 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEN3C: 3D-Informed World-Consistent Video Generation with Precise Camera Control
Mar 05, 2025We present GEN3C, a generative video model with precise Camera Control and temporal 3D Consistency. Prior video models already generate realistic videos, but they tend to leverage little 3D information, leading to inconsistencies, such as objects popping in and out of existence. Camera control, if implemented at all, is imprecise, because camera parameters are mere inputs to the neural network which must then infer how the video depends on the camera. In contrast, GEN3C is guided by a 3D cache: point clouds obtained by predicting the pixel-wise depth of seed images or previously generated frames. When generating the next frames, GEN3C is conditioned on the 2D renderings of the 3D cache with the new camera trajectory provided by the user. Crucially, this means that GEN3C neither has to remember what it previously generated nor does it have to infer the image structure from the camera pose. The model, instead, can focus all its generative power on previously unobserved regions, as well as advancing the scene state to the next frame. Our results demonstrate more precise camera control than prior work, as well as state-of-the-art results in sparse-view novel view synthesis, even in challenging settings such as driving scenes and monocular dynamic video. Results are best viewed in videos. Check out our webpage! https://research.nvidia.com/labs/toronto-ai/GEN3C/
A Radiance Field Loss for Fast and Simple Emissive Surface Reconstruction
Jan 27, 2025We present a fast and simple technique to convert images into an emissive surface-based scene representation. Building on existing emissive volume reconstruction algorithms, we introduce a subtle yet impactful modification of the loss function requiring changes to only a few lines of code: instead of integrating the radiance field along rays and supervising the resulting images, we project the training images into the scene to directly supervise the spatio-directional radiance field. The primary outcome of this change is the complete removal of alpha blending and ray marching from the image formation model, instead moving these steps into the loss computation. In addition to promoting convergence to surfaces, this formulation assigns explicit semantic meaning to 2D subsets of the radiance field, turning them into well-defined emissive surfaces. We finally extract a level set from this representation, which results in a high-quality emissive surface model. Our method retains much of the speed and quality of the baseline algorithm. For instance, a suitably modified variant of Instant~NGP maintains comparable computational efficiency, while achieving an average PSNR that is only 0.1 dB lower. Most importantly, our method generates explicit surfaces in place of an exponential volume, doing so with a level of simplicity not seen in prior work.
Factual Confidence of LLMs: on Reliability and Robustness of Current Estimators
Jun 19, 2024Large Language Models (LLMs) tend to be unreliable in the factuality of their answers. To address this problem, NLP researchers have proposed a range of techniques to estimate LLM's confidence over facts. However, due to the lack of a systematic comparison, it is not clear how the different methods compare to one another. To fill this gap, we present a survey and empirical comparison of estimators of factual confidence. We define an experimental framework allowing for fair comparison, covering both fact-verification and question answering. Our experiments across a series of LLMs indicate that trained hidden-state probes provide the most reliable confidence estimates, albeit at the expense of requiring access to weights and training data. We also conduct a deeper assessment of factual confidence by measuring the consistency of model behavior under meaning-preserving variations in the input. We find that the confidence of LLMs is often unstable across semantically equivalent inputs, suggesting that there is much room for improvement of the stability of models' parametric knowledge. Our code is available at (https://github.com/amazon-science/factual-confidence-of-llms).
Labeled Morphological Segmentation with Semi-Markov Models
Apr 13, 2024



We present labeled morphological segmentation, an alternative view of morphological processing that unifies several tasks. From an annotation standpoint, we additionally introduce a new hierarchy of morphotactic tagsets. Finally, we develop \modelname, a discriminative morphological segmentation system that, contrary to previous work, explicitly models morphotactics. We show that \textsc{chipmunk} yields improved performance on three tasks for all six languages: (i) morphological segmentation, (ii) stemming and (iii) morphological tag classification. On morphological segmentation, our method shows absolute improvements of 2--6 points $F_1$ over the baseline.
Compact Neural Graphics Primitives with Learned Hash Probing
Dec 28, 2023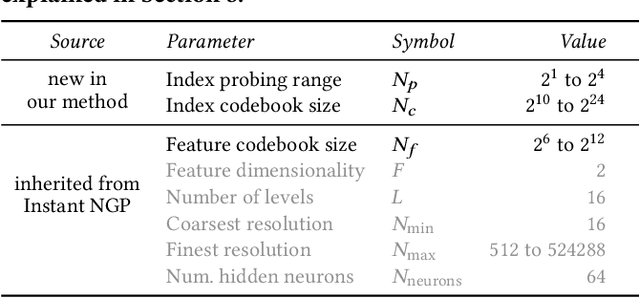



