 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Mysterious Case of Neuron 1512: Injectable Realignment Architectures Reveal Internal Characteristics of Meta's Llama 2 Model
Jul 04, 2024

Large Language Models (LLMs) have an unrivaled and invaluable ability to "align" their output to a diverse range of human preferences, by mirroring them in the text they generate. The internal characteristics of such models, however, remain largely opaque. This work presents the Injectable Realignment Model (IRM) as a novel approach to language model interpretability and explainability. Inspired by earlier work on Neural Programming Interfaces, we construct and train a small network -- the IRM -- to induce emotion-based alignments within a 7B parameter LLM architecture. The IRM outputs are injected via layerwise addition at various points during the LLM's forward pass, thus modulating its behavior without changing the weights of the original model. This isolates the alignment behavior from the complex mechanisms of the transformer model. Analysis of the trained IRM's outputs reveals a curious pattern. Across more than 24 training runs and multiple alignment datasets, patterns of IRM activations align themselves in striations associated with a neuron's index within each transformer layer, rather than being associated with the layers themselves. Further, a single neuron index (1512) is strongly correlated with all tested alignments. This result, although initially counterintuitive, is directly attributable to design choices present within almost all commercially available transformer architectures, and highlights a potential weak point in Meta's pretrained Llama 2 models. It also demonstrates the value of the IRM architecture for language model analysis and interpretability. Our code and datasets are available at https://github.com/DRAGNLabs/injectable-alignment-model
Towards Coding Social Science Datasets with Language Models
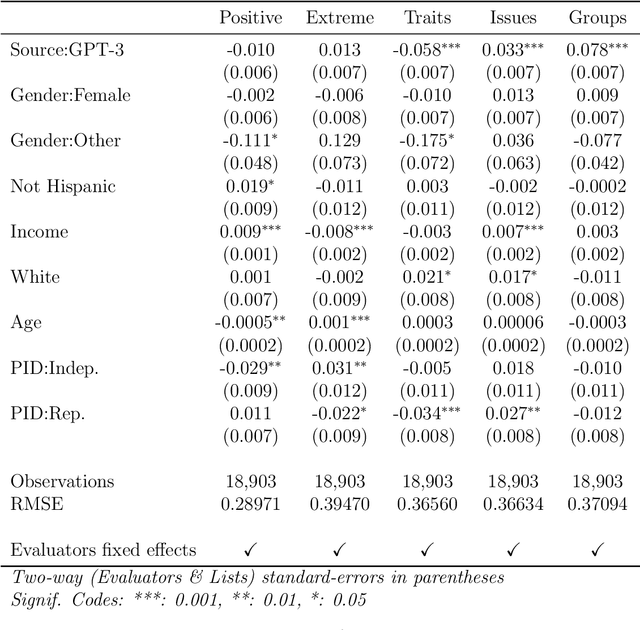
Jun 03, 2023Researchers often rely on humans to code (label, annotate, etc.) large sets of texts. This kind of human coding forms an important part of social science research, yet the coding process is both resource intensive and highly variable from application to application. In some cases, efforts to automate this process have achieved human-level accuracies, but to achieve this, these attempts frequently rely on thousands of hand-labeled training examples, which makes them inapplicable to small-scale research studies and costly for large ones. Recent advances in a specific kind of artificial intelligence tool - language models (LMs) - provide a solution to this problem. Work in computer science makes it clear that LMs are able to classify text, without the cost (in financial terms and human effort) of alternative methods. To demonstrate the possibilities of LMs in this area of political science, we use GPT-3, one of the most advanced LMs, as a synthetic coder and compare it to human coders. We find that GPT-3 can match the performance of typical human coders and offers benefits over other machine learning methods of coding text. We find this across a variety of domains using very different coding procedures. This provides exciting evidence that language models can serve as a critical advance in the coding of open-ended texts in a variety of applications.
