 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian See, Gaussian Do: Semantic 3D Motion Transfer from Multiview Video
Nov 18, 2025We present Gaussian See, Gaussian Do, a novel approach for semantic 3D motion transfer from multiview video. Our method enables rig-free, cross-category motion transfer between objects with semantically meaningful correspondence. Building on implicit motion transfer techniques, we extract motion embeddings from source videos via condition inversion, apply them to rendered frames of static target shapes, and use the resulting videos to supervise dynamic 3D Gaussian Splatting reconstruction. Our approach introduces an anchor-based view-aware motion embedding mechanism, ensuring cross-view consistency and accelerating convergence, along with a robust 4D reconstruction pipeline that consolidates noisy supervision videos. We establish the first benchmark for semantic 3D motion transfer and demonstrate superior motion fidelity and structural consistency compared to adapted baselines. Code and data for this paper available at https://gsgd-motiontransfer.github.io/
3D Gaussian Ray Tracing: Fast Tracing of Particle Scenes
Jul 10, 2024



Particle-based representations of radiance fields such as 3D Gaussian Splatting have found great success for reconstructing and re-rendering of complex scenes. Most existing methods render particles via rasterization, projecting them to screen space tiles for processing in a sorted order. This work instead considers ray tracing the particles, building a bounding volume hierarchy and casting a ray for each pixel using high-performance GPU ray tracing hardware. To efficiently handle large numbers of semi-transparent particles, we describe a specialized rendering algorithm which encapsulates particles with bounding meshes to leverage fast ray-triangle intersections, and shades batches of intersections in depth-order. The benefits of ray tracing are well-known in computer graphics: processing incoherent rays for secondary lighting effects such as shadows and reflections, rendering from highly-distorted cameras common in robotics, stochastically sampling rays, and more. With our renderer, this flexibility comes at little cost compared to rasterization. Experiments demonstrate the speed and accuracy of our approach, as well as several applications in computer graphics and vision. We further propose related improvements to the basic Gaussian representation, including a simple use of generalized kernel functions which significantly reduces particle hit counts.
SKED: Sketch-guided Text-based 3D Editing
Mar 19, 2023



