 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Proto-Language Reconstruction
Apr 24, 2024



Proto-form reconstruction has been a painstaking process for linguists. Recently, computational models such as RNN and Transformers have been proposed to automate this process. We take three different approaches to improve upon previous methods, including data augmentation to recover missing reflexes, adding a VAE structure to the Transformer model for proto-to-language prediction, and using a neural machine translation model for the reconstruction task. We find that with the additional VAE structure, the Transformer model has a better performance on the WikiHan dataset, and the data augmentation step stabilizes the training.
Variational Deep Survival Machines: Survival Regression with Censored Outcomes
Apr 24, 2024


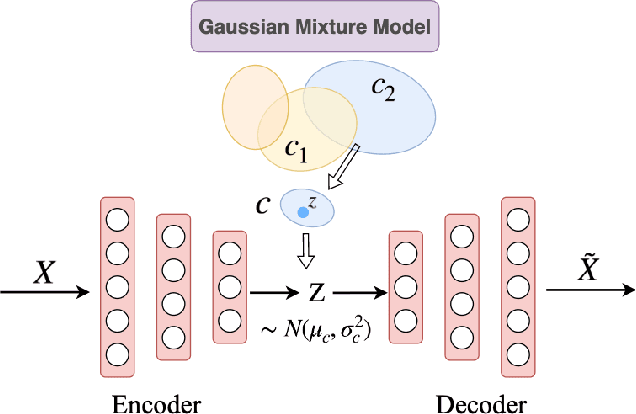
Survival regression aims to predict the time when an event of interest will take place, typically a death or a failure. A fully parametric method [18] is proposed to estimate the survival function as a mixture of individual parametric distributions in the presence of censoring. In this paper, We present a novel method to predict the survival time by better clustering the survival data and combine primitive distributions. We propose two variants of variational auto-encoder (VAE), discrete and continuous, to generate the latent variables for clustering input covariates. The model is trained end to end by jointly optimizing the VAE loss and regression loss. Thorough experiments on dataset SUPPORT and FLCHAIN show that our method can effectively improve the clustering result and reach competitive scores with previous methods. We demonstrate the superior result of our model prediction in the long-term. Our code is available at https://github.com/qinzzz/auton-survival-785.
MAF: Multimodal Alignment Framework for Weakly-Supervised Phrase Grounding
Oct 12, 2020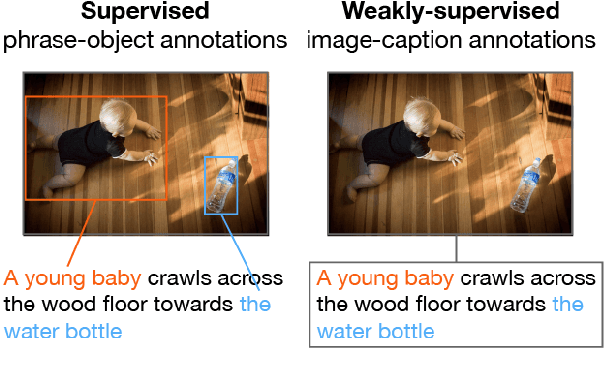
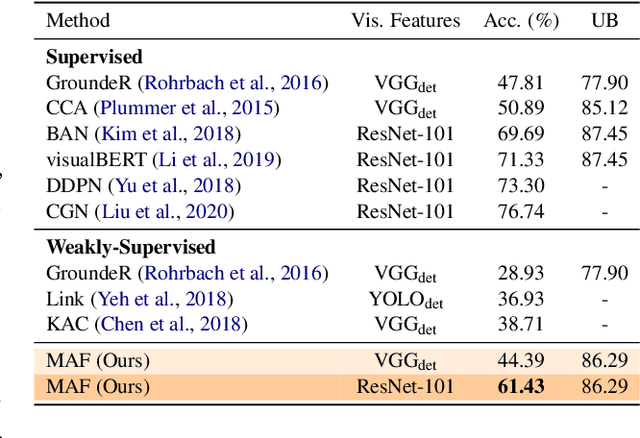
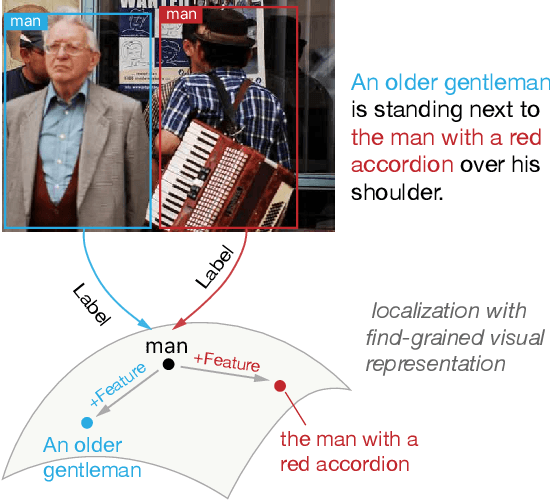

Phrase localization is a task that studies the mapping from textual phrases to regions of an image. Given difficulties in annotating phrase-to-object datasets at scale, we develop a Multimodal Alignment Framework (MAF) to leverage more widely-available caption-image datasets, which can then be used as a form of weak supervision. We first present algorithms to model phrase-object relevance by leveraging fine-grained visual representations and visually-aware language representations. By adopting a contrastive objective, our method uses information in caption-image pairs to boost the performance in weakly-supervised scenarios. Experiments conducted on the widely-adopted Flickr30k dataset show a significant improvement over existing weakly-supervised methods. With the help of the visually-aware language representations, we can also improve the previous best unsupervised result by 5.56%. We conduct ablation studies to show that both our novel model and our weakly-supervised strategies significantly contribute to our strong results.