 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmissive Bias in Religious Representation: Benchmarking LLM Answers to Everyday Ethical Decision-making
May 23, 2026As large language models become a default source of guidance on personal, moral, and existential questions, it matters whether they draw on the religious frameworks that have historically shaped such reasoning, or systematically omit them. In this paper, we ask a deliberately narrow question: when posed an everyday ethical question for which religious perspectives may be valuable, do LLMs invoke religion at all? In contrast to benchmarks that look for the presence of political leanings or social bias, we look for the absence of religious representation as a dimension of value alignment and bias in LLMs. We term this ``omissive bias.'' To measure omissive bias, we contribute the AllFaith Religious Representation Benchmark: 150 ethically and personally salient questions, sourced from in-the-wild chat transcripts and faith-community contributors, paired with an LLM-as-judge rubric that gives full credit for any mention of a religion, a religious practice, or a religious leader. The questions are not themselves about religion--they are open-ended questions about grief, forgiveness, relationships, purpose, and honesty, where religion is one valuable perspective among several. We also run a human-subjects survey to compare LLM behavior against human expectations. Evaluating 27 models, we find that LLMs consistently underrepresent religion relative to human expectations. The omission is asymmetric: models invoke religion more readily for abstract existential questions (meaning, death, truth) than for the practical personal situations--grief, marriage, family conflict, addiction--where many people most rely on it. It is not our purpose to adjudicate which values LLMs should hold. We argue, more modestly, that current LLM responses overlook critical opportunities to reflect religious frameworks that many people draw on when navigating personal and ethical challenges.
Language models struggle with compartmentalization
May 19, 2026In the training data used by large language models (LLMs), the same latent concept is often presented in multiple distinct ways: the same facts appear in English and Swahili; many functions can be expressed in both Python and Haskell; we can express propositions in both formal and natural language. We show that LLMs can exhibit compartmentalization, where they fail to identify and share statistical strength between distinct presentations of unified concepts. In the worst case, LLMs simply learn parallel internal representations of each presentation of the concept, saturating model capacity with redundancies and decreasing sample efficiency with the number of such presentations. We also demonstrate that synthetic parallel data can fail to improve this despite being easily learned itself. Under this framework, we find that, for small models, early multilingual learning is nearly entirely compartmentalized. Finally, all interventions that we study exhibit a phase transition in which their effectiveness depends on the number of distinct presentations, suggesting that the language modeling objective may only inconsistently unify representations.
Arti-"fickle" Intelligence: Using LLMs as a Tool for Inference in the Political and Social Sciences
Apr 04, 2025Generative large language models (LLMs) are incredibly useful, versatile, and promising tools. However, they will be of most use to political and social science researchers when they are used in a way that advances understanding about real human behaviors and concerns. To promote the scientific use of LLMs, we suggest that researchers in the political and social sciences need to remain focused on the scientific goal of inference. To this end, we discuss the challenges and opportunities related to scientific inference with LLMs, using validation of model output as an illustrative case for discussion. We propose a set of guidelines related to establishing the failure and success of LLMs when completing particular tasks, and discuss how we can make inferences from these observations. We conclude with a discussion of how this refocus will improve the accumulation of shared scientific knowledge about these tools and their uses in the social sciences.
