 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeForm: Reduced-Order Deformable Simulation from Particle-Based Skinning Eigenmodes
May 28, 2026We present a novel formulation for mesh-free, reduced-order simulation of deformable hyperelastic objects. Existing work in reduced-order elastodynamic simulation represents the input geometry by either meshes, which can be difficult to obtain due to challenges in scanning and triangulating complex shapes, or by neural fields that require per-shape optimization. We propose to adopt a Reproducing Kernel Particle Method (RKPM) representation, which enables the construction of reduced-order skinning weights by solving a generalized eigensystem on the Hessian matrix of the elastic energy. We demonstrate that this formulation not only leads to a 40x training speedup compared with the per-shape optimization of neural fields, but also achieves lower simulation error when evaluated against the converged results of finite element method. We show our simulation results on a wide variety of objects in different representations including meshes and Gaussian splats, as well as the application of our method in the downstream task of robot simulation.
Lyra 2.0: Explorable Generative 3D Worlds
Apr 14, 2026Recent advances in video generation enable a new paradigm for 3D scene creation: generating camera-controlled videos that simulate scene walkthroughs, then lifting them to 3D via feed-forward reconstruction techniques. This generative reconstruction approach combines the visual fidelity and creative capacity of video models with 3D outputs ready for real-time rendering and simulation. Scaling to large, complex environments requires 3D-consistent video generation over long camera trajectories with large viewpoint changes and location revisits, a setting where current video models degrade quickly. Existing methods for long-horizon generation are fundamentally limited by two forms of degradation: spatial forgetting and temporal drifting. As exploration proceeds, previously observed regions fall outside the model's temporal context, forcing the model to hallucinate structures when revisited. Meanwhile, autoregressive generation accumulates small synthesis errors over time, gradually distorting scene appearance and geometry. We present Lyra 2.0, a framework for generating persistent, explorable 3D worlds at scale. To address spatial forgetting, we maintain per-frame 3D geometry and use it solely for information routing -- retrieving relevant past frames and establishing dense correspondences with the target viewpoints -- while relying on the generative prior for appearance synthesis. To address temporal drifting, we train with self-augmented histories that expose the model to its own degraded outputs, teaching it to correct drift rather than propagate it. Together, these enable substantially longer and 3D-consistent video trajectories, which we leverage to fine-tune feed-forward reconstruction models that reliably recover high-quality 3D scenes.
Learning Convex Decomposition via Feature Fields
Mar 10, 2026This work proposes a new formulation to the long-standing problem of convex decomposition through learning feature fields, enabling the first feed-forward model for open-world convex decomposition. Our method produces high-quality decompositions of 3D shapes into a union of convex bodies, which are essential to accelerate collision detection in physical simulation, amongst many other applications. The key insight is to adopt a feature learning approach and learn a continuous feature field that can later be clustered to yield a good convex decomposition via our self-supervised, purely-geometric objective derived from the classical definition of convexity. Our formulation can be used for single shape optimization, but more importantly, feature prediction unlocks scalable, self-supervised learning on large datasets resulting in the first learned open-world model for convex decomposition. Experiments show that our decompositions are higher-quality than alternatives and generalize across open-world objects as well as across representations to meshes, CAD models, and even Gaussian splats. https://research.nvidia.com/labs/sil/projects/learning-convex-decomp/
Stochastic Preconditioning for Neural Field Optimization
May 26, 2025Neural fields are a highly effective representation across visual computing. This work observes that fitting these fields is greatly improved by incorporating spatial stochasticity during training, and that this simple technique can replace or even outperform custom-designed hierarchies and frequency space constructions. The approach is formalized as implicitly operating on a blurred version of the field, evaluated in-expectation by sampling with Gaussian-distributed offsets. Querying the blurred field during optimization greatly improves convergence and robustness, akin to the role of preconditioners in numerical linear algebra. This implicit, sampling-based perspective fits naturally into the neural field paradigm, comes at no additional cost, and is extremely simple to implement. We describe the basic theory of this technique, including details such as handling boundary conditions, and extending to a spatially-varying blur. Experiments demonstrate this approach on representations including coordinate MLPs, neural hashgrids, triplanes, and more, across tasks including surface reconstruction and radiance fields. In settings where custom-designed hierarchies have already been developed, stochastic preconditioning nearly matches or improves their performance with a simple and unified approach; in settings without existing hierarchies it provides an immediate boost to quality and robustness.
PARTFIELD: Learning 3D Feature Fields for Part Segmentation and Beyond
Apr 15, 2025We propose PartField, a feedforward approach for learning part-based 3D features, which captures the general concept of parts and their hierarchy without relying on predefined templates or text-based names, and can be applied to open-world 3D shapes across various modalities. PartField requires only a 3D feedforward pass at inference time, significantly improving runtime and robustness compared to prior approaches. Our model is trained by distilling 2D and 3D part proposals from a mix of labeled datasets and image segmentations on large unsupervised datasets, via a contrastive learning formulation. It produces a continuous feature field which can be clustered to yield a hierarchical part decomposition. Comparisons show that PartField is up to 20% more accurate and often orders of magnitude faster than other recent class-agnostic part-segmentation methods. Beyond single-shape part decomposition, consistency in the learned field emerges across shapes, enabling tasks such as co-segmentation and correspondence, which we demonstrate in several applications of these general-purpose, hierarchical, and consistent 3D feature fields. Check our Webpage! https://research.nvidia.com/labs/toronto-ai/partfield-release/
Neurally Integrated Finite Elements for Differentiable Elasticity on Evolving Domains
Oct 12, 2024



