 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Script Representations in Speech Foundation Models Enable Zero-Shot Transliteration
Jan 06, 2026Multilingual speech foundation models such as Whisper are trained on web-scale data, where data for each language consists of a myriad of regional varieties. However, different regional varieties often employ different scripts to write the same language, rendering speech recognition output also subject to non-determinism in the output script. To mitigate this problem, we show that script is linearly encoded in the activation space of multilingual speech models, and that modifying activations at inference time enables direct control over output script. We find the addition of such script vectors to activations at test time can induce script change even in unconventional language-script pairings (e.g. Italian in Cyrillic and Japanese in Latin script). We apply this approach to inducing post-hoc control over the script of speech recognition output, where we observe competitive performance across all model sizes of Whisper.
Meta-Whisper: Speech-Based Meta-ICL for ASR on Low-Resource Languages
Sep 16, 2024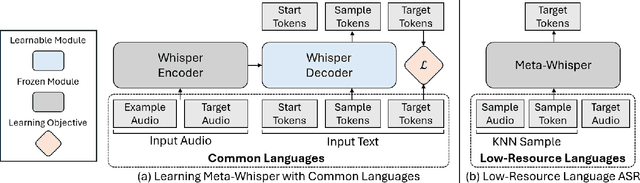
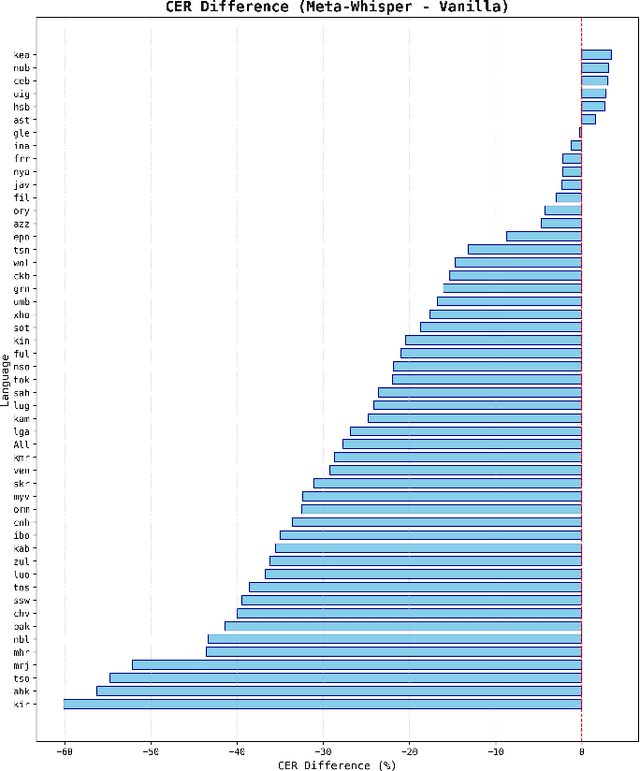


This paper presents Meta-Whisper, a novel approach to improve automatic speech recognition (ASR) for low-resource languages using the Whisper model. By leveraging Meta In-Context Learning (Meta-ICL) and a k-Nearest Neighbors (KNN) algorithm for sample selection, Meta-Whisper enhances Whisper's ability to recognize speech in unfamiliar languages without extensive fine-tuning. Experiments on the ML-SUPERB dataset show that Meta-Whisper significantly reduces the Character Error Rate (CER) for low-resource languages compared to the original Whisper model. This method offers a promising solution for developing more adaptable multilingual ASR systems, particularly for languages with limited resources.
