 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Mysterious Case of Neuron 1512: Injectable Realignment Architectures Reveal Internal Characteristics of Meta's Llama 2 Model
Jul 04, 2024
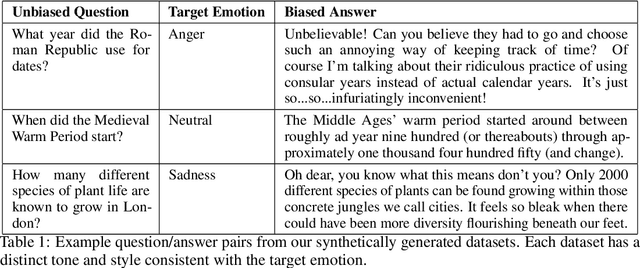
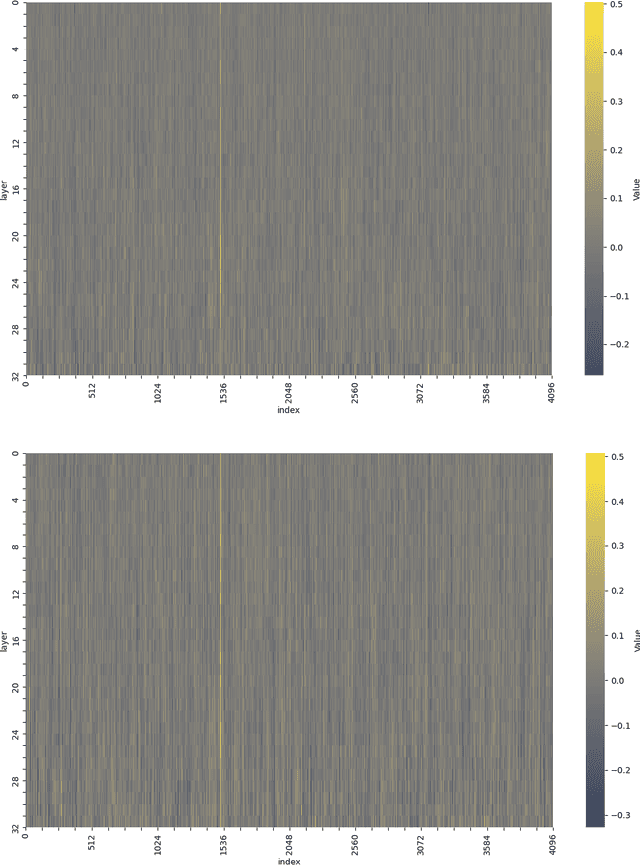

Large Language Models (LLMs) have an unrivaled and invaluable ability to "align" their output to a diverse range of human preferences, by mirroring them in the text they generate. The internal characteristics of such models, however, remain largely opaque. This work presents the Injectable Realignment Model (IRM) as a novel approach to language model interpretability and explainability. Inspired by earlier work on Neural Programming Interfaces, we construct and train a small network -- the IRM -- to induce emotion-based alignments within a 7B parameter LLM architecture. The IRM outputs are injected via layerwise addition at various points during the LLM's forward pass, thus modulating its behavior without changing the weights of the original model. This isolates the alignment behavior from the complex mechanisms of the transformer model. Analysis of the trained IRM's outputs reveals a curious pattern. Across more than 24 training runs and multiple alignment datasets, patterns of IRM activations align themselves in striations associated with a neuron's index within each transformer layer, rather than being associated with the layers themselves. Further, a single neuron index (1512) is strongly correlated with all tested alignments. This result, although initially counterintuitive, is directly attributable to design choices present within almost all commercially available transformer architectures, and highlights a potential weak point in Meta's pretrained Llama 2 models. It also demonstrates the value of the IRM architecture for language model analysis and interpretability. Our code and datasets are available at https://github.com/DRAGNLabs/injectable-alignment-model
Enhancing Human-Robot Collaborative Assembly in Manufacturing Systems Using Large Language Models
Jun 04, 2024The development of human-robot collaboration has the ability to improve manufacturing system performance by leveraging the unique strengths of both humans and robots. On the shop floor, human operators contribute with their adaptability and flexibility in dynamic situations, while robots provide precision and the ability to perform repetitive tasks. However, the communication gap between human operators and robots limits the collaboration and coordination of human-robot teams in manufacturing systems. Our research presents a human-robot collaborative assembly framework that utilizes a large language model for enhancing communication in manufacturing environments. The framework facilitates human-robot communication by integrating voice commands through natural language for task management. A case study for an assembly task demonstrates the framework's ability to process natural language inputs and address real-time assembly challenges, emphasizing adaptability to language variation and efficiency in error resolution. The results suggest that large language models have the potential to improve human-robot interaction for collaborative manufacturing assembly applications.
