 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Mitigation Strategies for Catastrophic Forgetting in End-to-End Training of Spoken Language Models
May 23, 2025End-to-end training of Spoken Language Models (SLMs) commonly involves adapting pre-trained text-based Large Language Models (LLMs) to the speech modality through multi-stage training on diverse tasks such as ASR, TTS and spoken question answering (SQA). Although this multi-stage continual learning equips LLMs with both speech understanding and generation capabilities, the substantial differences in task and data distributions across stages can lead to catastrophic forgetting, where previously acquired knowledge is lost. This paper investigates catastrophic forgetting and evaluates three mitigation strategies-model merging, discounting the LoRA scaling factor, and experience replay to balance knowledge retention with new learning. Results show that experience replay is the most effective, with further gains achieved by combining it with other methods. These findings provide insights for developing more robust and efficient SLM training pipelines.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
SpeechCaps: Advancing Instruction-Based Universal Speech Models with Multi-Talker Speaking Style Captioning
Aug 25, 2024
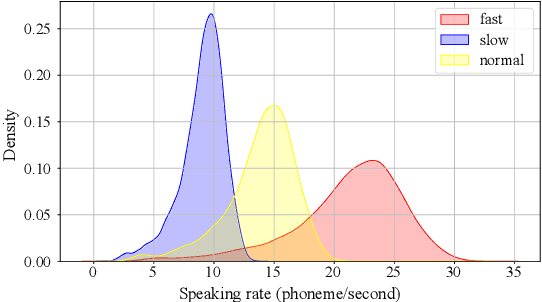
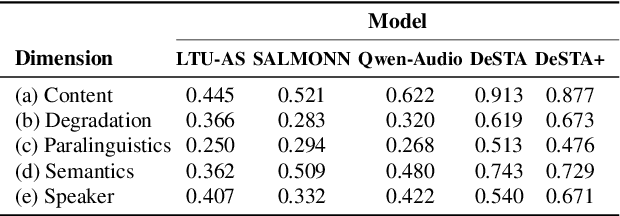
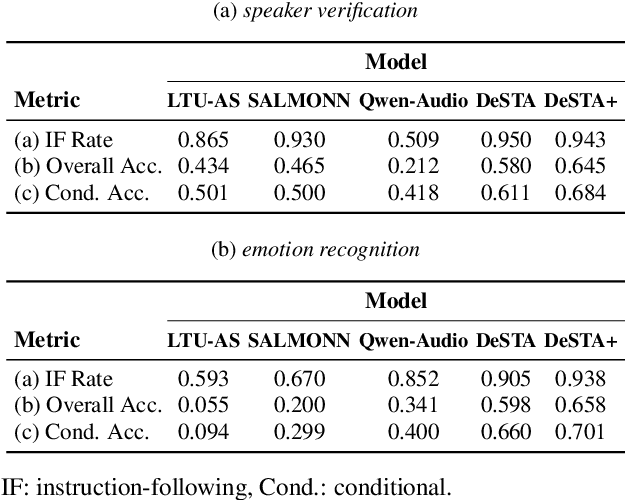
Instruction-based speech processing is becoming popular. Studies show that training with multiple tasks boosts performance, but collecting diverse, large-scale tasks and datasets is expensive. Thus, it is highly desirable to design a fundamental task that benefits other downstream tasks. This paper introduces a multi-talker speaking style captioning task to enhance the understanding of speaker and prosodic information. We used large language models to generate descriptions for multi-talker speech. Then, we trained our model with pre-training on this captioning task followed by instruction tuning. Evaluation on Dynamic-SUPERB shows our model outperforming the baseline pre-trained only on single-talker tasks, particularly in speaker and emotion recognition. Additionally, tests on a multi-talker QA task reveal that current models struggle with attributes such as gender, pitch, and speaking rate. The code and dataset are available at https://github.com/cyhuang-tw/speechcaps.