GSQA: An End-to-End Model for Generative Spoken Question Answering
Dec 25, 2023In recent advancements in spoken question answering (QA), end-to-end models have made significant strides. However, previous research has primarily focused on extractive span selection. While this extractive-based approach is effective when answers are present directly within the input, it falls short in addressing abstractive questions, where answers are not directly extracted but inferred from the given information. To bridge this gap, we introduce the first end-to-end Generative Spoken Question Answering (GSQA) model that empowers the system to engage in abstractive reasoning. The challenge in training our GSQA model lies in the absence of a spoken abstractive QA dataset. We propose using text models for initialization and leveraging the extractive QA dataset to transfer knowledge from the text generative model to the spoken generative model. Experimental results indicate that our model surpasses the previous extractive model by 3% on extractive QA datasets. Furthermore, the GSQA model has only been fine-tuned on the spoken extractive QA dataset. Despite not having seen any spoken abstractive QA data, it can still closely match the performance of the cascade model. In conclusion, our GSQA model shows the potential to generalize to a broad spectrum of questions, thus further expanding the spoken question answering capabilities of abstractive QA. Our code is available at https://voidful.github.io/GSQA
An Exploration of In-Context Learning for Speech Language Model
Oct 19, 2023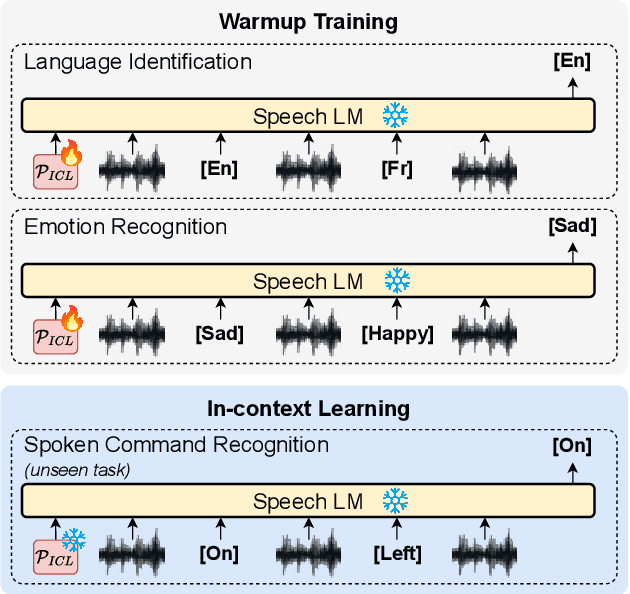
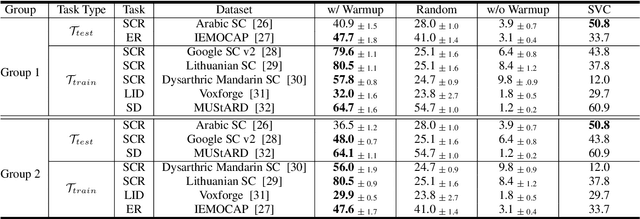
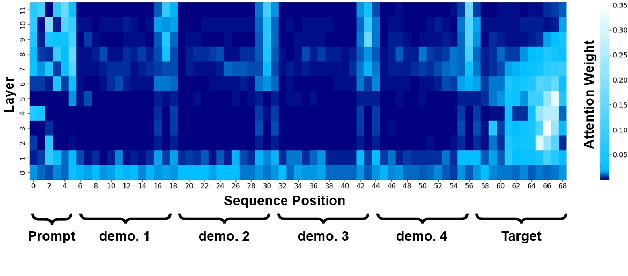
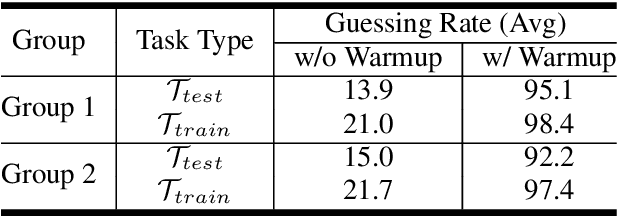
Ever since the development of GPT-3 in the natural language processing (NLP) field, in-context learning (ICL) has played an important role in utilizing large language models (LLMs). By presenting the LM utterance-label demonstrations at the input, the LM can accomplish few-shot learning without relying on gradient descent or requiring explicit modification of its parameters. This enables the LM to learn and adapt in a black-box manner. Despite the success of ICL in NLP, little work is exploring the possibility of ICL in speech processing. This study proposes the first exploration of ICL with a speech LM without text supervision. We first show that the current speech LM does not have the ICL capability. With the proposed warmup training, the speech LM can, therefore, perform ICL on unseen tasks. In this work, we verify the feasibility of ICL for speech LM on speech classification tasks.
Controllable User Dialogue Act Augmentation for Dialogue State Tracking
Jul 26, 2022



Prior work has demonstrated that data augmentation is useful for improving dialogue state tracking. However, there are many types of user utterances, while the prior method only considered the simplest one for augmentation, raising the concern about poor generalization capability. In order to better cover diverse dialogue acts and control the generation quality, this paper proposes controllable user dialogue act augmentation (CUDA-DST) to augment user utterances with diverse behaviors. With the augmented data, different state trackers gain improvement and show better robustness, achieving the state-of-the-art performance on MultiWOZ 2.1