Features that Make a Difference: Leveraging Gradients for Improved Dictionary Learning
Nov 15, 2024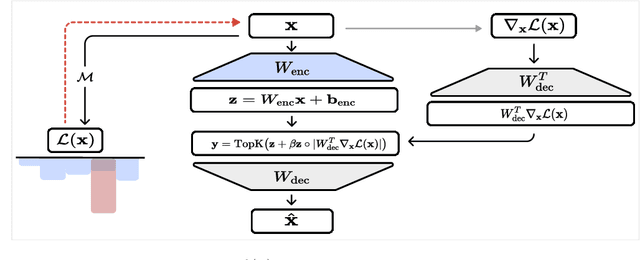
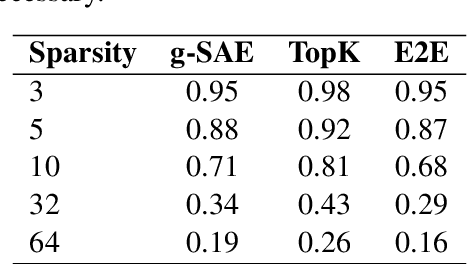
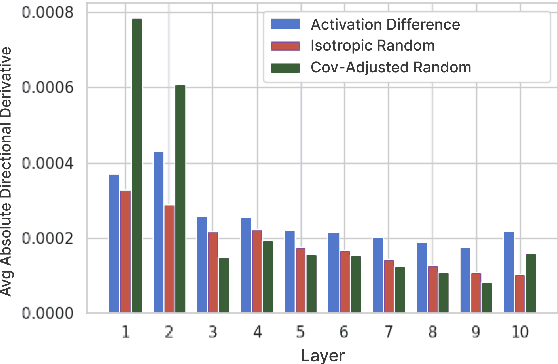
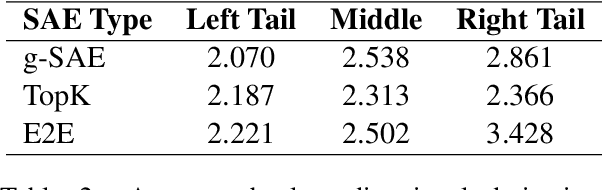
Sparse Autoencoders (SAEs) are a promising approach for extracting neural network representations by learning a sparse and overcomplete decomposition of the network's internal activations. However, SAEs are traditionally trained considering only activation values and not the effect those activations have on downstream computations. This limits the information available to learn features, and biases the autoencoder towards neglecting features which are represented with small activation values but strongly influence model outputs. To address this, we introduce Gradient SAEs (g-SAEs), which modify the $k$-sparse autoencoder architecture by augmenting the TopK activation function to rely on the gradients of the input activation when selecting the $k$ elements. For a given sparsity level, g-SAEs produce reconstructions that are more faithful to original network performance when propagated through the network. Additionally, we find evidence that g-SAEs learn latents that are on average more effective at steering models in arbitrary contexts. By considering the downstream effects of activations, our approach leverages the dual nature of neural network features as both $\textit{representations}$, retrospectively, and $\textit{actions}$, prospectively. While previous methods have approached the problem of feature discovery primarily focused on the former aspect, g-SAEs represent a step towards accounting for the latter as well.
Towards Coding Social Science Datasets with Language Models
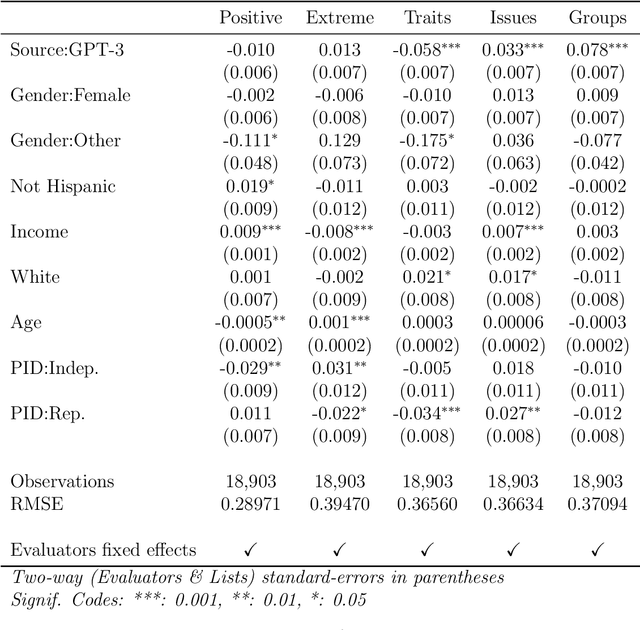
Jun 03, 2023Researchers often rely on humans to code (label, annotate, etc.) large sets of texts. This kind of human coding forms an important part of social science research, yet the coding process is both resource intensive and highly variable from application to application. In some cases, efforts to automate this process have achieved human-level accuracies, but to achieve this, these attempts frequently rely on thousands of hand-labeled training examples, which makes them inapplicable to small-scale research studies and costly for large ones. Recent advances in a specific kind of artificial intelligence tool - language models (LMs) - provide a solution to this problem. Work in computer science makes it clear that LMs are able to classify text, without the cost (in financial terms and human effort) of alternative methods. To demonstrate the possibilities of LMs in this area of political science, we use GPT-3, one of the most advanced LMs, as a synthetic coder and compare it to human coders. We find that GPT-3 can match the performance of typical human coders and offers benefits over other machine learning methods of coding text. We find this across a variety of domains using very different coding procedures. This provides exciting evidence that language models can serve as a critical advance in the coding of open-ended texts in a variety of applications.