Investigating Zero-Shot Generalizability on Mandarin-English Code-Switched ASR and Speech-to-text Translation of Recent Foundation Models with Self-Supervision and Weak Supervision
Dec 30, 2023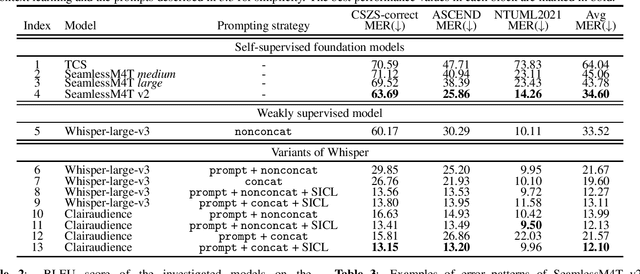

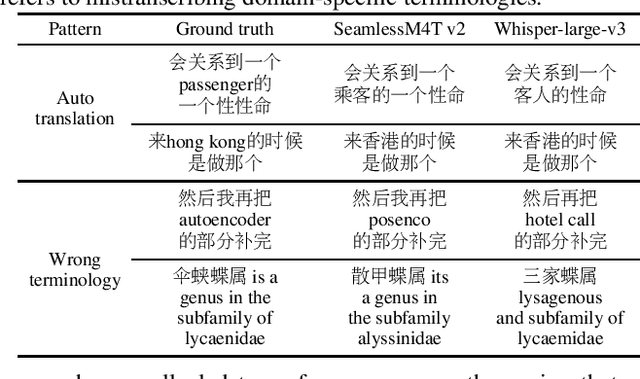
This work evaluated several cutting-edge large-scale foundation models based on self-supervision or weak supervision, including SeamlessM4T, SeamlessM4T v2, and Whisper-large-v3, on three code-switched corpora. We found that self-supervised models can achieve performances close to the supervised model, indicating the effectiveness of multilingual self-supervised pre-training. We also observed that these models still have room for improvement as they kept making similar mistakes and had unsatisfactory performances on modeling intra-sentential code-switching. In addition, the validity of several variants of Whisper was explored, and we concluded that they remained effective in a code-switching scenario, and similar techniques for self-supervised models are worth studying to boost the performance of code-switched tasks.
Dynamic-SUPERB: Towards A Dynamic, Collaborative, and Comprehensive Instruction-Tuning Benchmark for Speech
Sep 18, 2023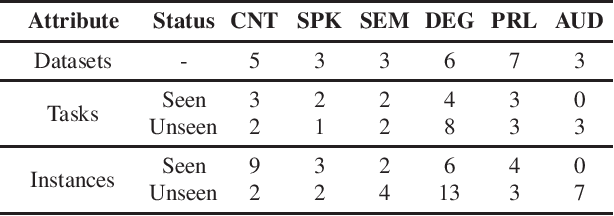
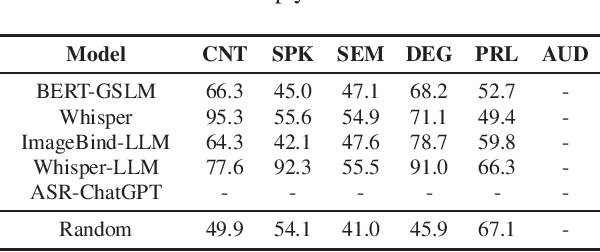
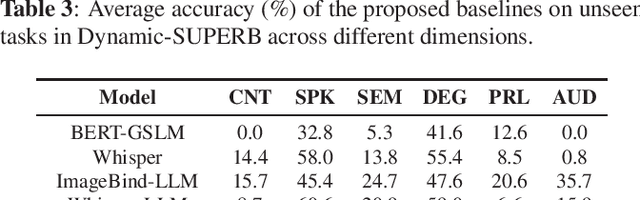
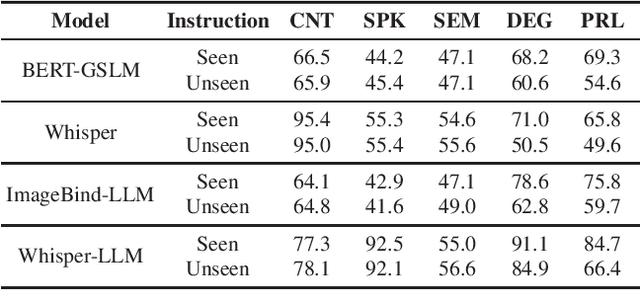
Text language models have shown remarkable zero-shot capability in generalizing to unseen tasks when provided with well-formulated instructions. However, existing studies in speech processing primarily focus on limited or specific tasks. Moreover, the lack of standardized benchmarks hinders a fair comparison across different approaches. Thus, we present Dynamic-SUPERB, a benchmark designed for building universal speech models capable of leveraging instruction tuning to perform multiple tasks in a zero-shot fashion. To achieve comprehensive coverage of diverse speech tasks and harness instruction tuning, we invite the community to collaborate and contribute, facilitating the dynamic growth of the benchmark. To initiate, Dynamic-SUPERB features 55 evaluation instances by combining 33 tasks and 22 datasets. This spans a broad spectrum of dimensions, providing a comprehensive platform for evaluation. Additionally, we propose several approaches to establish benchmark baselines. These include the utilization of speech models, text language models, and the multimodal encoder. Evaluation results indicate that while these baselines perform reasonably on seen tasks, they struggle with unseen ones. We also conducted an ablation study to assess the robustness and seek improvements in the performance. We release all materials to the public and welcome researchers to collaborate on the project, advancing technologies in the field together.