 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASPIRin: Action Space Projection for Interactivity-Optimized Reinforcement Learning in Full-Duplex Speech Language Models
Apr 11, 2026End-to-end full-duplex Speech Language Models (SLMs) require precise turn-taking for natural interaction. However, optimizing temporal dynamics via standard raw-token reinforcement learning (RL) degrades semantic quality, causing severe generative collapse and repetition. We propose ASPIRin, an interactivity-optimized RL framework that explicitly decouples when to speak from what to say. Using Action Space Projection, ASPIRin maps the text vocabulary into a coarse-grained binary state (active speech vs. inactive silence). By applying Group Relative Policy Optimization (GRPO) with rule-based rewards, it balances user interruption and response latency. Empirical evaluations show ASPIRin optimizes interactivity across turn-taking, backchanneling, and pause handling. Crucially, isolating timing from token selection preserves semantic coherence and reduces the portion of duplicate n-grams by over 50% compared to standard GRPO, effectively eliminating degenerative repetition.
How Auditory Knowledge in LLM Backbones Shapes Audio Language Models: A Holistic Evaluation
Mar 19, 2026Large language models (LLMs) have been widely used as knowledge backbones of Large Audio Language Models (LALMs), yet how much auditory knowledge they encode through text-only pre-training and how this affects downstream performance remains unclear. We study this gap by comparing different LLMs under two text-only and one audio-grounded setting: (1) direct probing on AKB-2000, a curated benchmark testing the breadth and depth of auditory knowledge; (2) cascade evaluation, where LLMs reason over text descriptions from an audio captioner; and (3) audio-grounded evaluation, where each LLM is fine-tuned into a Large Audio Language Model (LALM) with an audio encoder. Our findings reveal that auditory knowledge varies substantially across families, and text-only results are strongly correlated with audio performance. Our work provides empirical grounding for a comprehensive understanding of LLMs in audio research.
MUGEN: Evaluating and Improving Multi-audio Understanding of Large Audio-Language Models
Mar 10, 2026While multi-audio understanding is critical for large audio-language models (LALMs), it remains underexplored. We introduce MUGEN, a comprehensive benchmark evaluating this capability across speech, general audio, and music. Our experiments reveal consistent weaknesses in multi-audio settings, and performance degrades sharply as the number of concurrent audio inputs increases, identifying input scaling as a fundamental bottleneck. We further investigate training-free strategies and observe that Audio-Permutational Self-Consistency, which diversifies the order of audio candidates, helps models form more robust aggregated predictions, yielding up to 6.28% accuracy gains. Combining this permutation strategy with Chain-of-Thought further improves performance to 6.74%. These results expose blind spots in current LALMs and provide a foundation for evaluating complex auditory comprehension.
DeSTA2.5-Audio: Toward General-Purpose Large Audio Language Model with Self-Generated Cross-Modal Alignment
Jul 03, 2025
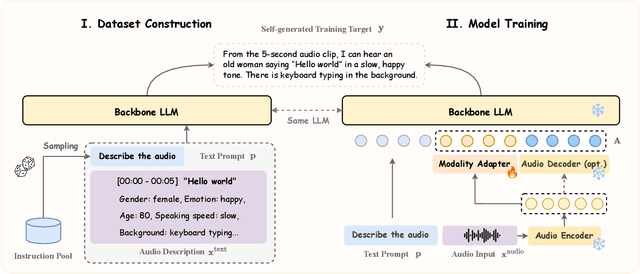


We introduce DeSTA2.5-Audio, a general-purpose Large Audio Language Model (LALM) designed for robust auditory perception and instruction-following, without requiring task-specific audio instruction-tuning. Recent LALMs typically augment Large Language Models (LLMs) with auditory capabilities by training on large-scale, manually curated or LLM-synthesized audio-instruction datasets. However, these approaches have often suffered from the catastrophic forgetting of the LLM's original language abilities. To address this, we revisit the data construction pipeline and propose DeSTA, a self-generated cross-modal alignment strategy in which the backbone LLM generates its own training targets. This approach preserves the LLM's native language proficiency while establishing effective audio-text alignment, thereby enabling zero-shot generalization without task-specific tuning. Using DeSTA, we construct DeSTA-AQA5M, a large-scale, task-agnostic dataset containing 5 million training samples derived from 7,000 hours of audio spanning 50 diverse datasets, including speech, environmental sounds, and music. DeSTA2.5-Audio achieves state-of-the-art or competitive performance across a wide range of audio-language benchmarks, including Dynamic-SUPERB, MMAU, SAKURA, Speech-IFEval, and VoiceBench. Comprehensive comparative studies demonstrate that our self-generated strategy outperforms widely adopted data construction and training strategies in both auditory perception and instruction-following capabilities. Our findings underscore the importance of carefully designed data construction in LALM development and offer practical insights for building robust, general-purpose LALMs.
Reducing Object Hallucination in Large Audio-Language Models via Audio-Aware Decoding
Jun 08, 2025Large Audio-Language Models (LALMs) can take audio and text as the inputs and answer questions about the audio. While prior LALMs have shown strong performance on standard benchmarks, there has been alarming evidence that LALMs can hallucinate what is presented in the audio. To mitigate the hallucination of LALMs, we introduce Audio-Aware Decoding (AAD), a lightweight inference-time strategy that uses contrastive decoding to compare the token prediction logits with and without the audio context. By contrastive decoding, AAD promotes the tokens whose probability increases when the audio is present. We conduct our experiment on object hallucination datasets with three LALMs and show that AAD improves the F1 score by 0.046 to 0.428. We also show that AAD can improve the accuracy on general audio QA datasets like Clotho-AQA by 5.4% to 10.3%. We conduct thorough ablation studies to understand the effectiveness of each component in AAD.