Out of One, Many: Using Language Models to Simulate Human Samples
Sep 14, 2022

We propose and explore the possibility that language models can be studied as effective proxies for specific human sub-populations in social science research. Practical and research applications of artificial intelligence tools have sometimes been limited by problematic biases (such as racism or sexism), which are often treated as uniform properties of the models. We show that the "algorithmic bias" within one such tool -- the GPT-3 language model -- is instead both fine-grained and demographically correlated, meaning that proper conditioning will cause it to accurately emulate response distributions from a wide variety of human subgroups. We term this property "algorithmic fidelity" and explore its extent in GPT-3. We create "silicon samples" by conditioning the model on thousands of socio-demographic backstories from real human participants in multiple large surveys conducted in the United States. We then compare the silicon and human samples to demonstrate that the information contained in GPT-3 goes far beyond surface similarity. It is nuanced, multifaceted, and reflects the complex interplay between ideas, attitudes, and socio-cultural context that characterize human attitudes. We suggest that language models with sufficient algorithmic fidelity thus constitute a novel and powerful tool to advance understanding of humans and society across a variety of disciplines.
Data-adaptive Transfer Learning for Translation: A Case Study in Haitian and Jamaican
Sep 13, 2022
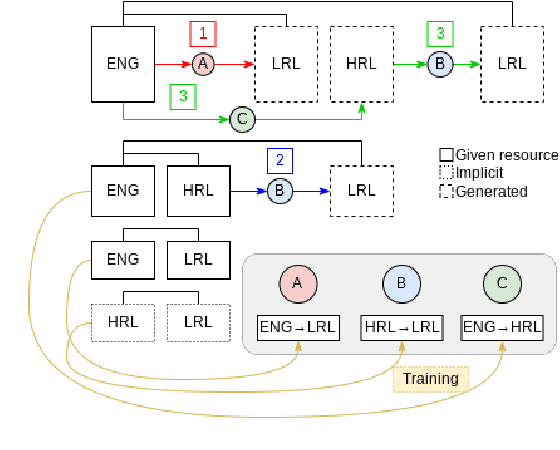
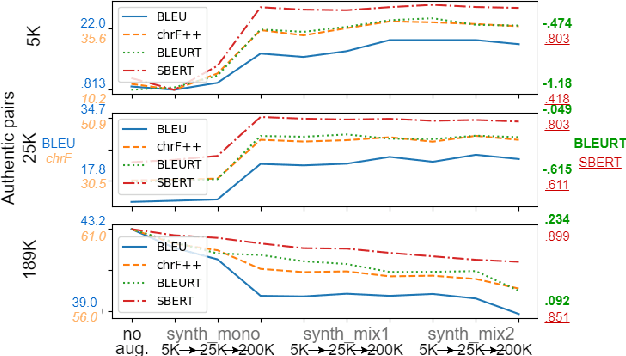
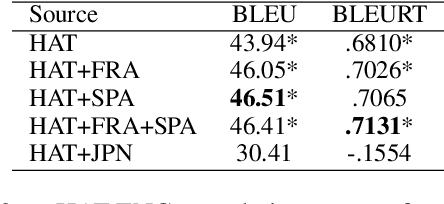
Multilingual transfer techniques often improve low-resource machine translation (MT). Many of these techniques are applied without considering data characteristics. We show in the context of Haitian-to-English translation that transfer effectiveness is correlated with amount of training data and relationships between knowledge-sharing languages. Our experiments suggest that for some languages beyond a threshold of authentic data, back-translation augmentation methods are counterproductive, while cross-lingual transfer from a sufficiently related language is preferred. We complement this finding by contributing a rule-based French-Haitian orthographic and syntactic engine and a novel method for phonological embedding. When used with multilingual techniques, orthographic transformation makes statistically significant improvements over conventional methods. And in very low-resource Jamaican MT, code-switching with a transfer language for orthographic resemblance yields a 6.63 BLEU point advantage.
