 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Proto-Language Reconstruction
Apr 24, 2024



Proto-form reconstruction has been a painstaking process for linguists. Recently, computational models such as RNN and Transformers have been proposed to automate this process. We take three different approaches to improve upon previous methods, including data augmentation to recover missing reflexes, adding a VAE structure to the Transformer model for proto-to-language prediction, and using a neural machine translation model for the reconstruction task. We find that with the additional VAE structure, the Transformer model has a better performance on the WikiHan dataset, and the data augmentation step stabilizes the training.
Evaluating Self-supervised Speech Models on a Taiwanese Hokkien Corpus
Dec 06, 2023
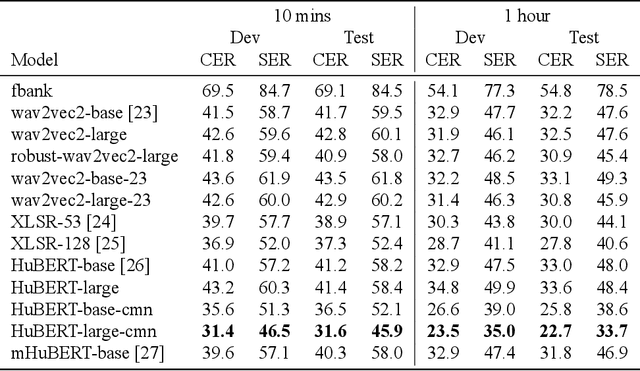
Taiwanese Hokkien is declining in use and status due to a language shift towards Mandarin in Taiwan. This is partly why it is a low resource language in NLP and speech research today. To ensure that the state of the art in speech processing does not leave Taiwanese Hokkien behind, we contribute a 1.5-hour dataset of Taiwanese Hokkien to ML-SUPERB's hidden set. Evaluating ML-SUPERB's suite of self-supervised learning (SSL) speech representations on our dataset, we find that model size does not consistently determine performance. In fact, certain smaller models outperform larger ones. Furthermore, linguistic alignment between pretraining data and the target language plays a crucial role.
Transformed Protoform Reconstruction
Jul 06, 2023



Protoform reconstruction is the task of inferring what morphemes or words appeared like in the ancestral languages of a set of daughter languages. Meloni et al. (2021) achieved the state-of-the-art on Latin protoform reconstruction with an RNN-based encoder-decoder with attention model. We update their model with the state-of-the-art seq2seq model: the Transformer. Our model outperforms their model on a suite of different metrics on two different datasets: their Romance data of 8,000 cognates spanning 5 languages and a Chinese dataset (Hou 2004) of 800+ cognates spanning 39 varieties. We also probe our model for potential phylogenetic signal contained in the model. Our code is publicly available at https://github.com/cmu-llab/acl-2023.
PWESuite: Phonetic Word Embeddings and Tasks They Facilitate
Apr 05, 2023



