 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRiSM: Benchmarking Phone Realization in Speech Models
Jan 20, 2026Phone recognition (PR) serves as the atomic interface for language-agnostic modeling for cross-lingual speech processing and phonetic analysis. Despite prolonged efforts in developing PR systems, current evaluations only measure surface-level transcription accuracy. We introduce PRiSM, the first open-source benchmark designed to expose blind spots in phonetic perception through intrinsic and extrinsic evaluation of PR systems. PRiSM standardizes transcription-based evaluation and assesses downstream utility in clinical, educational, and multilingual settings with transcription and representation probes. We find that diverse language exposure during training is key to PR performance, encoder-CTC models are the most stable, and specialized PR models still outperform Large Audio Language Models. PRiSM releases code, recipes, and datasets to move the field toward multilingual speech models with robust phonetic ability: https://github.com/changelinglab/prism.
Towards Comprehensive Semantic Speech Embeddings for Chinese Dialects
Jan 12, 2026Despite having hundreds of millions of speakers, Chinese dialects lag behind Mandarin in speech and language technologies. Most varieties are primarily spoken, making dialect-to-Mandarin speech-LLMs (large language models) more practical than dialect LLMs. Building dialect-to-Mandarin speech-LLMs requires speech representations with cross-dialect semantic alignment between Chinese dialects and Mandarin. In this paper, we achieve such a cross-dialect semantic alignment by training a speech encoder with ASR (automatic speech recognition)-only data, as demonstrated by speech-to-speech retrieval on a new benchmark of spoken Chinese varieties that we contribute. Our speech encoder further demonstrates state-of-the-art ASR performance on Chinese dialects. Together, our Chinese dialect benchmark, semantically aligned speech representations, and speech-to-speech retrieval evaluation lay the groundwork for future Chinese dialect speech-LLMs. We release the benchmark at https://github.com/kalvinchang/yubao.
Linear Script Representations in Speech Foundation Models Enable Zero-Shot Transliteration
Jan 06, 2026Multilingual speech foundation models such as Whisper are trained on web-scale data, where data for each language consists of a myriad of regional varieties. However, different regional varieties often employ different scripts to write the same language, rendering speech recognition output also subject to non-determinism in the output script. To mitigate this problem, we show that script is linearly encoded in the activation space of multilingual speech models, and that modifying activations at inference time enables direct control over output script. We find the addition of such script vectors to activations at test time can induce script change even in unconventional language-script pairings (e.g. Italian in Cyrillic and Japanese in Latin script). We apply this approach to inducing post-hoc control over the script of speech recognition output, where we observe competitive performance across all model sizes of Whisper.
CS-FLEURS: A Massively Multilingual and Code-Switched Speech Dataset
Sep 17, 2025We present CS-FLEURS, a new dataset for developing and evaluating code-switched speech recognition and translation systems beyond high-resourced languages. CS-FLEURS consists of 4 test sets which cover in total 113 unique code-switched language pairs across 52 languages: 1) a 14 X-English language pair set with real voices reading synthetically generated code-switched sentences, 2) a 16 X-English language pair set with generative text-to-speech 3) a 60 {Arabic, Mandarin, Hindi, Spanish}-X language pair set with the generative text-to-speech, and 4) a 45 X-English lower-resourced language pair test set with concatenative text-to-speech. Besides the four test sets, CS-FLEURS also provides a training set with 128 hours of generative text-to-speech data across 16 X-English language pairs. Our hope is that CS-FLEURS helps to broaden the scope of future code-switched speech research. Dataset link: https://huggingface.co/datasets/byan/cs-fleurs.
Leveraging Allophony in Self-Supervised Speech Models for Atypical Pronunciation Assessment
Feb 10, 2025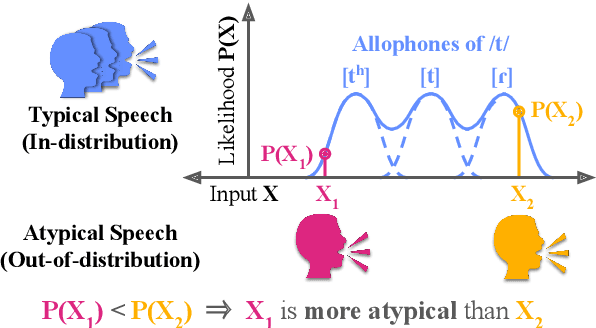
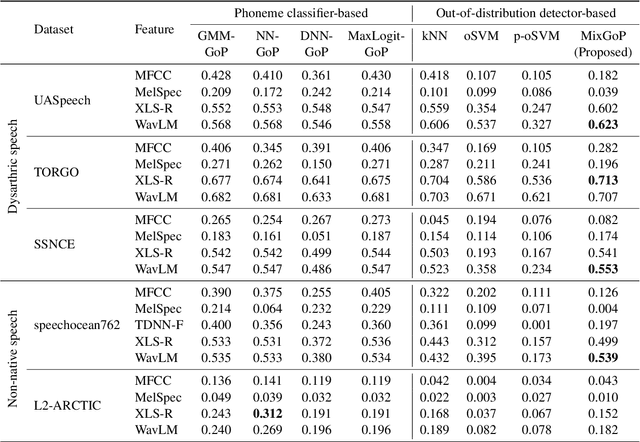
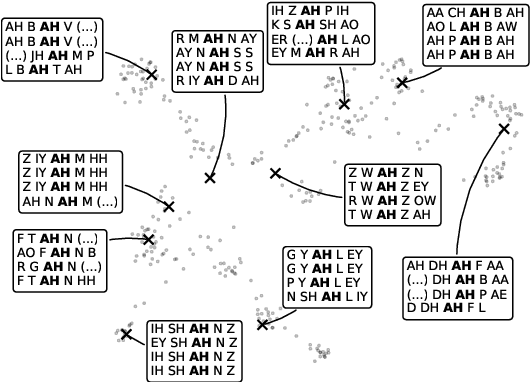
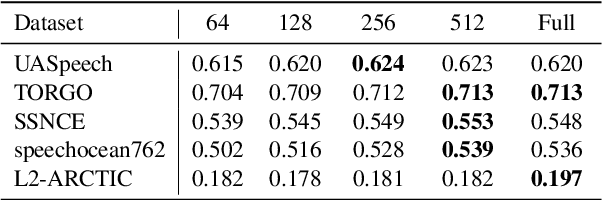
Allophony refers to the variation in the phonetic realization of a phoneme based on its phonetic environment. Modeling allophones is crucial for atypical pronunciation assessment, which involves distinguishing atypical from typical pronunciations. However, recent phoneme classifier-based approaches often simplify this by treating various realizations as a single phoneme, bypassing the complexity of modeling allophonic variation. Motivated by the acoustic modeling capabilities of frozen self-supervised speech model (S3M) features, we propose MixGoP, a novel approach that leverages Gaussian mixture models to model phoneme distributions with multiple subclusters. Our experiments show that MixGoP achieves state-of-the-art performance across four out of five datasets, including dysarthric and non-native speech. Our analysis further suggests that S3M features capture allophonic variation more effectively than MFCCs and Mel spectrograms, highlighting the benefits of integrating MixGoP with S3M features.
Programming by Examples Meets Historical Linguistics: A Large Language Model Based Approach to Sound Law Induction
Jan 27, 2025