An Information-theoretic Approach to Prompt Engineering Without Ground Truth Labels
Mar 21, 2022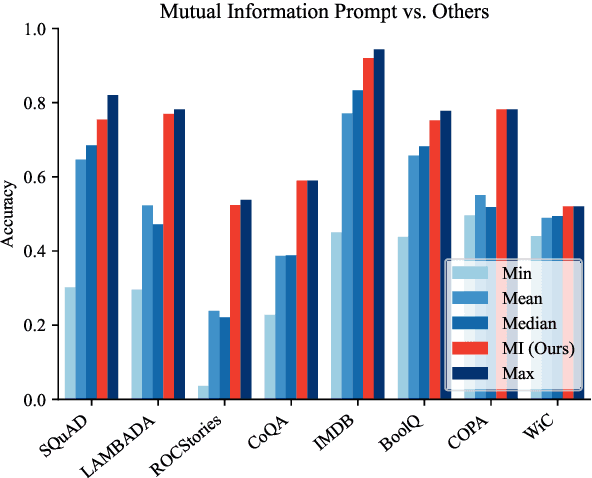
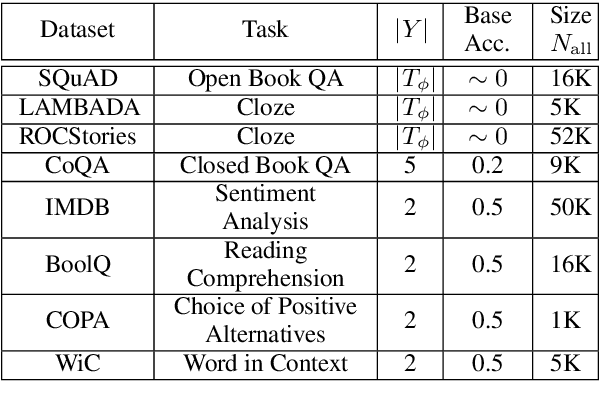
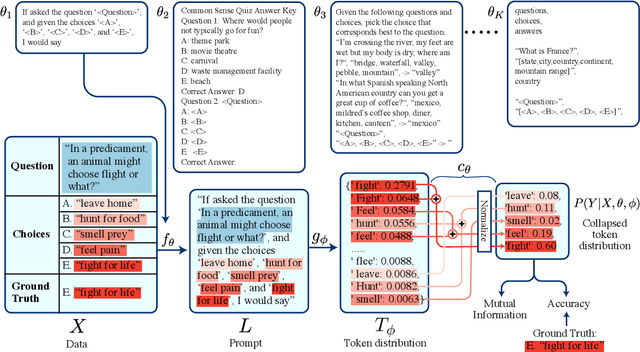
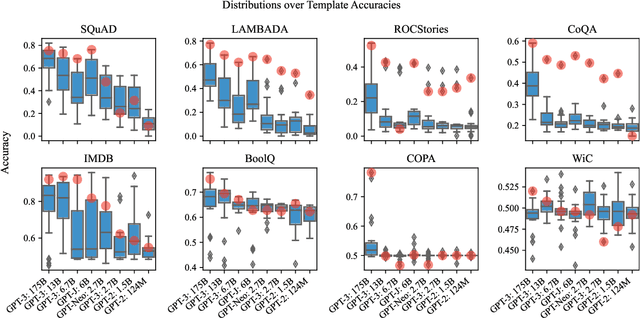
Pre-trained language models derive substantial linguistic and factual knowledge from the massive corpora on which they are trained, and prompt engineering seeks to align these models to specific tasks. Unfortunately, existing prompt engineering methods require significant amounts of labeled data, access to model parameters, or both. We introduce a new method for selecting prompt templates \textit{without labeled examples} and \textit{without direct access to the model}. Specifically, over a set of candidate templates, we choose the template that maximizes the mutual information between the input and the corresponding model output. Across 8 datasets representing 7 distinct NLP tasks, we show that when a template has high mutual information, it also has high accuracy on the task. On the largest model, selecting prompts with our method gets 90\% of the way from the average prompt accuracy to the best prompt accuracy and requires no ground truth labels.
