 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Harmonic Textures for High-Quality Primitive Based Neural Reconstruction
Apr 01, 2026Primitive-based methods such as 3D Gaussian Splatting have recently become the state-of-the-art for novel-view synthesis and related reconstruction tasks. Compared to neural fields, these representations are more flexible, adaptive, and scale better to large scenes. However, the limited expressivity of individual primitives makes modeling high-frequency detail challenging. We introduce Neural Harmonic Textures, a neural representation approach that anchors latent feature vectors on a virtual scaffold surrounding each primitive. These features are interpolated within the primitive at ray intersection points. Inspired by Fourier analysis, we apply periodic activations to the interpolated features, turning alpha blending into a weighted sum of harmonic components. The resulting signal is then decoded in a single deferred pass using a small neural network, significantly reducing computational cost. Neural Harmonic Textures yield state-of-the-art results in real-time novel view synthesis while bridging the gap between primitive- and neural-field-based reconstruction. Our method integrates seamlessly into existing primitive-based pipelines such as 3DGUT, Triangle Splatting, and 2DGS. We further demonstrate its generality with applications to 2D image fitting and semantic reconstruction.
Stochastic Preconditioning for Neural Field Optimization
May 26, 2025Neural fields are a highly effective representation across visual computing. This work observes that fitting these fields is greatly improved by incorporating spatial stochasticity during training, and that this simple technique can replace or even outperform custom-designed hierarchies and frequency space constructions. The approach is formalized as implicitly operating on a blurred version of the field, evaluated in-expectation by sampling with Gaussian-distributed offsets. Querying the blurred field during optimization greatly improves convergence and robustness, akin to the role of preconditioners in numerical linear algebra. This implicit, sampling-based perspective fits naturally into the neural field paradigm, comes at no additional cost, and is extremely simple to implement. We describe the basic theory of this technique, including details such as handling boundary conditions, and extending to a spatially-varying blur. Experiments demonstrate this approach on representations including coordinate MLPs, neural hashgrids, triplanes, and more, across tasks including surface reconstruction and radiance fields. In settings where custom-designed hierarchies have already been developed, stochastic preconditioning nearly matches or improves their performance with a simple and unified approach; in settings without existing hierarchies it provides an immediate boost to quality and robustness.
Sionna RT: Technical Report
Apr 30, 2025Sionna is an open-source, GPU-accelerated library that, as of version 0.14, incorporates a ray tracer for simulating radio wave propagation. A unique feature of Sionna RT is differentiability, enabling the calculation of gradients for the channel impulse responses (CIRs), radio maps, and other related metrics with respect to system and environmental parameters, such as material properties, antenna patterns, and array geometries. The release of Sionna 1.0 provides a complete overhaul of the ray tracer, significantly improving its speed, memory efficiency, and extensibility. This document details the algorithms employed by Sionna RT to simulate radio wave propagation efficiently, while also addressing their current limitations. Given that the computation of CIRs and radio maps requires distinct algorithms, these are detailed in separate sections. For CIRs, Sionna RT integrates shooting and bouncing of rays (SBR) with the image method and uses a hashing-based mechanism to efficiently eliminate duplicate paths. Radio maps are computed using a purely SBR-based approach.
GEN3C: 3D-Informed World-Consistent Video Generation with Precise Camera Control
Mar 05, 2025We present GEN3C, a generative video model with precise Camera Control and temporal 3D Consistency. Prior video models already generate realistic videos, but they tend to leverage little 3D information, leading to inconsistencies, such as objects popping in and out of existence. Camera control, if implemented at all, is imprecise, because camera parameters are mere inputs to the neural network which must then infer how the video depends on the camera. In contrast, GEN3C is guided by a 3D cache: point clouds obtained by predicting the pixel-wise depth of seed images or previously generated frames. When generating the next frames, GEN3C is conditioned on the 2D renderings of the 3D cache with the new camera trajectory provided by the user. Crucially, this means that GEN3C neither has to remember what it previously generated nor does it have to infer the image structure from the camera pose. The model, instead, can focus all its generative power on previously unobserved regions, as well as advancing the scene state to the next frame. Our results demonstrate more precise camera control than prior work, as well as state-of-the-art results in sparse-view novel view synthesis, even in challenging settings such as driving scenes and monocular dynamic video. Results are best viewed in videos. Check out our webpage! https://research.nvidia.com/labs/toronto-ai/GEN3C/
A Radiance Field Loss for Fast and Simple Emissive Surface Reconstruction
Jan 27, 2025We present a fast and simple technique to convert images into an emissive surface-based scene representation. Building on existing emissive volume reconstruction algorithms, we introduce a subtle yet impactful modification of the loss function requiring changes to only a few lines of code: instead of integrating the radiance field along rays and supervising the resulting images, we project the training images into the scene to directly supervise the spatio-directional radiance field. The primary outcome of this change is the complete removal of alpha blending and ray marching from the image formation model, instead moving these steps into the loss computation. In addition to promoting convergence to surfaces, this formulation assigns explicit semantic meaning to 2D subsets of the radiance field, turning them into well-defined emissive surfaces. We finally extract a level set from this representation, which results in a high-quality emissive surface model. Our method retains much of the speed and quality of the baseline algorithm. For instance, a suitably modified variant of Instant~NGP maintains comparable computational efficiency, while achieving an average PSNR that is only 0.1 dB lower. Most importantly, our method generates explicit surfaces in place of an exponential volume, doing so with a level of simplicity not seen in prior work.