Word embeddings that map words into a fixed-dimensional vector space are the backbone of modern NLP. Most word embedding methods encode semantic information. However, phonetic information, which is important for some tasks, is often overlooked. In this work, we develop several novel methods which leverage articulatory features to build phonetically informed word embeddings, and present a set of phonetic word embeddings to encourage their community development, evaluation and use. While several methods for learning phonetic word embeddings already exist, there is a lack of consistency in evaluating their effectiveness. Thus, we also proposes several ways to evaluate both intrinsic aspects of phonetic word embeddings, such as word retrieval and correlation with sound similarity, and extrinsic performances, such as rhyme and cognate detection and sound analogies. We hope that our suite of tasks will promote reproducibility and provide direction for future research on phonetic word embeddings.
Learning the Ordering of Coordinate Compounds and Elaborate Expressions in Hmong, Lahu, and Chinese
Apr 08, 2022
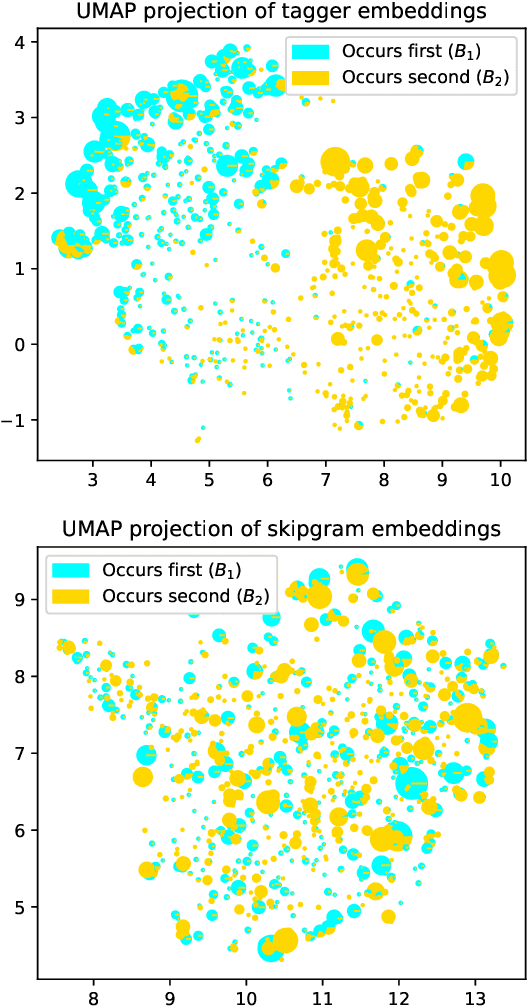
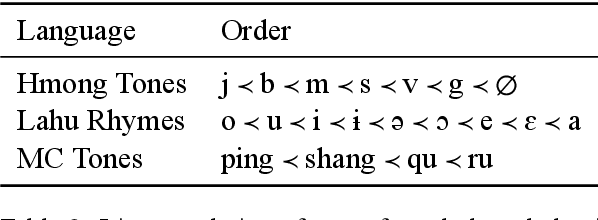
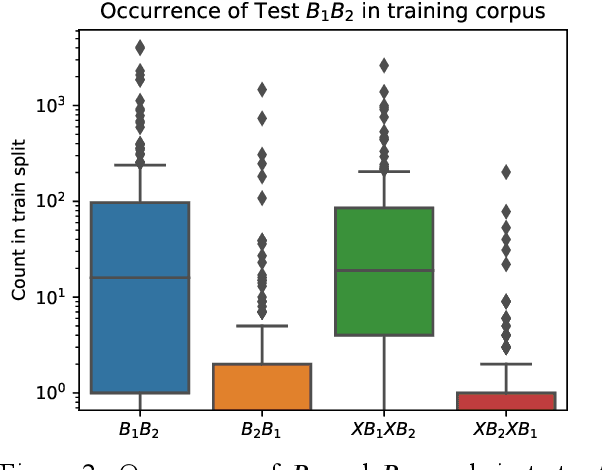
Coordinate compounds (CCs) and elaborate expressions (EEs) are coordinate constructions common in languages of East and Southeast Asia. Mortensen (2006) claims that (1) the linear ordering of EEs and CCs in Hmong, Lahu, and Chinese can be predicted via phonological hierarchies and (2) these phonological hierarchies lack a clear phonetic rationale. These claims are significant because morphosyntax has often been seen as in a feed-forward relationship with phonology, and phonological generalizations have often been assumed to be phonetically "natural". We investigate whether the ordering of CCs and EEs can be learned empirically and whether computational models (classifiers and sequence labeling models) learn unnatural hierarchies similar to those posited by Mortensen (2006). We find that decision trees and SVMs learn to predict the order of CCs/EEs on the basis of phonology, with DTs learning hierarchies strikingly similar to those proposed by Mortensen. However, we also find that a neural sequence labeling model is able to learn the ordering of elaborate expressions in Hmong very effectively without using any phonological information. We argue that EE ordering can be learned through two independent routes: phonology and lexical distribution, presenting a more nuanced picture than previous work. [ISO 639-3:hmn, lhu, cmn]