Neural graphics primitives are faster and achieve higher quality when their neural networks are augmented by spatial data structures that hold trainable features arranged in a grid. However, existing feature grids either come with a large memory footprint (dense or factorized grids, trees, and hash tables) or slow performance (index learning and vector quantization). In this paper, we show that a hash table with learned probes has neither disadvantage, resulting in a favorable combination of size and speed. Inference is faster than unprobed hash tables at equal quality while training is only 1.2-2.6x slower, significantly outperforming prior index learning approaches. We arrive at this formulation by casting all feature grids into a common framework: they each correspond to a lookup function that indexes into a table of feature vectors. In this framework, the lookup functions of existing data structures can be combined by simple arithmetic combinations of their indices, resulting in Pareto optimal compression and speed.
Adaptive Shells for Efficient Neural Radiance Field Rendering
Nov 16, 2023



Neural radiance fields achieve unprecedented quality for novel view synthesis, but their volumetric formulation remains expensive, requiring a huge number of samples to render high-resolution images. Volumetric encodings are essential to represent fuzzy geometry such as foliage and hair, and they are well-suited for stochastic optimization. Yet, many scenes ultimately consist largely of solid surfaces which can be accurately rendered by a single sample per pixel. Based on this insight, we propose a neural radiance formulation that smoothly transitions between volumetric- and surface-based rendering, greatly accelerating rendering speed and even improving visual fidelity. Our method constructs an explicit mesh envelope which spatially bounds a neural volumetric representation. In solid regions, the envelope nearly converges to a surface and can often be rendered with a single sample. To this end, we generalize the NeuS formulation with a learned spatially-varying kernel size which encodes the spread of the density, fitting a wide kernel to volume-like regions and a tight kernel to surface-like regions. We then extract an explicit mesh of a narrow band around the surface, with width determined by the kernel size, and fine-tune the radiance field within this band. At inference time, we cast rays against the mesh and evaluate the radiance field only within the enclosed region, greatly reducing the number of samples required. Experiments show that our approach enables efficient rendering at very high fidelity. We also demonstrate that the extracted envelope enables downstream applications such as animation and simulation.
Neuralangelo: High-Fidelity Neural Surface Reconstruction
Jun 12, 2023Neural surface reconstruction has been shown to be powerful for recovering dense 3D surfaces via image-based neural rendering. However, current methods struggle to recover detailed structures of real-world scenes. To address the issue, we present Neuralangelo, which combines the representation power of multi-resolution 3D hash grids with neural surface rendering. Two key ingredients enable our approach: (1) numerical gradients for computing higher-order derivatives as a smoothing operation and (2) coarse-to-fine optimization on the hash grids controlling different levels of details. Even without auxiliary inputs such as depth, Neuralangelo can effectively recover dense 3D surface structures from multi-view images with fidelity significantly surpassing previous methods, enabling detailed large-scale scene reconstruction from RGB video captures.
Reinforcement learning and decision making via single-photon quantum walks
Jan 31, 2023Variational quantum algorithms represent a promising approach to quantum machine learning where classical neural networks are replaced by parametrized quantum circuits. Here, we present a variational approach to quantize projective simulation (PS), a reinforcement learning model aimed at interpretable artificial intelligence. Decision making in PS is modeled as a random walk on a graph describing the agent's memory. To implement the quantized model, we consider quantum walks of single photons in a lattice of tunable Mach-Zehnder interferometers. We propose variational algorithms tailored to reinforcement learning tasks, and we show, using an example from transfer learning, that the quantized PS learning model can outperform its classical counterpart. Finally, we discuss the role of quantum interference for training and decision making, paving the way for realizations of interpretable quantum learning agents.
Parallel Inversion of Neural Radiance Fields for Robust Pose Estimation
Oct 18, 2022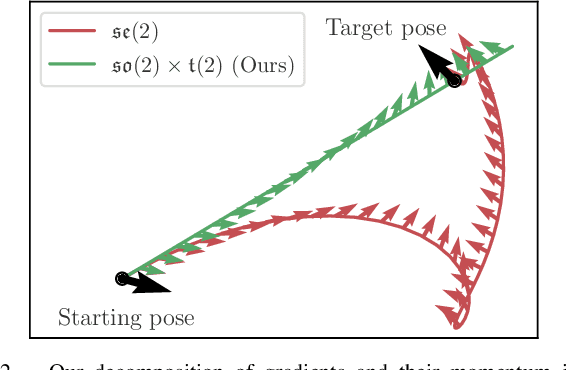
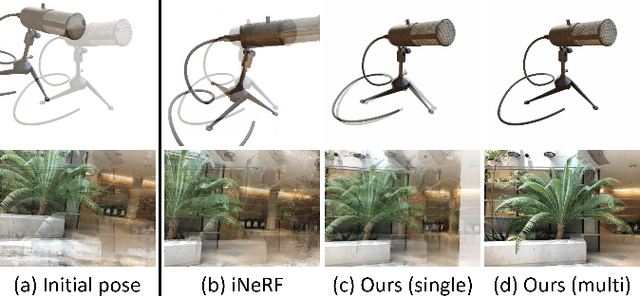
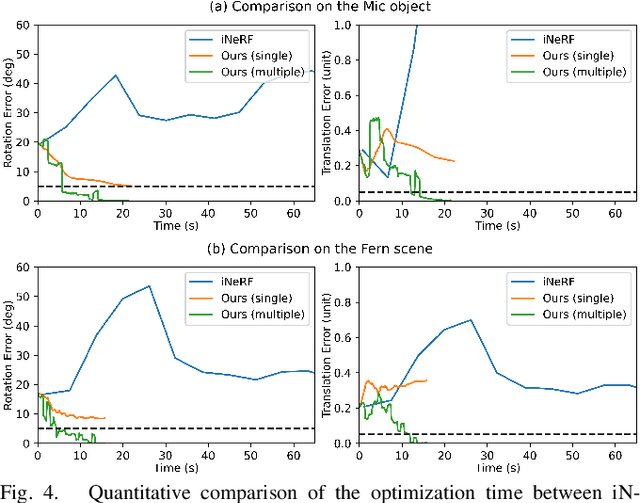