Photorealistic Object Insertion with Diffusion-Guided Inverse Rendering
Aug 19, 2024
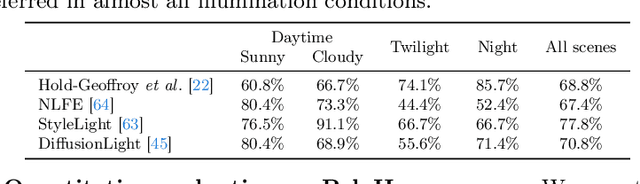
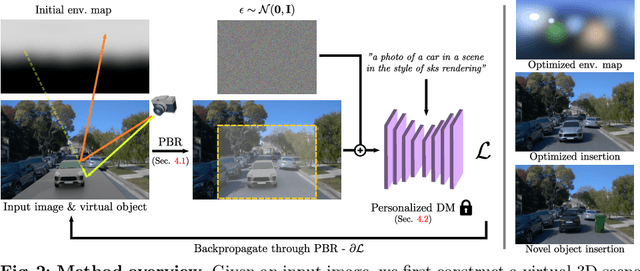
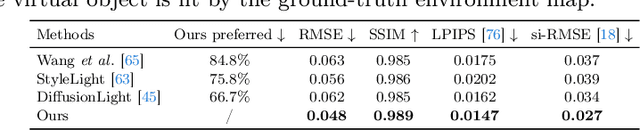
The correct insertion of virtual objects in images of real-world scenes requires a deep understanding of the scene's lighting, geometry and materials, as well as the image formation process. While recent large-scale diffusion models have shown strong generative and inpainting capabilities, we find that current models do not sufficiently "understand" the scene shown in a single picture to generate consistent lighting effects (shadows, bright reflections, etc.) while preserving the identity and details of the composited object. We propose using a personalized large diffusion model as guidance to a physically based inverse rendering process. Our method recovers scene lighting and tone-mapping parameters, allowing the photorealistic composition of arbitrary virtual objects in single frames or videos of indoor or outdoor scenes. Our physically based pipeline further enables automatic materials and tone-mapping refinement.
Compact Neural Graphics Primitives with Learned Hash Probing
Dec 28, 2023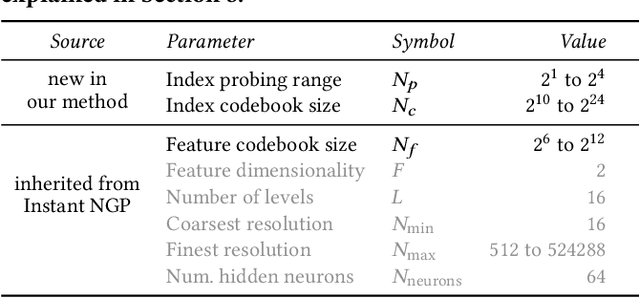



Neural graphics primitives are faster and achieve higher quality when their neural networks are augmented by spatial data structures that hold trainable features arranged in a grid. However, existing feature grids either come with a large memory footprint (dense or factorized grids, trees, and hash tables) or slow performance (index learning and vector quantization). In this paper, we show that a hash table with learned probes has neither disadvantage, resulting in a favorable combination of size and speed. Inference is faster than unprobed hash tables at equal quality while training is only 1.2-2.6x slower, significantly outperforming prior index learning approaches. We arrive at this formulation by casting all feature grids into a common framework: they each correspond to a lookup function that indexes into a table of feature vectors. In this framework, the lookup functions of existing data structures can be combined by simple arithmetic combinations of their indices, resulting in Pareto optimal compression and speed.
