 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Code Like a Linguist?: A Case Study in Low Resource Sound Law Induction
Jun 18, 2024



Historical linguists have long written a kind of incompletely formalized ''program'' that converts reconstructed words in an ancestor language into words in one of its attested descendants that consist of a series of ordered string rewrite functions (called sound laws). They do this by observing pairs of words in the reconstructed language (protoforms) and the descendent language (reflexes) and constructing a program that transforms protoforms into reflexes. However, writing these programs is error-prone and time-consuming. Prior work has successfully scaffolded this process computationally, but fewer researchers have tackled Sound Law Induction (SLI), which we approach in this paper by casting it as Programming by Examples. We propose a language-agnostic solution that utilizes the programming ability of Large Language Models (LLMs) by generating Python sound law programs from sound change examples. We evaluate the effectiveness of our approach for various LLMs, propose effective methods to generate additional language-agnostic synthetic data to fine-tune LLMs for SLI, and compare our method with existing automated SLI methods showing that while LLMs lag behind them they can complement some of their weaknesses.
PWESuite: Phonetic Word Embeddings and Tasks They Facilitate
Apr 05, 2023



Word embeddings that map words into a fixed-dimensional vector space are the backbone of modern NLP. Most word embedding methods encode semantic information. However, phonetic information, which is important for some tasks, is often overlooked. In this work, we develop several novel methods which leverage articulatory features to build phonetically informed word embeddings, and present a set of phonetic word embeddings to encourage their community development, evaluation and use. While several methods for learning phonetic word embeddings already exist, there is a lack of consistency in evaluating their effectiveness. Thus, we also proposes several ways to evaluate both intrinsic aspects of phonetic word embeddings, such as word retrieval and correlation with sound similarity, and extrinsic performances, such as rhyme and cognate detection and sound analogies. We hope that our suite of tasks will promote reproducibility and provide direction for future research on phonetic word embeddings.
When Is TTS Augmentation Through a Pivot Language Useful?
Jul 20, 2022
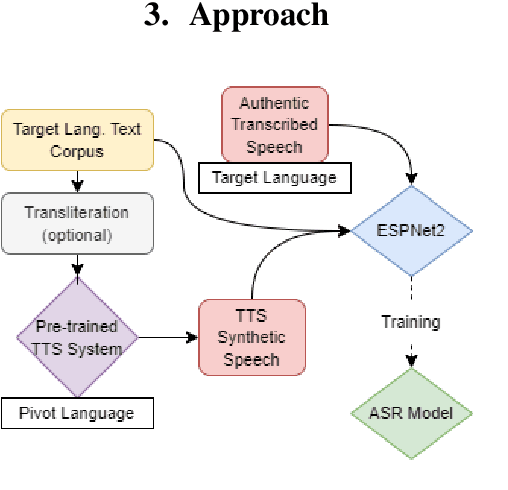