AI Chat Assistants can Improve Conversations about Divisive Topics
Feb 21, 2023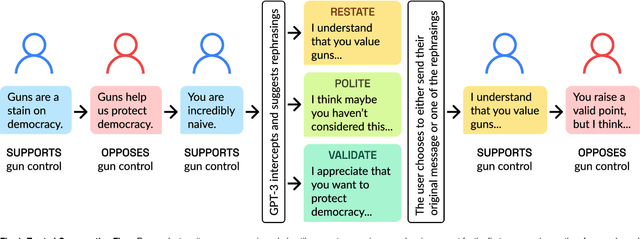
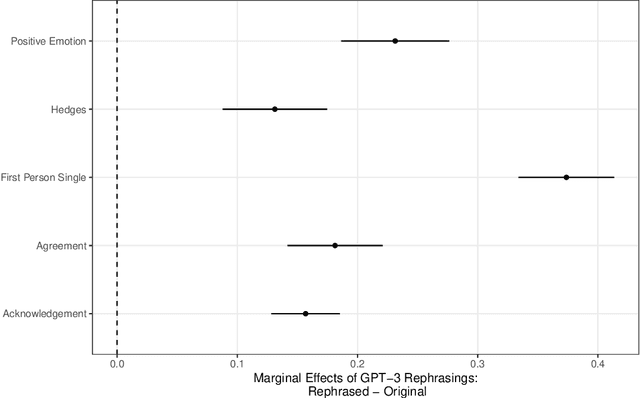
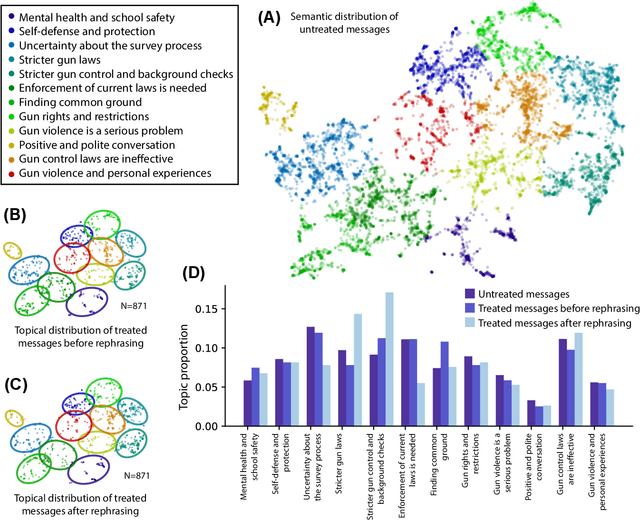
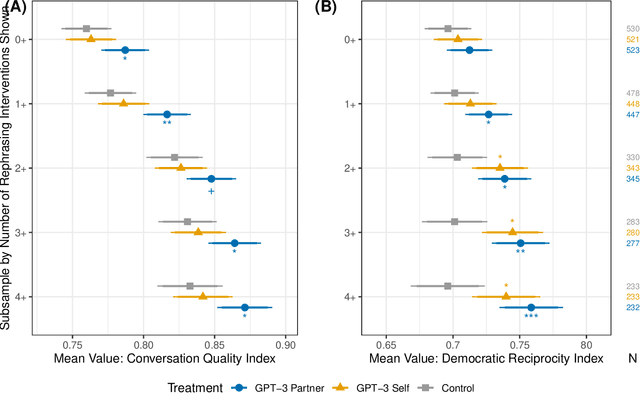
A rapidly increasing amount of human conversation occurs online. But divisiveness and conflict can fester in text-based interactions on social media platforms, in messaging apps, and on other digital forums. Such toxicity increases polarization and, importantly, corrodes the capacity of diverse societies to develop efficient solutions to complex social problems that impact everyone. Scholars and civil society groups promote interventions that can make interpersonal conversations less divisive or more productive in offline settings, but scaling these efforts to the amount of discourse that occurs online is extremely challenging. We present results of a large-scale experiment that demonstrates how online conversations about divisive topics can be improved with artificial intelligence tools. Specifically, we employ a large language model to make real-time, evidence-based recommendations intended to improve participants' perception of feeling understood in conversations. We find that these interventions improve the reported quality of the conversation, reduce political divisiveness, and improve the tone, without systematically changing the content of the conversation or moving people's policy attitudes. These findings have important implications for future research on social media, political deliberation, and the growing community of scholars interested in the place of artificial intelligence within computational social science.