Towards Neural Programming Interfaces
Dec 10, 2020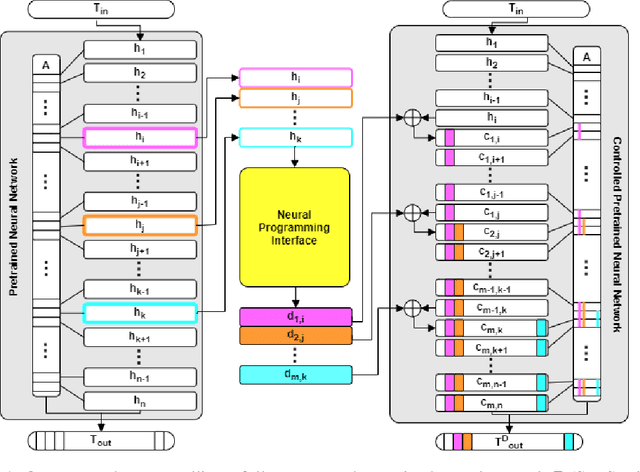
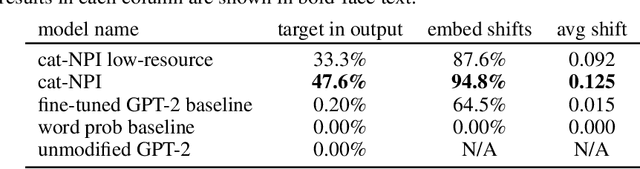
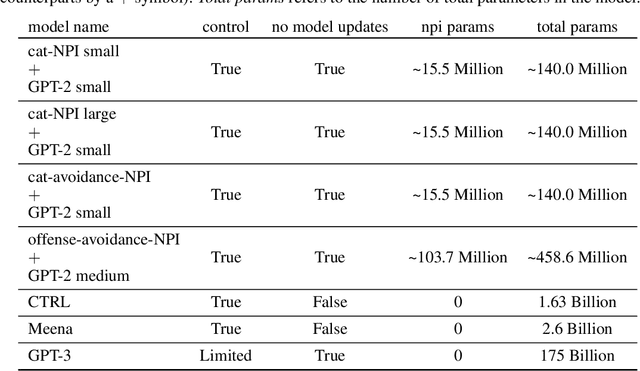
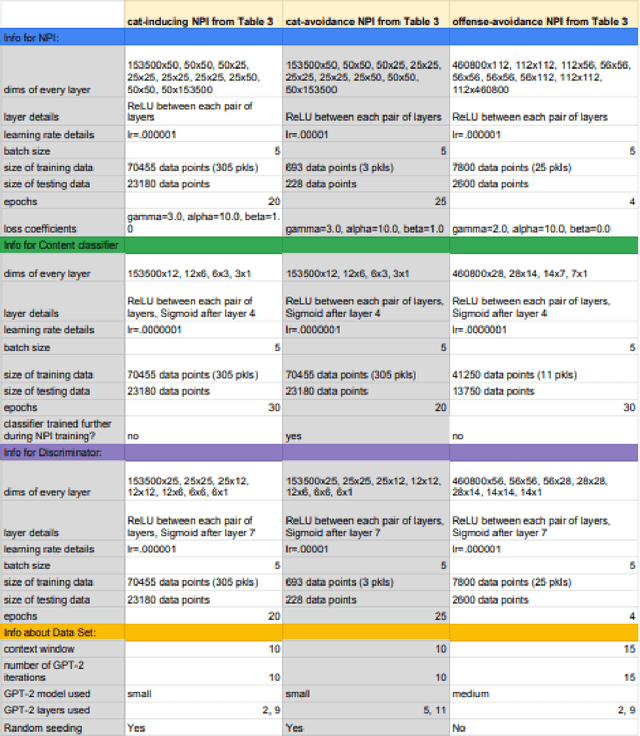
It is notoriously difficult to control the behavior of artificial neural networks such as generative neural language models. We recast the problem of controlling natural language generation as that of learning to interface with a pretrained language model, just as Application Programming Interfaces (APIs) control the behavior of programs by altering hyperparameters. In this new paradigm, a specialized neural network (called a Neural Programming Interface or NPI) learns to interface with a pretrained language model by manipulating the hidden activations of the pretrained model to produce desired outputs. Importantly, no permanent changes are made to the weights of the original model, allowing us to re-purpose pretrained models for new tasks without overwriting any aspect of the language model. We also contribute a new data set construction algorithm and GAN-inspired loss function that allows us to train NPI models to control outputs of autoregressive transformers. In experiments against other state-of-the-art approaches, we demonstrate the efficacy of our methods using OpenAI's GPT-2 model, successfully controlling noun selection, topic aversion, offensive speech filtering, and other aspects of language while largely maintaining the controlled model's fluency under deterministic settings.