We present an elastic simulator for domains defined as evolving implicit functions, which is efficient, robust, and differentiable with respect to both shape and material. This simulator is motivated by applications in 3D reconstruction: it is increasingly effective to recover geometry from observed images as implicit functions, but physical applications require accurately simulating and optimizing-for the behavior of such shapes under deformation, which has remained challenging. Our key technical innovation is to train a small neural network to fit quadrature points for robust numerical integration on implicit grid cells. When coupled with a Mixed Finite Element formulation, this yields a smooth, fully differentiable simulation model connecting the evolution of the underlying implicit surface to its elastic response. We demonstrate the efficacy of our approach on forward simulation of implicits, direct simulation of 3D shapes during editing, and novel physics-based shape and topology optimizations in conjunction with differentiable rendering.
SpaceMesh: A Continuous Representation for Learning Manifold Surface Meshes
Sep 30, 2024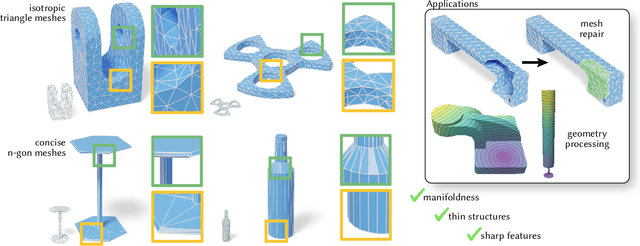
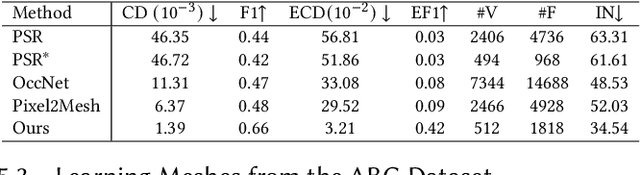
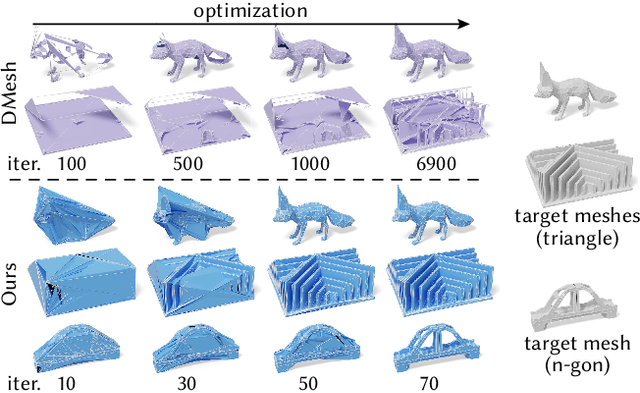

Meshes are ubiquitous in visual computing and simulation, yet most existing machine learning techniques represent meshes only indirectly, e.g. as the level set of a scalar field or deformation of a template, or as a disordered triangle soup lacking local structure. This work presents a scheme to directly generate manifold, polygonal meshes of complex connectivity as the output of a neural network. Our key innovation is to define a continuous latent connectivity space at each mesh vertex, which implies the discrete mesh. In particular, our vertex embeddings generate cyclic neighbor relationships in a halfedge mesh representation, which gives a guarantee of edge-manifoldness and the ability to represent general polygonal meshes. This representation is well-suited to machine learning and stochastic optimization, without restriction on connectivity or topology. We first explore the basic properties of this representation, then use it to fit distributions of meshes from large datasets. The resulting models generate diverse meshes with tessellation structure learned from the dataset population, with concise details and high-quality mesh elements. In applications, this approach not only yields high-quality outputs from generative models, but also enables directly learning challenging geometry processing tasks such as mesh repair.
3D Gaussian Ray Tracing: Fast Tracing of Particle Scenes
Jul 10, 2024