Prompt Compression and Contrastive Conditioning for Controllability and Toxicity Reduction in Language Models
Oct 06, 2022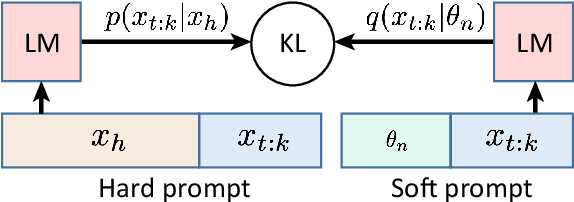

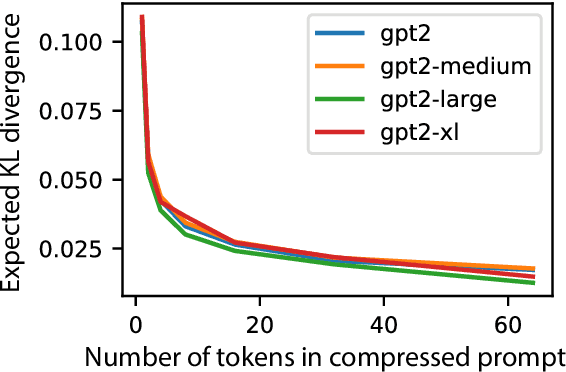
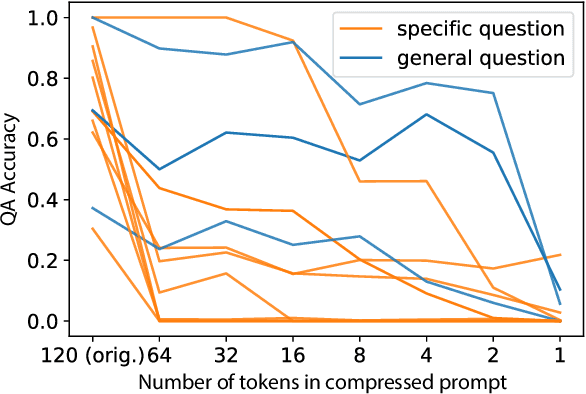
We explore the idea of compressing the prompts used to condition language models, and show that compressed prompts can retain a substantive amount of information about the original prompt. For severely compressed prompts, while fine-grained information is lost, abstract information and general sentiments can be retained with surprisingly few parameters, which can be useful in the context of decode-time algorithms for controllability and toxicity reduction. We explore contrastive conditioning to steer language model generation towards desirable text and away from undesirable text, and find that some complex prompts can be effectively compressed into a single token to guide generation. We also show that compressed prompts are largely compositional, and can be constructed such that they can be used to control independent aspects of generated text.