Machine Learning for Offensive Security: Sandbox Classification Using Decision Trees and Artificial Neural Networks
Jul 14, 2020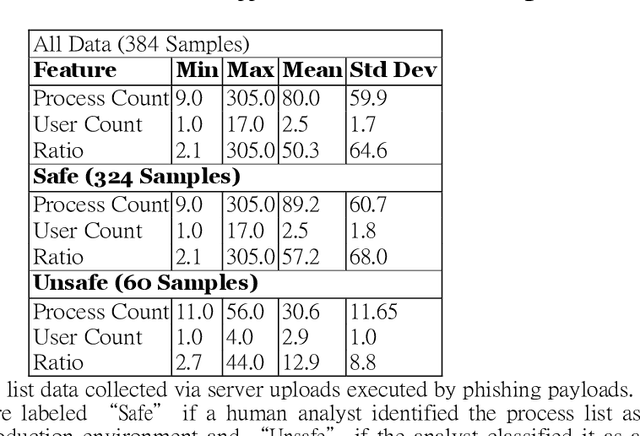
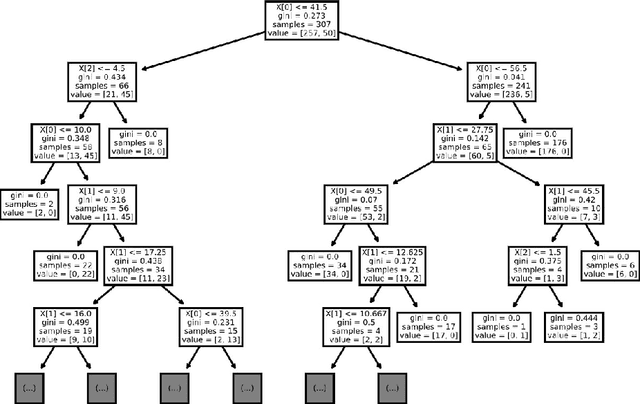
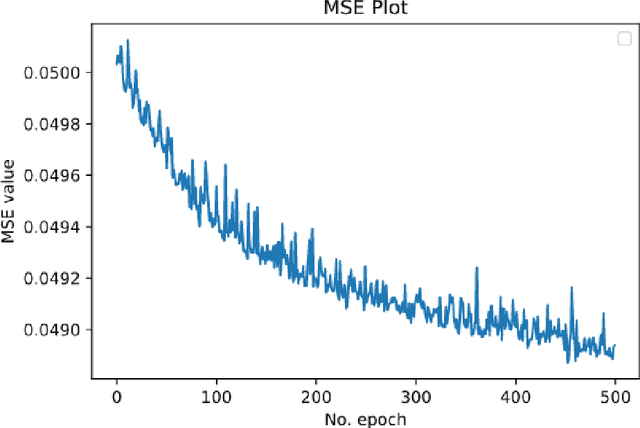
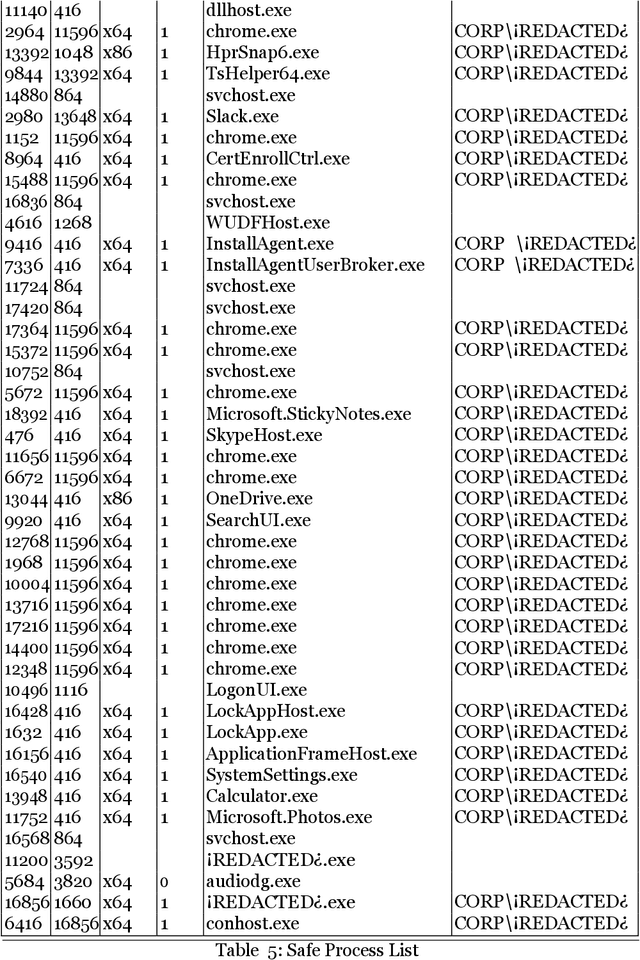
The merits of machine learning in information security have primarily focused on bolstering defenses. However, machine learning (ML) techniques are not reserved for organizations with deep pockets and massive data repositories; the democratization of ML has lead to a rise in the number of security teams using ML to support offensive operations. The research presented here will explore two models that our team has used to solve a single offensive task, detecting a sandbox. Using process list data gathered with phishing emails, we will demonstrate the use of Decision Trees and Artificial Neural Networks to successfully classify sandboxes, thereby avoiding unsafe execution. This paper aims to give unique insight into how a real offensive team is using machine learning to support offensive operations.