Particle-based representations of radiance fields such as 3D Gaussian Splatting have found great success for reconstructing and re-rendering of complex scenes. Most existing methods render particles via rasterization, projecting them to screen space tiles for processing in a sorted order. This work instead considers ray tracing the particles, building a bounding volume hierarchy and casting a ray for each pixel using high-performance GPU ray tracing hardware. To efficiently handle large numbers of semi-transparent particles, we describe a specialized rendering algorithm which encapsulates particles with bounding meshes to leverage fast ray-triangle intersections, and shades batches of intersections in depth-order. The benefits of ray tracing are well-known in computer graphics: processing incoherent rays for secondary lighting effects such as shadows and reflections, rendering from highly-distorted cameras common in robotics, stochastically sampling rays, and more. With our renderer, this flexibility comes at little cost compared to rasterization. Experiments demonstrate the speed and accuracy of our approach, as well as several applications in computer graphics and vision. We further propose related improvements to the basic Gaussian representation, including a simple use of generalized kernel functions which significantly reduces particle hit counts.
Adaptive Shells for Efficient Neural Radiance Field Rendering
Nov 16, 2023



Neural radiance fields achieve unprecedented quality for novel view synthesis, but their volumetric formulation remains expensive, requiring a huge number of samples to render high-resolution images. Volumetric encodings are essential to represent fuzzy geometry such as foliage and hair, and they are well-suited for stochastic optimization. Yet, many scenes ultimately consist largely of solid surfaces which can be accurately rendered by a single sample per pixel. Based on this insight, we propose a neural radiance formulation that smoothly transitions between volumetric- and surface-based rendering, greatly accelerating rendering speed and even improving visual fidelity. Our method constructs an explicit mesh envelope which spatially bounds a neural volumetric representation. In solid regions, the envelope nearly converges to a surface and can often be rendered with a single sample. To this end, we generalize the NeuS formulation with a learned spatially-varying kernel size which encodes the spread of the density, fitting a wide kernel to volume-like regions and a tight kernel to surface-like regions. We then extract an explicit mesh of a narrow band around the surface, with width determined by the kernel size, and fine-tune the radiance field within this band. At inference time, we cast rays against the mesh and evaluate the radiance field only within the enclosed region, greatly reducing the number of samples required. Experiments show that our approach enables efficient rendering at very high fidelity. We also demonstrate that the extracted envelope enables downstream applications such as animation and simulation.
TexFusion: Synthesizing 3D Textures with Text-Guided Image Diffusion Models
Oct 20, 2023

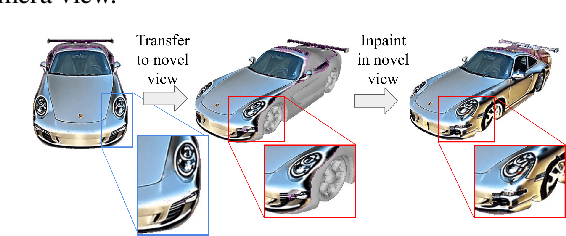

We present TexFusion (Texture Diffusion), a new method to synthesize textures for given 3D geometries, using large-scale text-guided image diffusion models. In contrast to recent works that leverage 2D text-to-image diffusion models to distill 3D objects using a slow and fragile optimization process, TexFusion introduces a new 3D-consistent generation technique specifically designed for texture synthesis that employs regular diffusion model sampling on different 2D rendered views. Specifically, we leverage latent diffusion models, apply the diffusion model's denoiser on a set of 2D renders of the 3D object, and aggregate the different denoising predictions on a shared latent texture map. Final output RGB textures are produced by optimizing an intermediate neural color field on the decodings of 2D renders of the latent texture. We thoroughly validate TexFusion and show that we can efficiently generate diverse, high quality and globally coherent textures. We achieve state-of-the-art text-guided texture synthesis performance using only image diffusion models, while avoiding the pitfalls of previous distillation-based methods. The text-conditioning offers detailed control and we also do not rely on any ground truth 3D textures for training. This makes our method versatile and applicable to a broad range of geometry and texture types. We hope that TexFusion will advance AI-based texturing of 3D assets for applications in virtual reality, game design, simulation, and more.
* Videos and more results on https://research.nvidia.com/labs/toronto-ai/texfusion/