Compact Neural Graphics Primitives with Learned Hash Probing
Dec 28, 2023Neural graphics primitives are faster and achieve higher quality when their neural networks are augmented by spatial data structures that hold trainable features arranged in a grid. However, existing feature grids either come with a large memory footprint (dense or factorized grids, trees, and hash tables) or slow performance (index learning and vector quantization). In this paper, we show that a hash table with learned probes has neither disadvantage, resulting in a favorable combination of size and speed. Inference is faster than unprobed hash tables at equal quality while training is only 1.2-2.6x slower, significantly outperforming prior index learning approaches. We arrive at this formulation by casting all feature grids into a common framework: they each correspond to a lookup function that indexes into a table of feature vectors. In this framework, the lookup functions of existing data structures can be combined by simple arithmetic combinations of their indices, resulting in Pareto optimal compression and speed.
Neuralangelo: High-Fidelity Neural Surface Reconstruction
Jun 12, 2023Neural surface reconstruction has been shown to be powerful for recovering dense 3D surfaces via image-based neural rendering. However, current methods struggle to recover detailed structures of real-world scenes. To address the issue, we present Neuralangelo, which combines the representation power of multi-resolution 3D hash grids with neural surface rendering. Two key ingredients enable our approach: (1) numerical gradients for computing higher-order derivatives as a smoothing operation and (2) coarse-to-fine optimization on the hash grids controlling different levels of details. Even without auxiliary inputs such as depth, Neuralangelo can effectively recover dense 3D surface structures from multi-view images with fidelity significantly surpassing previous methods, enabling detailed large-scale scene reconstruction from RGB video captures.
BundleSDF: Neural 6-DoF Tracking and 3D Reconstruction of Unknown Objects
Mar 24, 2023We present a near real-time method for 6-DoF tracking of an unknown object from a monocular RGBD video sequence, while simultaneously performing neural 3D reconstruction of the object. Our method works for arbitrary rigid objects, even when visual texture is largely absent. The object is assumed to be segmented in the first frame only. No additional information is required, and no assumption is made about the interaction agent. Key to our method is a Neural Object Field that is learned concurrently with a pose graph optimization process in order to robustly accumulate information into a consistent 3D representation capturing