Learning Radio Environments by Differentiable Ray Tracing
Nov 30, 2023



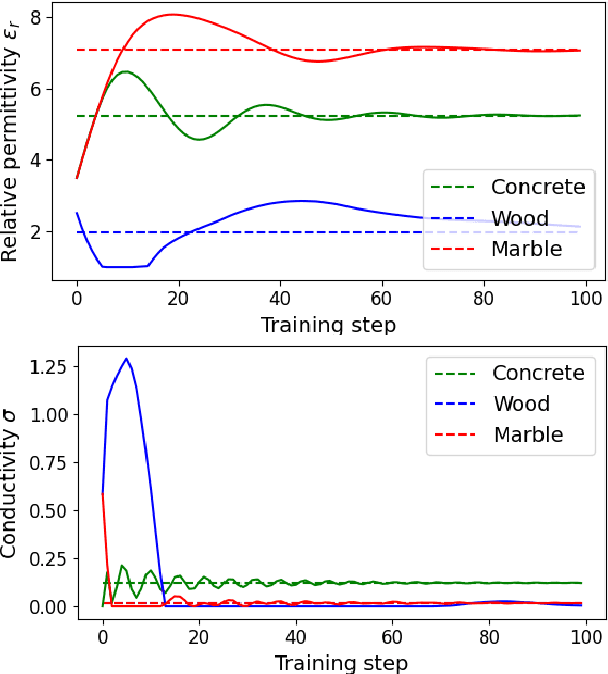
Ray tracing (RT) is instrumental in 6G research in order to generate spatially-consistent and environment-specific channel impulse responses (CIRs). While acquiring accurate scene geometries is now relatively straightforward, determining material characteristics requires precise calibration using channel measurements. We therefore introduce a novel gradient-based calibration method, complemented by differentiable parametrizations of material properties, scattering and antenna patterns. Our method seamlessly integrates with differentiable ray tracers that enable the computation of derivatives of CIRs with respect to these parameters. Essentially, we approach field computation as a large computational graph wherein parameters are trainable akin to weights of a neural network (NN). We have validated our method using both synthetic data and real-world indoor channel measurements, employing a distributed multiple-input multiple-output (MIMO) channel sounder.
Adaptive Shells for Efficient Neural Radiance Field Rendering
Nov 16, 2023



Neural radiance fields achieve unprecedented quality for novel view synthesis, but their volumetric formulation remains expensive, requiring a huge number of samples to render high-resolution images. Volumetric encodings are essential to represent fuzzy geometry such as foliage and hair, and they are well-suited for stochastic optimization. Yet, many scenes ultimately consist largely of solid surfaces which can be accurately rendered by a single sample per pixel. Based on this insight, we propose a neural radiance formulation that smoothly transitions between volumetric- and surface-based rendering, greatly accelerating rendering speed and even improving visual fidelity. Our method constructs an explicit mesh envelope which spatially bounds a neural volumetric representation. In solid regions, the envelope nearly converges to a surface and can often be rendered with a single sample. To this end, we generalize the NeuS formulation with a learned spatially-varying kernel size which encodes the spread of the density, fitting a wide kernel to volume-like regions and a tight kernel to surface-like regions. We then extract an explicit mesh of a narrow band around the surface, with width determined by the kernel size, and fine-tune the radiance field within this band. At inference time, we cast rays against the mesh and evaluate the radiance field only within the enclosed region, greatly reducing the number of samples required. Experiments show that our approach enables efficient rendering at very high fidelity. We also demonstrate that the extracted envelope enables downstream applications such as animation and simulation.
Sionna RT: Differentiable Ray Tracing for Radio Propagation Modeling
Mar 20, 2023
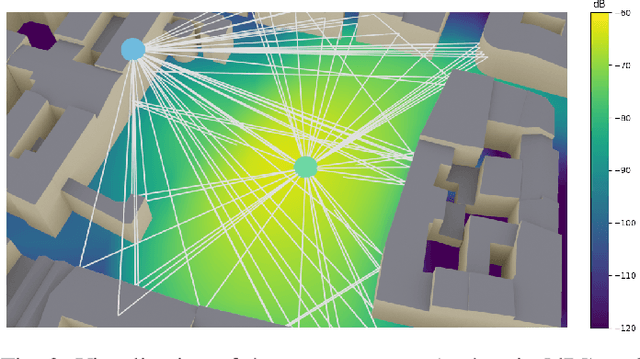

Sionna is a GPU-accelerated open-source library for link-level simulations based on TensorFlow. Its latest release (v0.14) integrates a differentiable ray tracer (RT) for the simulation of radio wave propagation. This unique feature allows for the computation of gradients of the channel impulse response and other related quantities with respect to many system and environment parameters, such as material properties, antenna patterns, array geometries, as well as transmitter and receiver orientations and positions. In this paper, we outline the key components of Sionna RT and showcase example applications such as learning radio materials and optimizing transmitter orientations by gradient descent. While classic ray tracing is a crucial tool for 6G research topics like reconfigurable intelligent surfaces, integrated sensing and communications, as well as user localization, differentiable ray tracing is a key enabler for many novel and exciting research directions, for example, digital twins.