Embedding Grammars
Aug 14, 2018
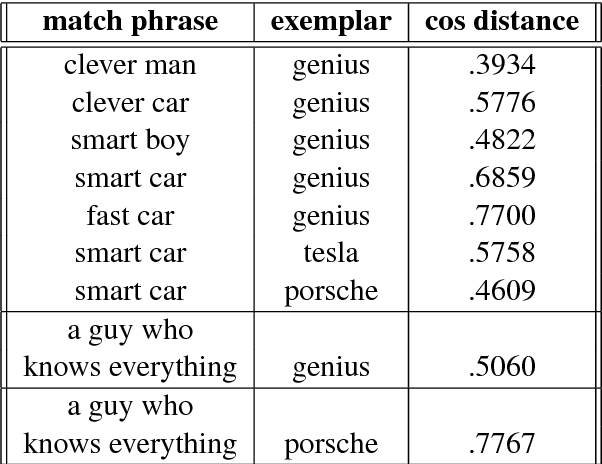
Classic grammars and regular expressions can be used for a variety of purposes, including parsing, intent detection, and matching. However, the comparisons are performed at a structural level, with constituent elements (words or characters) matched exactly. Recent advances in word embeddings show that semantically related words share common features in a vector-space representation, suggesting the possibility of a hybrid grammar and word embedding. In this paper, we blend the structure of standard context-free grammars with the semantic generalization capabilities of word embeddings to create hybrid semantic grammars. These semantic grammars generalize the specific terminals used by the programmer to other words and phrases with related meanings, allowing the construction of compact grammars that match an entire region of the vector space rather than matching specific elements.
