models on the tasks of language identification and automatic speech recognition (ASR). This benchmark treats the models as feature extractors and uses a single shallow downstream model, which can be fine-tuned for a downstream task. However, real-world use cases may require different configurations. This paper presents ML-SUPERB~2.0, which is a new benchmark for evaluating pre-trained SSL and supervised speech models across downstream models, fine-tuning setups, and efficient model adaptation approaches. We find performance improvements over the setup of ML-SUPERB. However, performance depends on the downstream model design. Also, we find large performance differences between languages and datasets, suggesting the need for more targeted approaches to improve multilingual ASR performance.
Dynamic-SUPERB: Towards A Dynamic, Collaborative, and Comprehensive Instruction-Tuning Benchmark for Speech
Sep 18, 2023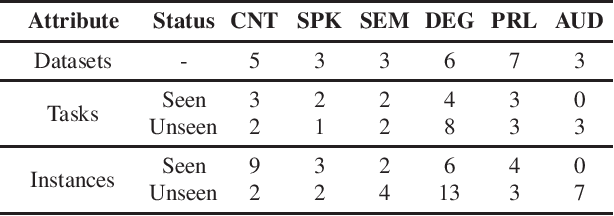
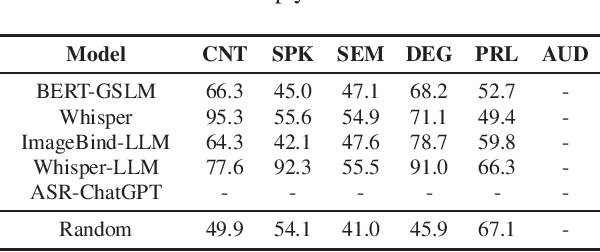
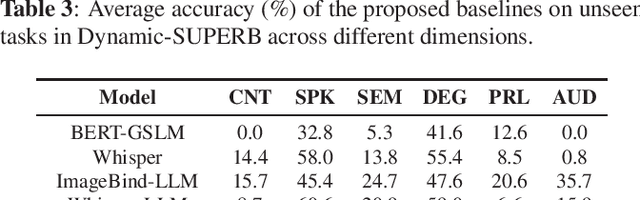
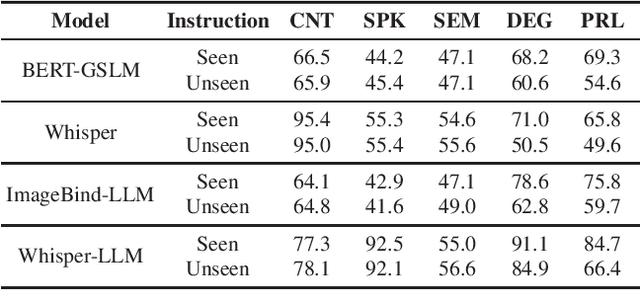
Text language models have shown remarkable zero-shot capability in generalizing to unseen tasks when provided with well-formulated instructions. However, existing studies in speech processing primarily focus on limited or specific tasks. Moreover, the lack of standardized benchmarks hinders a fair comparison across different approaches. Thus, we present Dynamic-SUPERB, a benchmark designed for building universal speech models capable of leveraging instruction tuning to perform multiple tasks in a zero-shot fashion. To achieve comprehensive coverage of diverse speech tasks and harness instruction tuning, we invite the community to collaborate and contribute, facilitating the dynamic growth of the benchmark. To initiate, Dynamic-SUPERB features 55 evaluation instances by combining 33 tasks and 22 datasets. This spans a broad spectrum of dimensions, providing a comprehensive platform for evaluation. Additionally, we propose several approaches to establish benchmark baselines. These include the utilization of speech models, text language models, and the multimodal encoder. Evaluation results indicate that while these baselines perform reasonably on seen tasks, they struggle with unseen ones. We also conducted an ablation study to assess the robustness and seek improvements in the performance. We release all materials to the public and welcome researchers to collaborate on the project, advancing technologies in the field together.
General Framework for Self-Supervised Model Priming for Parameter-Efficient Fine-tuning
Dec 02, 2022



Parameter-efficient methods (like Prompt or Adapters) for adapting pre-trained language models to downstream tasks have been popular recently. However, hindrances still prevent these methods from reaching their full potential. For example, two significant challenges are few-shot adaptation and cross-task generalization ability. To tackle these issues, we propose a general framework to enhance the few-shot adaptation and cross-domain generalization ability of parameter-efficient methods. In our framework, we prime the self-supervised model for parameter-efficient methods to rapidly adapt to various downstream few-shot tasks. To evaluate the authentic generalization ability of these parameter-efficient methods, we conduct experiments on a few-shot cross-domain benchmark containing 160 diverse NLP tasks. The experiment result reveals that priming by tuning PLM only with extra training tasks leads to the best performance. Also, we perform a comprehensive analysis of various parameter-efficient methods under few-shot cross-domain scenarios.