Out of One, Many: Using Language Models to Simulate Human Samples
Sep 14, 2022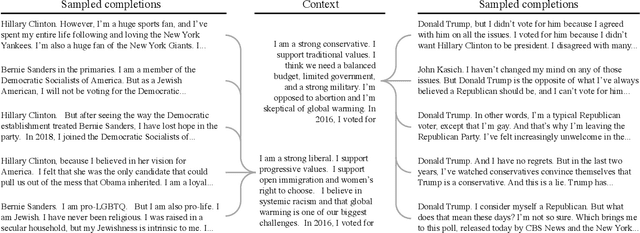
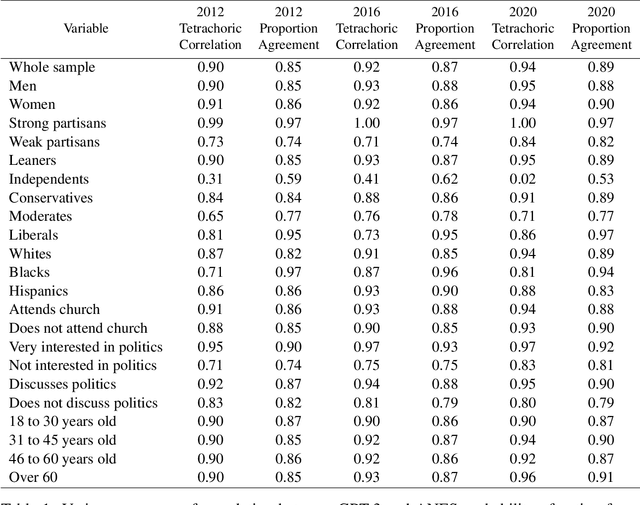

We propose and explore the possibility that language models can be studied as effective proxies for specific human sub-populations in social science research. Practical and research applications of artificial intelligence tools have sometimes been limited by problematic biases (such as racism or sexism), which are often treated as uniform properties of the models. We show that the "algorithmic bias" within one such tool -- the GPT-3 language model -- is instead both fine-grained and demographically correlated, meaning that proper conditioning will cause it to accurately emulate response distributions from a wide variety of human subgroups. We term this property "algorithmic fidelity" and explore its extent in GPT-3. We create "silicon samples" by conditioning the model on thousands of socio-demographic backstories from real human participants in multiple large surveys conducted in the United States. We then compare the silicon and human samples to demonstrate that the information contained in GPT-3 goes far beyond surface similarity. It is nuanced, multifaceted, and reflects the complex interplay between ideas, attitudes, and socio-cultural context that characterize human attitudes. We suggest that language models with sufficient algorithmic fidelity thus constitute a novel and powerful tool to advance understanding of humans and society across a variety of disciplines.
An Information-theoretic Approach to Prompt Engineering Without Ground Truth Labels
Mar 21, 2022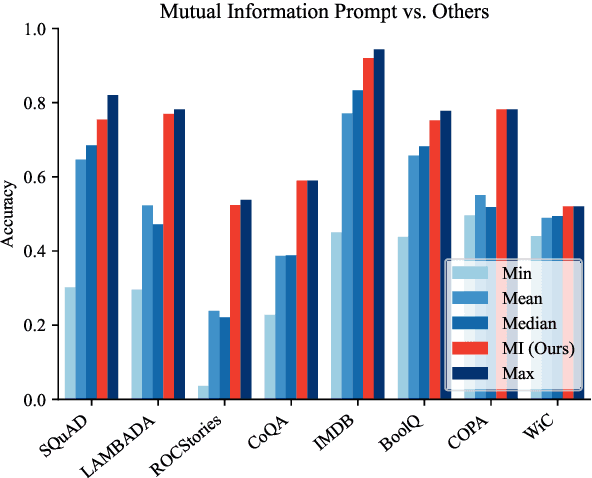
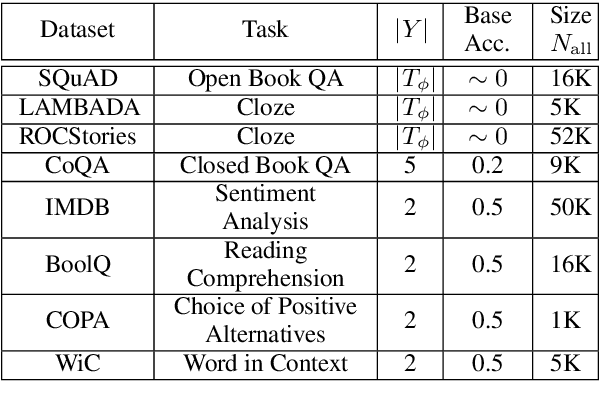
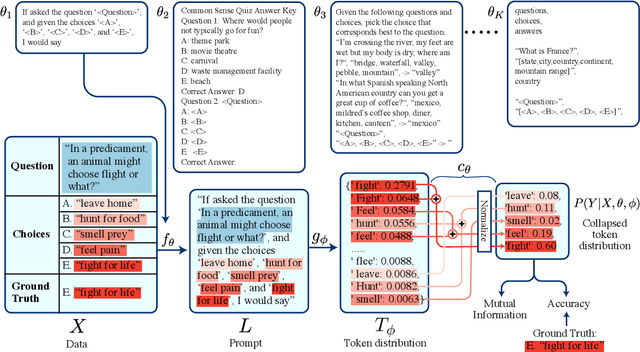
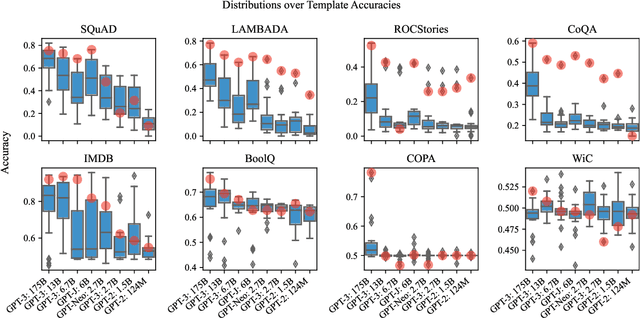