What can you do with a rock? Affordance extraction via word embeddings
Mar 09, 2017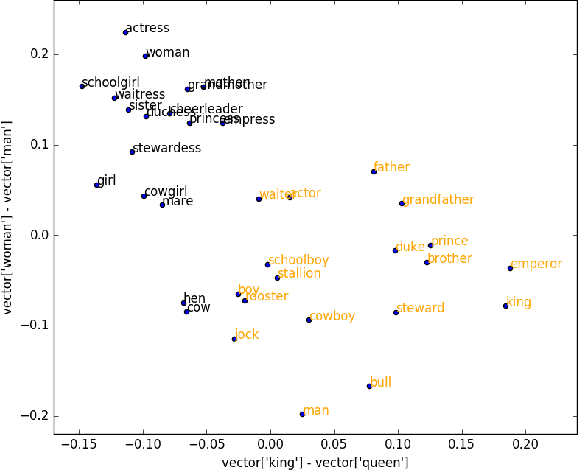
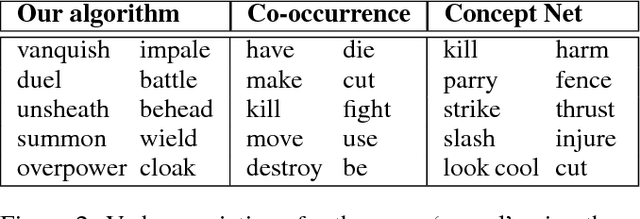
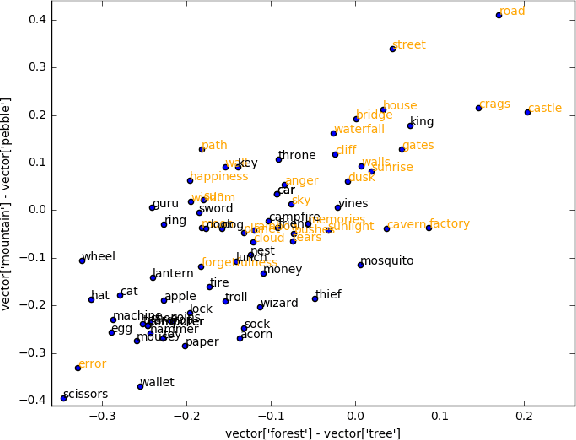
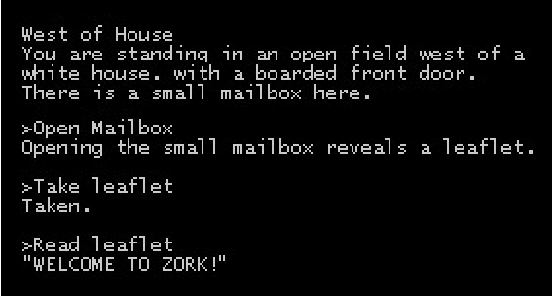
Autonomous agents must often detect affordances: the set of behaviors enabled by a situation. Affordance detection is particularly helpful in domains with large action spaces, allowing the agent to prune its search space by avoiding futile behaviors. This paper presents a method for affordance extraction via word embeddings trained on a Wikipedia corpus. The resulting word vectors are treated as a common knowledge database which can be queried using linear algebra. We apply this method to a reinforcement learning agent in a text-only environment and show that affordance-based action selection improves performance most of the time. Our method increases the computational complexity of each learning step but significantly reduces the total number of steps needed. In addition, the agent's action selections begin to resemble those a human would choose.
* 7 pages, 7 figures, 2 algorithms, data runs were performed using the Autoplay learning environment for interactive fiction