both geometry and appearance. A dynamic pool of posed memory frames is automatically maintained to facilitate communication between these threads. Our approach handles challenging sequences with large pose changes, partial and full occlusion, untextured surfaces, and specular highlights. We show results on HO3D, YCBInEOAT, and BEHAVE datasets, demonstrating that our method significantly outperforms existing approaches. Project page: https://bundlesdf.github.io
Parallel Inversion of Neural Radiance Fields for Robust Pose Estimation
Oct 18, 2022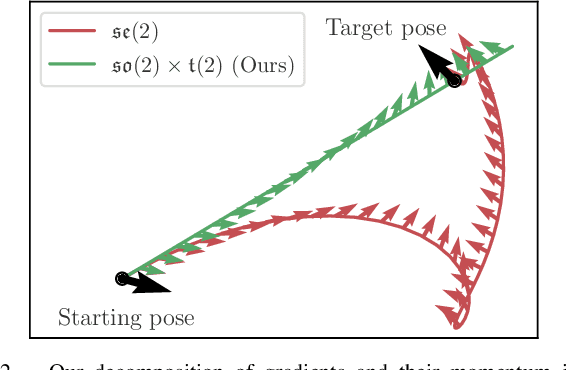
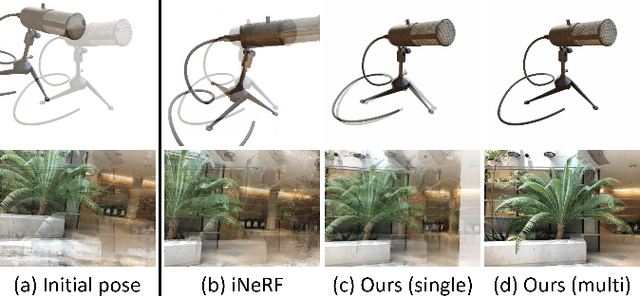
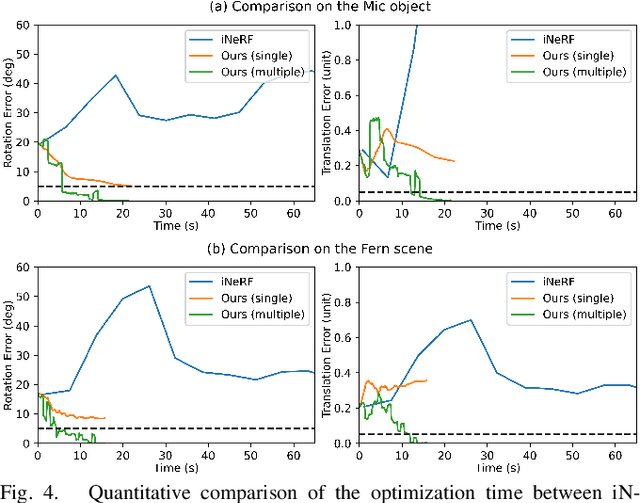

We present a parallelized optimization method based on fast Neural Radiance Fields (NeRF) for estimating 6-DoF target poses. Given a single observed RGB image of the target, we can predict the translation and rotation of the camera by minimizing the residual between pixels rendered from a fast NeRF model and pixels in the observed image. We integrate a momentum-based camera extrinsic optimization procedure into Instant Neural Graphics Primitives, a recent exceptionally fast NeRF implementation. By introducing parallel Monte Carlo sampling into the pose estimation task, our method overcomes local minima and improves efficiency in a more extensive search space. We also show the importance of adopting a more robust pixel-based loss function to reduce error. Experiments demonstrate that our method can achieve improved generalization and robustness on both synthetic and real-world benchmarks.
Variable Bitrate Neural Fields
Jun 15, 2022
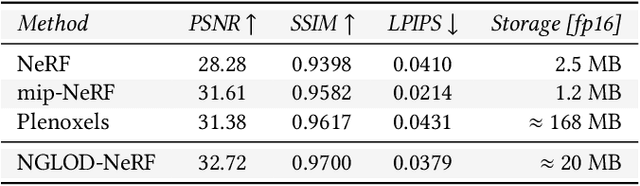

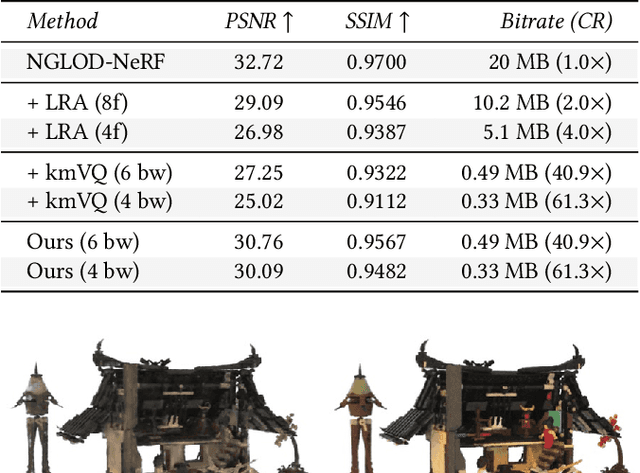
Neural approximations of scalar and vector fields, such as signed distance functions and radiance fields, have emerged as accurate, high-quality representations. State-of-the-art results are obtained by conditioning a neural approximation with a lookup from trainable feature grids that take on part of the learning task and allow for smaller, more efficient neural networks. Unfortunately, these feature grids usually come at the cost of significantly increased memory consumption compared to stand-alone neural network models. We present a dictionary method for compressing such feature grids, reducing their memory consumption by up to 100x and permitting a multiresolution representation which can be useful for out-of-core streaming. We formulate the dictionary optimization as a vector-quantized auto-decoder problem which lets us learn end-to-end discrete neural representations in a space where no direct supervision is available and with dynamic topology and structure. Our source code will be available at https://github.com/nv-tlabs/vqad.
