 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAF: Multimodal Alignment Framework for Weakly-Supervised Phrase Grounding
Paper and Code
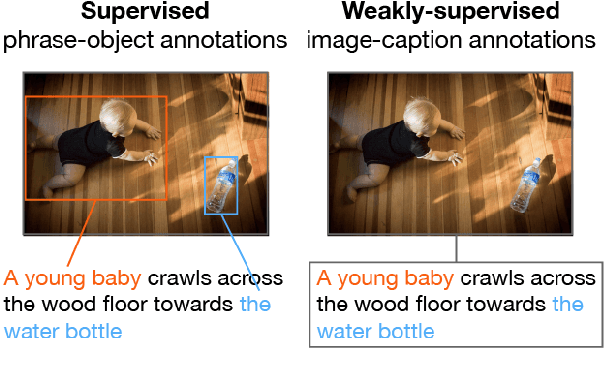
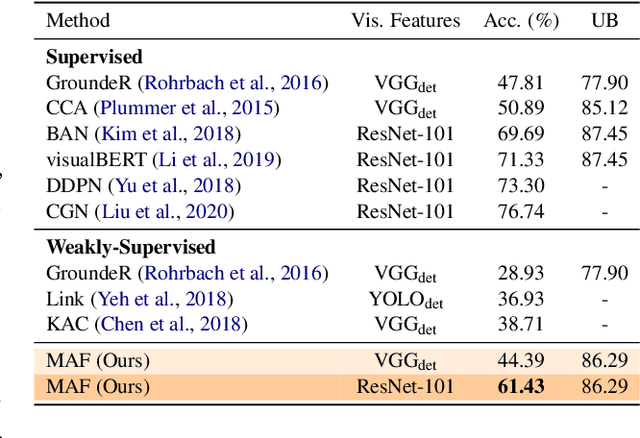
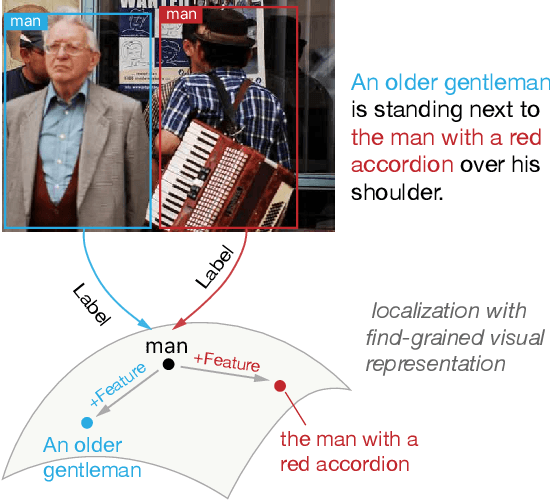

Phrase localization is a task that studies the mapping from textual phrases to regions of an image. Given difficulties in annotating phrase-to-object datasets at scale, we develop a Multimodal Alignment Framework (MAF) to leverage more widely-available caption-image datasets, which can then be used as a form of weak supervision. We first present algorithms to model phrase-object relevance by leveraging fine-grained visual representations and visually-aware language representations. By adopting a contrastive objective, our method uses information in caption-image pairs to boost the performance in weakly-supervised scenarios. Experiments conducted on the widely-adopted Flickr30k dataset show a significant improvement over existing weakly-supervised methods. With the help of the visually-aware language representations, we can also improve the previous best unsupervised result by 5.56%. We conduct ablation studies to show that both our novel model and our weakly-supervised strategies significantly contribute to our strong results.