Text-to-image diffusion models are gradually introduced into computer graphics, recently enabling the development of Text-to-3D pipelines in an open domain. However, for interactive editing purposes, local manipulations of content through a simplistic textual interface can be arduous. Incorporating user guided sketches with Text-to-image pipelines offers users more intuitive control. Still, as state-of-the-art Text-to-3D pipelines rely on optimizing Neural Radiance Fields (NeRF) through gradients from arbitrary rendering views, conditioning on sketches is not straightforward. In this paper, we present SKED, a technique for editing 3D shapes represented by NeRFs. Our technique utilizes as few as two guiding sketches from different views to alter an existing neural field. The edited region respects the prompt semantics through a pre-trained diffusion model. To ensure the generated output adheres to the provided sketches, we propose novel loss functions to generate the desired edits while preserving the density and radiance of the base instance. We demonstrate the effectiveness of our proposed method through several qualitative and quantitative experiments.
SPAGHETTI: Editing Implicit Shapes Through Part Aware Generation
Jan 31, 2022
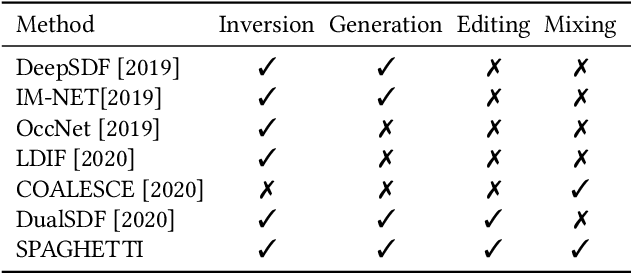
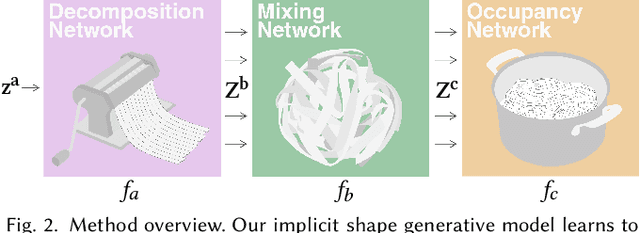
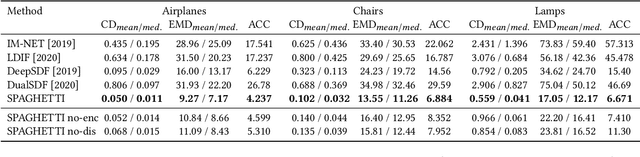
Neural implicit fields are quickly emerging as an attractive representation for learning based techniques. However, adopting them for 3D shape modeling and editing is challenging. We introduce a method for $\mathbf{E}$diting $\mathbf{I}$mplicit $\mathbf{S}$hapes $\mathbf{T}$hrough $\mathbf{P}$art $\mathbf{A}$ware $\mathbf{G}$enera$\mathbf{T}$ion, permuted in short as SPAGHETTI. Our architecture allows for manipulation of implicit shapes by means of transforming, interpolating and combining shape segments together, without requiring explicit part supervision. SPAGHETTI disentangles shape part representation into extrinsic and intrinsic geometric information. This characteristic enables a generative framework with part-level control. The modeling capabilities of SPAGHETTI are demonstrated using an interactive graphical interface, where users can directly edit neural implicit shapes.
Mesh Draping: Parametrization-Free Neural Mesh Transfer
Oct 11, 2021
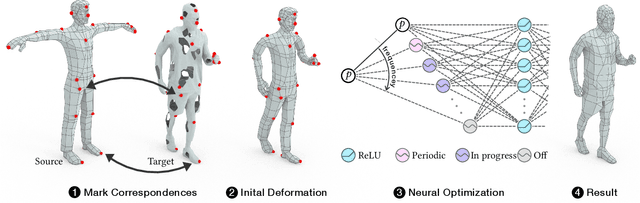


Despite recent advances in geometric modeling, 3D mesh modeling still involves a considerable amount of manual labor by experts. In this paper, we introduce Mesh Draping: a neural method for transferring existing mesh structure from one shape to another. The method drapes the source mesh over the target geometry and at the same time seeks to preserve the carefully designed characteristics of the source mesh. At its core, our method deforms the source mesh using progressive positional encoding. We show that by leveraging gradually increasing frequencies to guide the neural optimization, we are able to achieve stable and high quality mesh transfer. Our approach is simple and requires little user guidance, compared to contemporary surface mapping techniques which rely on parametrization or careful manual tuning. Most importantly, Mesh Draping is a parameterization-free method, and thus applicable to a variety of target shape representations, including point clouds, polygon soups, and non-manifold meshes. We demonstrate that the transferred meshing remains faithful to the source mesh design characteristics, and at the same time fits the target geometry well.
Progressive Encoding for Neural Optimization
Apr 19, 2021