Speech-IFEval: Evaluating Instruction-Following and Quantifying Catastrophic Forgetting in Speech-Aware Language Models
May 25, 2025We introduce Speech-IFeval, an evaluation framework designed to assess instruction-following capabilities and quantify catastrophic forgetting in speech-aware language models (SLMs). Recent SLMs integrate speech perception with large language models (LLMs), often degrading textual capabilities due to speech-centric training. Existing benchmarks conflate speech perception with instruction-following, hindering evaluation of these distinct skills. To address this gap, we provide a benchmark for diagnosing the instruction-following abilities of SLMs. Our findings show that most SLMs struggle with even basic instructions, performing far worse than text-based LLMs. Additionally, these models are highly sensitive to prompt variations, often yielding inconsistent and unreliable outputs. We highlight core challenges and provide insights to guide future research, emphasizing the need for evaluation beyond task-level metrics.
Analyzing Mitigation Strategies for Catastrophic Forgetting in End-to-End Training of Spoken Language Models
May 23, 2025End-to-end training of Spoken Language Models (SLMs) commonly involves adapting pre-trained text-based Large Language Models (LLMs) to the speech modality through multi-stage training on diverse tasks such as ASR, TTS and spoken question answering (SQA). Although this multi-stage continual learning equips LLMs with both speech understanding and generation capabilities, the substantial differences in task and data distributions across stages can lead to catastrophic forgetting, where previously acquired knowledge is lost. This paper investigates catastrophic forgetting and evaluates three mitigation strategies-model merging, discounting the LoRA scaling factor, and experience replay to balance knowledge retention with new learning. Results show that experience replay is the most effective, with further gains achieved by combining it with other methods. These findings provide insights for developing more robust and efficient SLM training pipelines.
Building a Taiwanese Mandarin Spoken Language Model: A First Attempt
Nov 11, 2024



This technical report presents our initial attempt to build a spoken large language model (LLM) for Taiwanese Mandarin, specifically tailored to enable real-time, speech-to-speech interaction in multi-turn conversations. Our end-to-end model incorporates a decoder-only transformer architecture and aims to achieve seamless interaction while preserving the conversational flow, including full-duplex capabilities allowing simultaneous speaking and listening. The paper also details the training process, including data preparation with synthesized dialogues and adjustments for real-time interaction. We also developed a platform to evaluate conversational fluency and response coherence in multi-turn dialogues. We hope the release of the report can contribute to the future development of spoken LLMs in Taiwanese Mandarin.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
Developing Instruction-Following Speech Language Model Without Speech Instruction-Tuning Data
Sep 30, 2024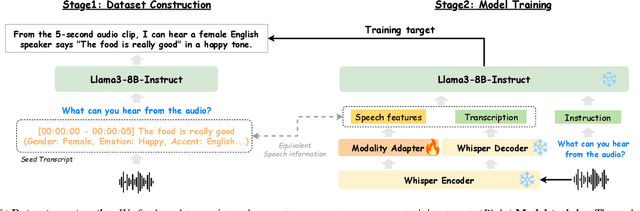
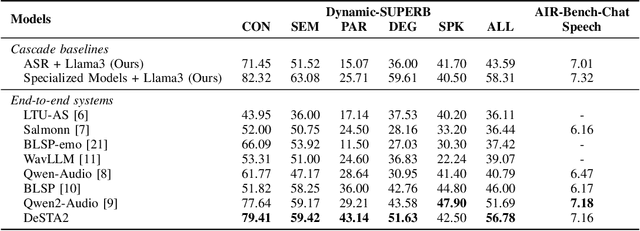
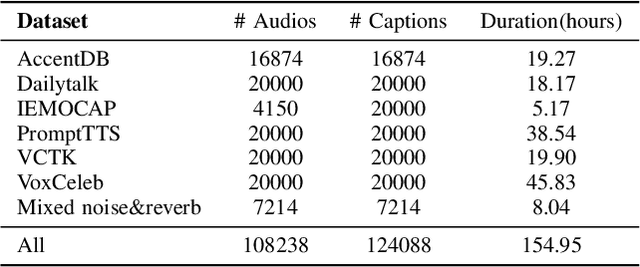
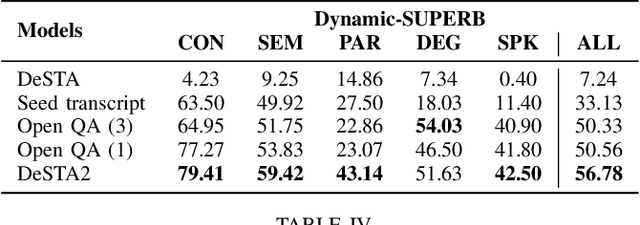
Recent end-to-end speech language models (SLMs) have expanded upon the capabilities of large language models (LLMs) by incorporating pre-trained speech models. However, these SLMs often undergo extensive speech instruction-tuning to bridge the gap between speech and text modalities. This requires significant annotation efforts and risks catastrophic forgetting of the original language capabilities. In this work, we present a simple yet effective automatic process for creating speech-text pair data that carefully injects speech paralinguistic understanding abilities into SLMs while preserving the inherent language capabilities of the text-based LLM. Our model demonstrates general capabilities for speech-related tasks without the need for speech instruction-tuning data, achieving impressive performance on Dynamic-SUPERB and AIR-Bench-Chat benchmarks. Furthermore, our model exhibits the ability to follow complex instructions derived from LLMs, such as specific output formatting and chain-of-thought reasoning. Our approach not only enhances the versatility and effectiveness of SLMs but also reduces reliance on extensive annotated datasets, paving the way for more efficient and capable speech understanding systems.