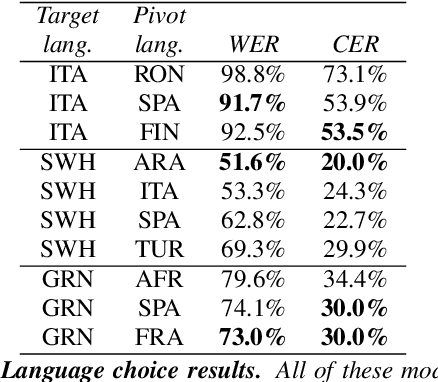
Developing Automatic Speech Recognition (ASR) for low-resource languages is a challenge due to the small amount of transcribed audio data. For many such languages, audio and text are available separately, but not audio with transcriptions. Using text, speech can be synthetically produced via text-to-speech (TTS) systems. However, many low-resource languages do not have quality TTS systems either. We propose an alternative: produce synthetic audio by running text from the target language through a trained TTS system for a higher-resource pivot language. We investigate when and how this technique is most effective in low-resource settings. In our experiments, using several thousand synthetic TTS text-speech pairs and duplicating authentic data to balance yields optimal results. Our findings suggest that searching over a set of candidate pivot languages can lead to marginal improvements and that, surprisingly, ASR performance can by harmed by increases in measured TTS quality. Application of these findings improves ASR by 64.5\% and 45.0\% character error reduction rate (CERR) respectively for two low-resource languages: Guaran\'i and Suba.
Towards Neural Programming Interfaces
Dec 10, 2020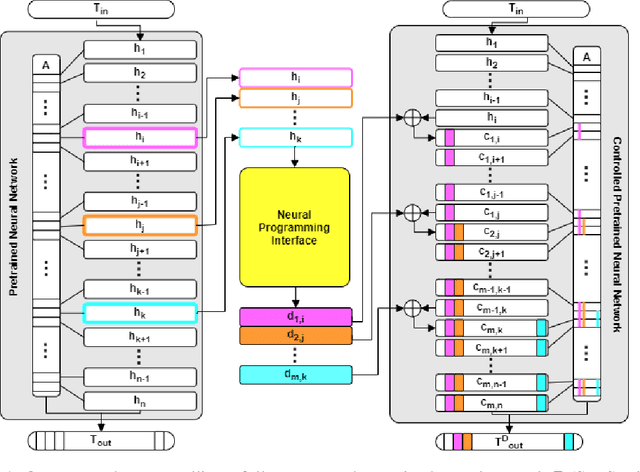
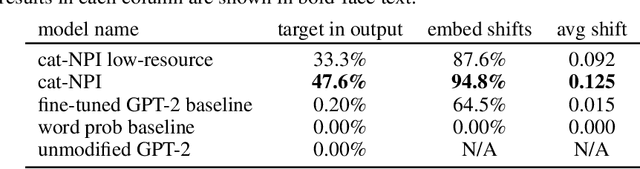
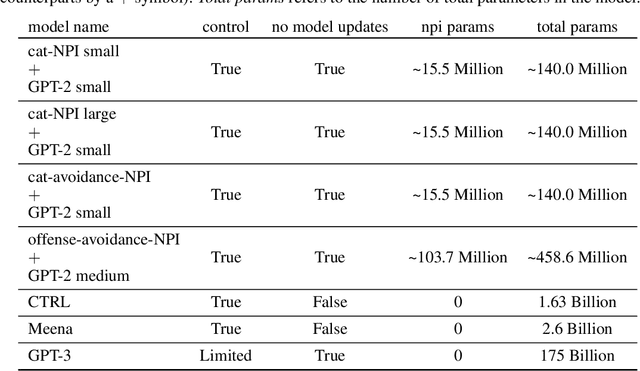
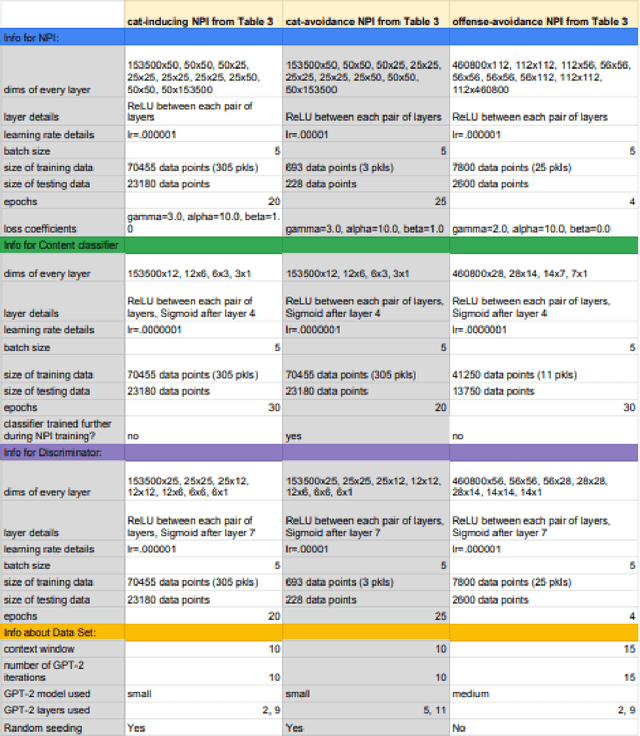
It is notoriously difficult to control the behavior of artificial neural networks such as generative neural language models. We recast the problem of controlling natural language generation as that of learning to interface with a pretrained language model, just as Application Programming Interfaces (APIs) control the behavior of programs by altering hyperparameters. In this new paradigm, a specialized neural network (called a Neural Programming Interface or NPI) learns to interface with a pretrained language model by manipulating the hidden activations of the pretrained model to produce desired outputs. Importantly, no permanent changes are made to the weights of the original model, allowing us to re-purpose pretrained models for new tasks without overwriting any aspect of the language model. We also contribute a new data set construction algorithm and GAN-inspired loss function that allows us to train NPI models to control outputs of autoregressive transformers. In experiments against other state-of-the-art approaches, we demonstrate the efficacy of our methods using OpenAI's GPT-2 model, successfully controlling noun selection, topic aversion, offensive speech filtering, and other aspects of language while largely maintaining the controlled model's fluency under deterministic settings.