We introduce a Progressive Positional Encoding (PPE) layer, which gradually exposes signals with increasing frequencies throughout the neural optimization. In this paper, we show the competence of the PPE layer for mesh transfer and its advantages compared to contemporary surface mapping techniques. Our approach is simple and requires little user guidance. Most importantly, our technique is a parameterization-free method, and thus applicable to a variety of target shape representations, including point clouds, polygon soups, and non-manifold meshes. We demonstrate that the transferred meshing remains faithful to the source mesh design characteristics, and at the same time fits the target geometry well.
Learning Multimodal Affinities for Textual Editing in Images
Mar 18, 2021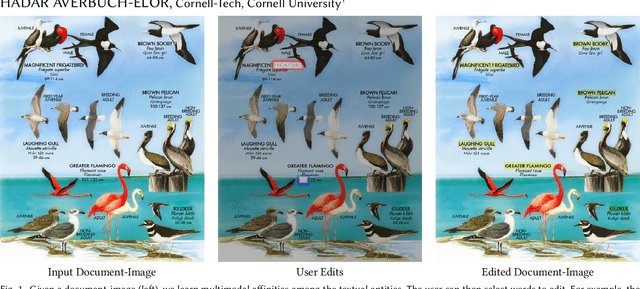
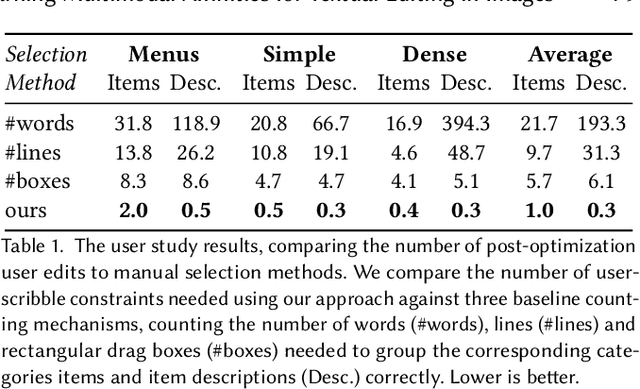
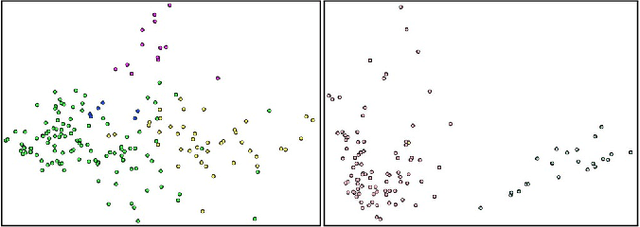
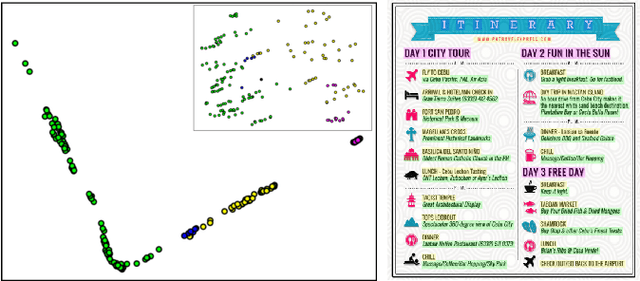
Nowadays, as cameras are rapidly adopted in our daily routine, images of documents are becoming both abundant and prevalent. Unlike natural images that capture physical objects, document-images contain a significant amount of text with critical semantics and complicated layouts. In this work, we devise a generic unsupervised technique to learn multimodal affinities between textual entities in a document-image, considering their visual style, the content of their underlying text and their geometric context within the image. We then use these learned affinities to automatically cluster the textual entities in the image into different semantic groups. The core of our approach is a deep optimization scheme dedicated for an image provided by the user that detects and leverages reliable pairwise connections in the multimodal representation of the textual elements in order to properly learn the affinities. We show that our technique can operate on highly varying images spanning a wide range of documents and demonstrate its applicability for various editing operations manipulating the content, appearance and geometry of the image.
Can You Read Me Now? Content Aware Rectification using Angle Supervision
Aug 05, 2020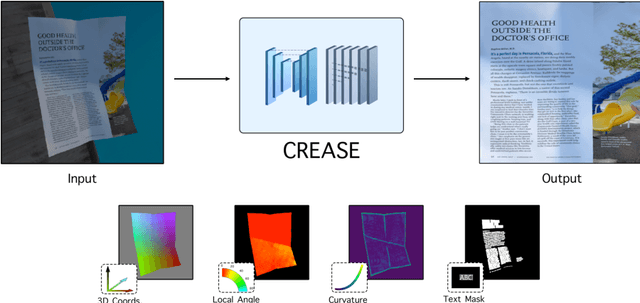

