 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechCaps: Advancing Instruction-Based Universal Speech Models with Multi-Talker Speaking Style Captioning
Aug 25, 2024
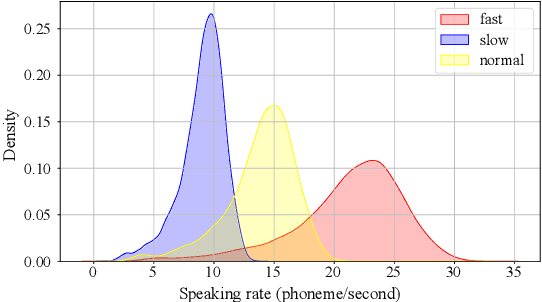
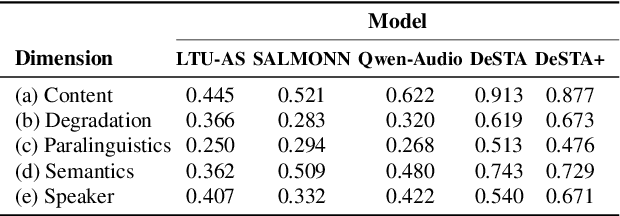
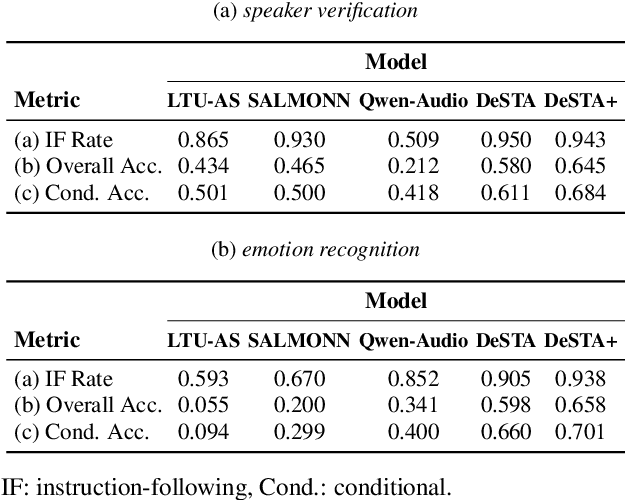
Instruction-based speech processing is becoming popular. Studies show that training with multiple tasks boosts performance, but collecting diverse, large-scale tasks and datasets is expensive. Thus, it is highly desirable to design a fundamental task that benefits other downstream tasks. This paper introduces a multi-talker speaking style captioning task to enhance the understanding of speaker and prosodic information. We used large language models to generate descriptions for multi-talker speech. Then, we trained our model with pre-training on this captioning task followed by instruction tuning. Evaluation on Dynamic-SUPERB shows our model outperforming the baseline pre-trained only on single-talker tasks, particularly in speaker and emotion recognition. Additionally, tests on a multi-talker QA task reveal that current models struggle with attributes such as gender, pitch, and speaking rate. The code and dataset are available at https://github.com/cyhuang-tw/speechcaps.
GSQA: An End-to-End Model for Generative Spoken Question Answering
Dec 25, 2023In recent advancements in spoken question answering (QA), end-to-end models have made significant strides. However, previous research has primarily focused on extractive span selection. While this extractive-based approach is effective when answers are present directly within the input, it falls short in addressing abstractive questions, where answers are not directly extracted but inferred from the given information. To bridge this gap, we introduce the first end-to-end Generative Spoken Question Answering (GSQA) model that empowers the system to engage in abstractive reasoning. The challenge in training our GSQA model lies in the absence of a spoken abstractive QA dataset. We propose using text models for initialization and leveraging the extractive QA dataset to transfer knowledge from the text generative model to the spoken generative model. Experimental results indicate that our model surpasses the previous extractive model by 3% on extractive QA datasets. Furthermore, the GSQA model has only been fine-tuned on the spoken extractive QA dataset. Despite not having seen any spoken abstractive QA data, it can still closely match the performance of the cascade model. In conclusion, our GSQA model shows the potential to generalize to a broad spectrum of questions, thus further expanding the spoken question answering capabilities of abstractive QA. Our code is available at https://voidful.github.io/GSQA
General Framework for Self-Supervised Model Priming for Parameter-Efficient Fine-tuning
Dec 02, 2022



Parameter-efficient methods (like Prompt or Adapters) for adapting pre-trained language models to downstream tasks have been popular recently. However, hindrances still prevent these methods from reaching their full potential. For example, two significant challenges are few-shot adaptation and cross-task generalization ability. To tackle these issues, we propose a general framework to enhance the few-shot adaptation and cross-domain generalization ability of parameter-efficient methods. In our framework, we prime the self-supervised model for parameter-efficient methods to rapidly adapt to various downstream few-shot tasks. To evaluate the authentic generalization ability of these parameter-efficient methods, we conduct experiments on a few-shot cross-domain benchmark containing 160 diverse NLP tasks. The experiment result reveals that priming by tuning PLM only with extra training tasks leads to the best performance. Also, we perform a comprehensive analysis of various parameter-efficient methods under few-shot cross-domain scenarios.