Pre-trained language models derive substantial linguistic and factual knowledge from the massive corpora on which they are trained, and prompt engineering seeks to align these models to specific tasks. Unfortunately, existing prompt engineering methods require significant amounts of labeled data, access to model parameters, or both. We introduce a new method for selecting prompt templates \textit{without labeled examples} and \textit{without direct access to the model}. Specifically, over a set of candidate templates, we choose the template that maximizes the mutual information between the input and the corresponding model output. Across 8 datasets representing 7 distinct NLP tasks, we show that when a template has high mutual information, it also has high accuracy on the task. On the largest model, selecting prompts with our method gets 90\% of the way from the average prompt accuracy to the best prompt accuracy and requires no ground truth labels.
Leveraging the Inductive Bias of Large Language Models for Abstract Textual Reasoning
Oct 05, 2021
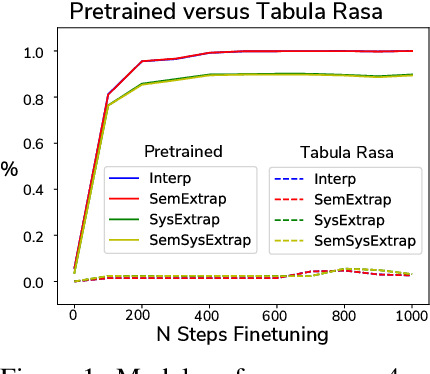
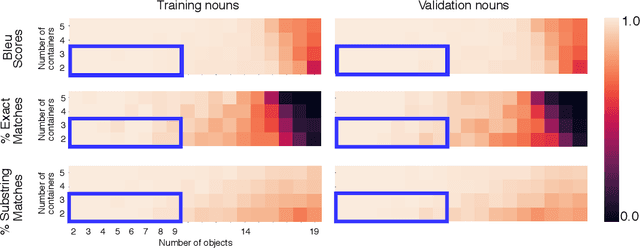
Large natural language models (such as GPT-3 or T5) demonstrate impressive abilities across a range of general NLP tasks. Here, we show that the knowledge embedded in such models provides a useful inductive bias, not just on traditional NLP tasks, but also in the nontraditional task of training a symbolic reasoning engine. We observe that these engines learn quickly and generalize in a natural way that reflects human intuition. For example, training such a system to model block-stacking might naturally generalize to stacking other types of objects because of structure in the real world that has been partially captured by the language describing it. We study several abstract textual reasoning tasks, such as object manipulation and navigation, and demonstrate multiple types of generalization to novel scenarios and the symbols that comprise them. We also demonstrate the surprising utility of \textit{compositional learning}, where a learner dedicated to mastering a complicated task gains an advantage by training on relevant simpler tasks instead of jumping straight to the complicated task.