Historical linguists have long written "programs" that convert reconstructed words in an ancestor language into their attested descendants via ordered string rewrite functions (called sound laws) However, writing these programs is time-consuming, motivating the development of automated Sound Law Induction (SLI) which we formulate as Programming by Examples (PBE) with Large Language Models (LLMs) in this paper. While LLMs have been effective for code generation, recent work has shown that PBE is challenging but improvable by fine-tuning, especially with training data drawn from the same distribution as evaluation data. In this paper, we create a conceptual framework of what constitutes a "similar distribution" for SLI and propose four kinds of synthetic data generation methods with varying amounts of inductive bias to investigate what leads to the best performance. Based on the results we create a SOTA open-source model for SLI as PBE (+6% pass rate with a third of the parameters of the second-best LLM) and also highlight exciting future directions for PBE research.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
Self-supervised Speech Representations Still Struggle with African American Vernacular English
Aug 26, 2024

Underperformance of ASR systems for speakers of African American Vernacular English (AAVE) and other marginalized language varieties is a well-documented phenomenon, and one that reinforces the stigmatization of these varieties. We investigate whether or not the recent wave of Self-Supervised Learning (SSL) speech models can close the gap in ASR performance between AAVE and Mainstream American English (MAE). We evaluate four SSL models (wav2vec 2.0, HuBERT, WavLM, and XLS-R) on zero-shot Automatic Speech Recognition (ASR) for these two varieties and find that these models perpetuate the bias in performance against AAVE. Additionally, the models have higher word error rates on utterances with more phonological and morphosyntactic features of AAVE. Despite the success of SSL speech models in improving ASR for low resource varieties, SSL pre-training alone may not bridge the gap between AAVE and MAE. Our code is publicly available at https://github.com/cmu-llab/s3m-aave.
Can Large Language Models Code Like a Linguist?: A Case Study in Low Resource Sound Law Induction
Jun 18, 2024



Historical linguists have long written a kind of incompletely formalized ''program'' that converts reconstructed words in an ancestor language into words in one of its attested descendants that consist of a series of ordered string rewrite functions (called sound laws). They do this by observing pairs of words in the reconstructed language (protoforms) and the descendent language (reflexes) and constructing a program that transforms protoforms into reflexes. However, writing these programs is error-prone and time-consuming. Prior work has successfully scaffolded this process computationally, but fewer researchers have tackled Sound Law Induction (SLI), which we approach in this paper by casting it as Programming by Examples. We propose a language-agnostic solution that utilizes the programming ability of Large Language Models (LLMs) by generating Python sound law programs from sound change examples. We evaluate the effectiveness of our approach for various LLMs, propose effective methods to generate additional language-agnostic synthetic data to fine-tune LLMs for SLI, and compare our method with existing automated SLI methods showing that while LLMs lag behind them they can complement some of their weaknesses.
Phonotactic Complexity across Dialects
Feb 20, 2024Received wisdom in linguistic typology holds that if the structure of a language becomes more complex in one dimension, it will simplify in another, building on the assumption that all languages are equally complex (Joseph and Newmeyer, 2012). We study this claim on a micro-level, using a tightly-controlled sample of Dutch dialects (across 366 collection sites) and Min dialects (across 60 sites), which enables a more fair comparison across varieties. Even at the dialect level, we find empirical evidence for a tradeoff between word length and a computational measure of phonotactic complexity from a LSTM-based phone-level language model-a result previously documented only at the language level. A generalized additive model (GAM) shows that dialects with low phonotactic complexity concentrate around the capital regions, which we hypothesize to correspond to prior hypotheses that language varieties of greater or more diverse populations show reduced phonotactic complexity. We also experiment with incorporating the auxiliary task of predicting syllable constituency, but do not find an increase in the negative correlation observed.