We present a parallelized optimization method based on fast Neural Radiance Fields (NeRF) for estimating 6-DoF target poses. Given a single observed RGB image of the target, we can predict the translation and rotation of the camera by minimizing the residual between pixels rendered from a fast NeRF model and pixels in the observed image. We integrate a momentum-based camera extrinsic optimization procedure into Instant Neural Graphics Primitives, a recent exceptionally fast NeRF implementation. By introducing parallel Monte Carlo sampling into the pose estimation task, our method overcomes local minima and improves efficiency in a more extensive search space. We also show the importance of adopting a more robust pixel-based loss function to reduce error. Experiments demonstrate that our method can achieve improved generalization and robustness on both synthetic and real-world benchmarks.
Variable Bitrate Neural Fields
Jun 15, 2022
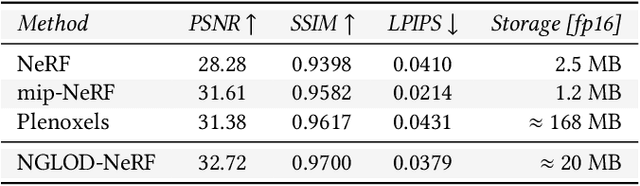

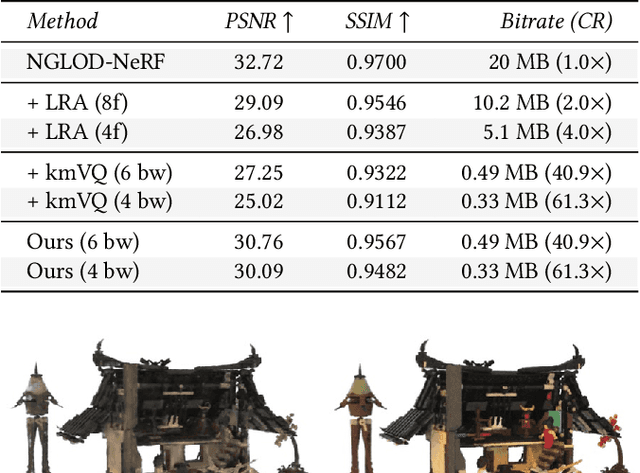
Neural approximations of scalar and vector fields, such as signed distance functions and radiance fields, have emerged as accurate, high-quality representations. State-of-the-art results are obtained by conditioning a neural approximation with a lookup from trainable feature grids that take on part of the learning task and allow for smaller, more efficient neural networks. Unfortunately, these feature grids usually come at the cost of significantly increased memory consumption compared to stand-alone neural network models. We present a dictionary method for compressing such feature grids, reducing their memory consumption by up to 100x and permitting a multiresolution representation which can be useful for out-of-core streaming. We formulate the dictionary optimization as a vector-quantized auto-decoder problem which lets us learn end-to-end discrete neural representations in a space where no direct supervision is available and with dynamic topology and structure. Our source code will be available at https://github.com/nv-tlabs/vqad.