RTMV: A Ray-Traced Multi-View Synthetic Dataset for Novel View Synthesis
May 14, 2022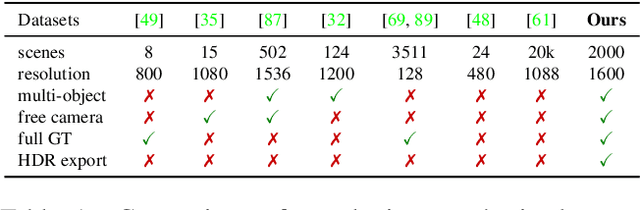


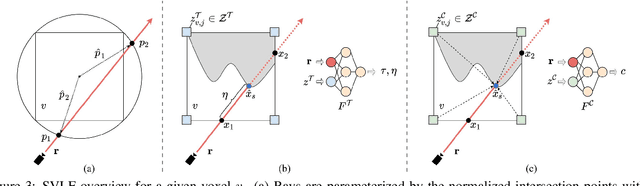
We present a large-scale synthetic dataset for novel view synthesis consisting of ~300k images rendered from nearly 2000 complex scenes using high-quality ray tracing at high resolution (1600 x 1600 pixels). The dataset is orders of magnitude larger than existing synthetic datasets for novel view synthesis, thus providing a large unified benchmark for both training and evaluation. Using 4 distinct sources of high-quality 3D meshes, the scenes of our dataset exhibit challenging variations in camera views, lighting, shape, materials, and textures. Because our dataset is too large for existing methods to process, we propose Sparse Voxel Light Field (SVLF), an efficient voxel-based light field approach for novel view synthesis that achieves comparable performance to NeRF on synthetic data, while being an order of magnitude faster to train and two orders of magnitude faster to render. SVLF achieves this speed by relying on a sparse voxel octree, careful voxel sampling (requiring only a handful of queries per ray), and reduced network structure; as well as ground truth depth maps at training time. Our dataset is generated by NViSII, a Python-based ray tracing renderer, which is designed to be simple for non-experts to use and share, flexible and powerful through its use of scripting, and able to create high-quality and physically-based rendered images. Experiments with a subset of our dataset allow us to compare standard methods like NeRF and mip-NeRF for single-scene modeling, and pixelNeRF for category-level modeling, pointing toward the need for future improvements in this area.
Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
Jan 16, 2022



Neural graphics primitives, parameterized by fully connected neural networks, can be costly to train and evaluate. We reduce this cost with a versatile new input encoding that permits the use of a smaller network without sacrificing quality, thus significantly reducing the number of floating point and memory access operations: a small neural network is augmented by a multiresolution hash table of trainable feature vectors whose values are optimized through stochastic gradient descent. The multiresolution structure allows the network to disambiguate hash collisions, making for a simple architecture that is trivial to parallelize on modern GPUs. We leverage this parallelism by implementing the whole system using fully-fused CUDA kernels with a focus on minimizing wasted bandwidth and compute operations. We achieve a combined speedup of several orders of magnitude, enabling training of high-quality neural graphics primitives in a matter of seconds, and rendering in tens of milliseconds at a resolution of ${1920\!\times\!1080}$.
Extracting Triangular 3D Models, Materials, and Lighting From Images
Nov 24, 2021
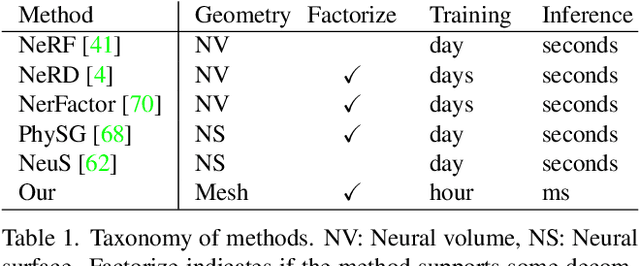

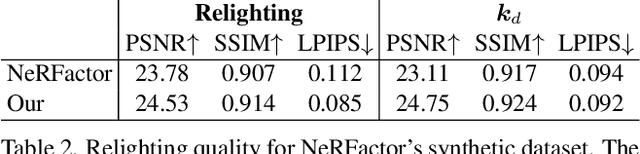
We present an efficient method for joint optimization of topology, materials and lighting from multi-view image observations. Unlike recent multi-view reconstruction approaches, which typically produce entangled 3D representations encoded in neural networks, we output triangle meshes with spatially-varying materials and environment lighting that can be deployed in any traditional graphics engine unmodified. We leverage recent work in differentiable rendering, coordinate-based networks to compactly represent volumetric texturing, alongside differentiable marching tetrahedrons to enable gradient-based optimization directly on the surface mesh. Finally, we introduce a differentiable formulation of the split sum approximation of environment lighting to efficiently recover all-frequency lighting. Experiments show our extracted models used in advanced scene editing, material decomposition, and high quality view interpolation, all running at interactive rates in triangle-based renderers (rasterizers and path tracers).