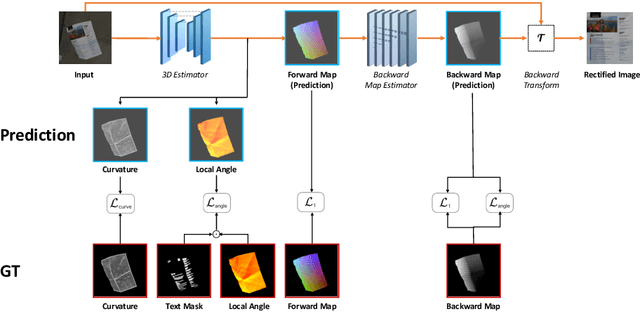

The ubiquity of smartphone cameras has led to more and more documents being captured by cameras rather than scanned. Unlike flatbed scanners, photographed documents are often folded and crumpled, resulting in large local variance in text structure. The problem of document rectification is fundamental to the Optical Character Recognition (OCR) process on documents, and its ability to overcome geometric distortions significantly affects recognition accuracy. Despite the great progress in recent OCR systems, most still rely on a pre-process that ensures the text lines are straight and axis aligned. Recent works have tackled the problem of rectifying document images taken in-the-wild using various supervision signals and alignment means. However, they focused on global features that can be extracted from the document's boundaries, ignoring various signals that could be obtained from the document's content. We present CREASE: Content Aware Rectification using Angle Supervision, the first learned method for document rectification that relies on the document's content, the location of the words and specifically their orientation, as hints to assist in the rectification process. We utilize a novel pixel-wise angle regression approach and a curvature estimation side-task for optimizing our rectification model. Our method surpasses previous approaches in terms of OCR accuracy, geometric error and visual similarity.
READ: Recursive Autoencoders for Document Layout Generation
Oct 10, 2019

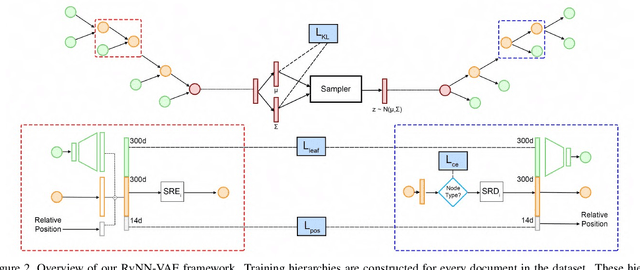
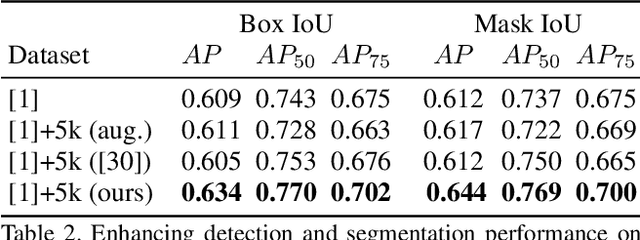
Layout is a fundamental component of any graphic design. Creating large varieties of plausible document layouts can be a tedious task, requiring numerous constraints to be satisfied, including local ones relating different semantic elements and global constraints on the general appearance and spacing. In this paper, we present a novel framework, coined READ, for REcursive Autoencoders for Document layout generation, to generate plausible 2D layouts of documents in large quantities and varieties. First, we devise an exploratory recursive method to extract a structural decomposition of a single document. Leveraging a dataset of documents annotated with labeled bounding boxes, our recursive neural network learns to map the structural representation, given in the form of a simple hierarchy, to a compact code, the space of which is approximated by a Gaussian distribution. Novel hierarchies can be sampled from this space, obtaining new document layouts. Moreover, we introduce a combinatorial metric to measure structural similarity among document layouts. We deploy it to show that our method is able to generate highly variable and realistic layouts. We further demonstrate the utility of our generated layouts in the context of standard detection tasks on documents, showing that detection performance improves when the training data is augmented with generated documents whose layouts are produced by READ.