 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechCaps: Advancing Instruction-Based Universal Speech Models with Multi-Talker Speaking Style Captioning
Paper and Code

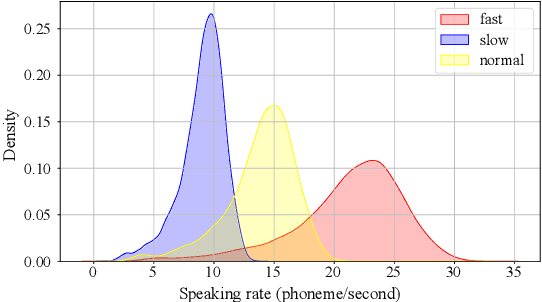
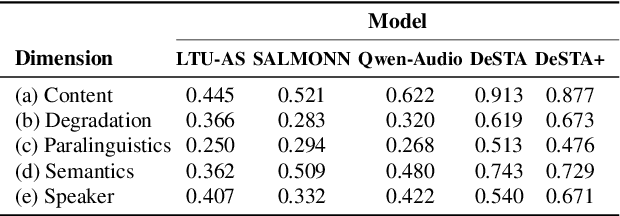
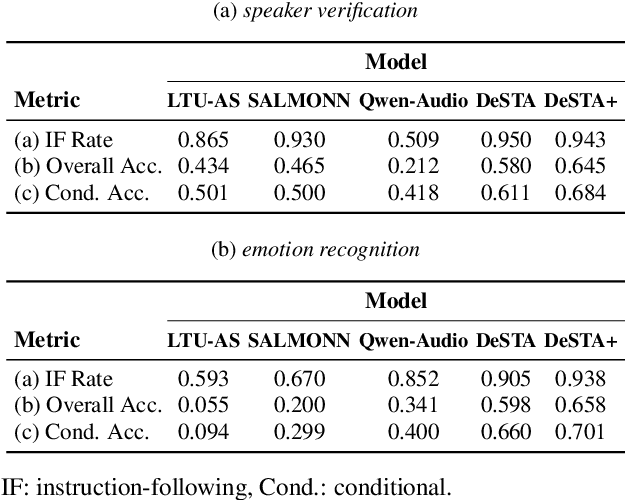
Instruction-based speech processing is becoming popular. Studies show that training with multiple tasks boosts performance, but collecting diverse, large-scale tasks and datasets is expensive. Thus, it is highly desirable to design a fundamental task that benefits other downstream tasks. This paper introduces a multi-talker speaking style captioning task to enhance the understanding of speaker and prosodic information. We used large language models to generate descriptions for multi-talker speech. Then, we trained our model with pre-training on this captioning task followed by instruction tuning. Evaluation on Dynamic-SUPERB shows our model outperforming the baseline pre-trained only on single-talker tasks, particularly in speaker and emotion recognition. Additionally, tests on a multi-talker QA task reveal that current models struggle with attributes such as gender, pitch, and speaking rate. The code and dataset are available at https://github.com/cyhuang-tw/speechcaps.